
ChatGPTとの連携を考えてみる①

はじめに
ChatGPTの話題が世の中に溢れています。開発者を支援する機能も多く、コード生成やコード解説、リファクタリング、メソッド名の候補など、参考情報とするのに、とても有用と感じました。一方で気づきにくい誤りが多い点に関しては、懸念も感じます。
個人での活用だけではなく、自社サービスやプロダクトと連携したユースケースも模索されていくことと思います。まずは課題を俯瞰しつつ、連携のあり方や留意したい点について考えてみました。
現時点での課題
プロンプトに関して
出力文の商用利用は可能だが、プロンプト(入力文)のテキストはOpen AI社が制限なく利用できる。
プロンプトのテキストが、別ユーザーへの出力に利用される可能性があるため、機密情報や著作権侵害となる情報を含めるのは避けるべき。社内利用を制限する企業も出てきている。
※ChatGPT APIの公開に伴って、APIから送信されたプロンプトについては学習などに利用されないこととなった。
出力文に関して
出力文に著作権を含む情報や機密情報が含まれる可能性がある。
出力文に誤りが散見される。人間のフィードバックによる調整を前提としている。誤りが許容できないケースではファクトチェックが必要。
システムの更新などで出力文が変化する可能性がある。特定バージョンを選択したAPI実行も可能だが、利用期間が限定されている。
学習データに関して
2021年までのデータで事前学習している。そこに含まれない情報を出力に反映させるには、プロンプトに含めるなり、ファインチューニングによる調整(別費用)をするなどして、試行錯誤する必要がある。
※ChatGPT Pluginによって、Webアクセスした結果などを回答に加味できるようになる模様。
その他
SLAは作成中。アクセス集中する時間帯などで応答速度遅延やエラーになる場合がある。システム障害もあった。
上記を踏まえますと、現時点では試験的な連携となりそうですが、(社内利用に関しても、一定の配慮が必要と考えます)
大規模サービス向けと言われる専用インスタンスの利用や、Azure OpenAI Service上での利用により、課題のいくつかは解消されるかもしれません。
急速に変化している状況下のため、最新の利用規約は注視しておきたいですし、Open AI社以外のLLM(大規模言語モデル)の利用も視野に入れたいところです。(自前でLLMを構築できるFlexGenなどでの代替など)
連携のタイプ
ChatGPTは、テキスト生成の表現力の高さだけでなく、柔軟な対話力や、文字の現れ方の演出といった、チャットボットの総合的なUXによって、多くのユーザーに受け入れられたのだと思いますが、連携を考えた場合に、テキスト生成のみを利用するのか、対話まで含めて利用するのかで、連携のあり方が変わりそうです。ここでは2つのタイプに分類して考えてみました。
対話を利用しない
ユーザーとの対話を直接利用せず、何らかのイベントをトリガーにして、テキストデータを、翻訳・要約したり、プログラム言語や構造化データの変換、データ分析、ラベル付けや穴埋めなどのテキストの変換や分類といった、テキスト生成のみを利用する連携です。
こうした利用では、ChatGPTである必要性は低いため、別のLLMへの置き換えを検討できるかもしれません。また従来のAIシステムや自前実装での代替について吟味も必要でしょう。既存のデータ加工処理のバリエーションとして考えることもできそうですが、誤りの許容性(下書きやテンプレートとしての利用など)や、APIコストに留意すべきと考えます。
入出力するテキストは、一般に認知されたフォーマットであれば、独自のスキーマでも、プロンプトの加工技術であるプロンプトエンジニアリングによる配慮(Few-shot learning、Chain-of-Thoughtなど)によって、扱える可能性がありそうです。プロンプトにはトークン数の制限がありますが、マニュアルや仕様書などの外部リソースを含めた場合に、期待する動作となるのか、気になります。
また、入力するテキストは、ファイル全体の場合や、データベースの部分的なデータ(アンケートの備考欄など)、テキスト化した音声データなども対象となり得えます。GPT-4ではテキストだけでなく、画像も入力可能(マルチモーダル)になりました。
システム内に存在するデータの所在を確認してみたり、ネット上の多様な応用例を試してみると、アイディアが創発されそうです。
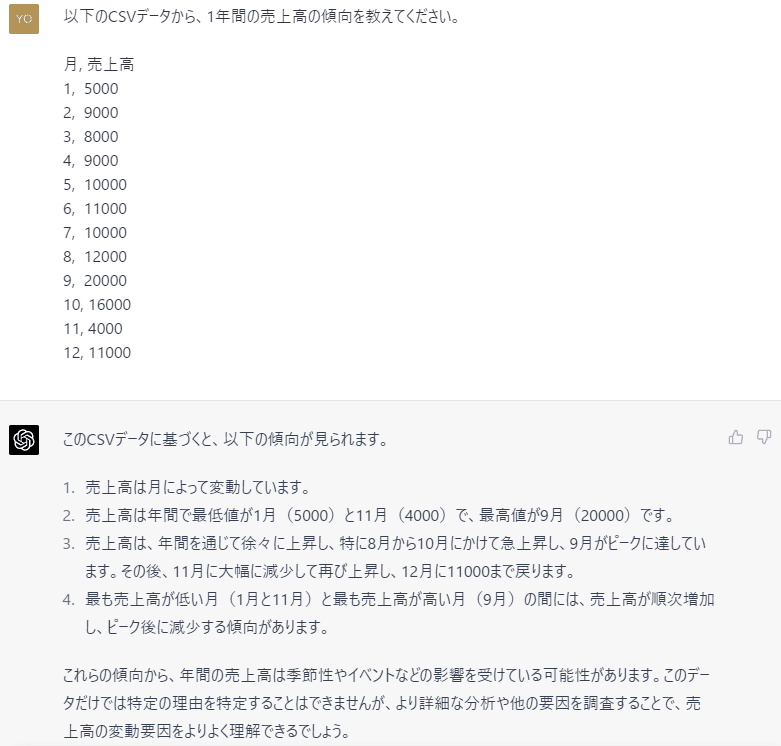
公式ページにもプロンプトのサンプルがあります。
対話を利用する
テキスト生成だけでなく、ユーザーとの対話も利用する連携です。この場合、対話に特化したチューニングがなされたChatGPTを利用したくなります。(UIについては、既存システムのUIを利用してChatGPTのAPIを実行する以外にも、ChatGPT自体のUIを利用して、ChatGPT PluginによりWebアクセスする連携も選択肢となりそうです。)
従来の対話システムの用語で言えば、ChatGPTは話題を限定しない非タスク志向型の対話システムと言えますが、既存のサービスやプロダクトとの連携では、ユーザーの指示に基づいて、特定のタスクを実行したいケースが多いと思いますので、そうしたタスク志向型の利用ができれば適用範囲が広がりそうです。
対話を利用する場合、一問一答(1ターン)とするのか、前回のやり取りを継続した複数ターンとするかによっても、体験の質が変わります。1ターンで、タスク実行に必要となる情報が抽出できない場合、従来のスロットフィリングのように、必須情報が埋まるまで質問を繰り返すことも、プロンプトへの指示だけで可能となりそうです。(情報抽出後、WebAPIの呼び出しやDBへのクエリー実行などを行う)
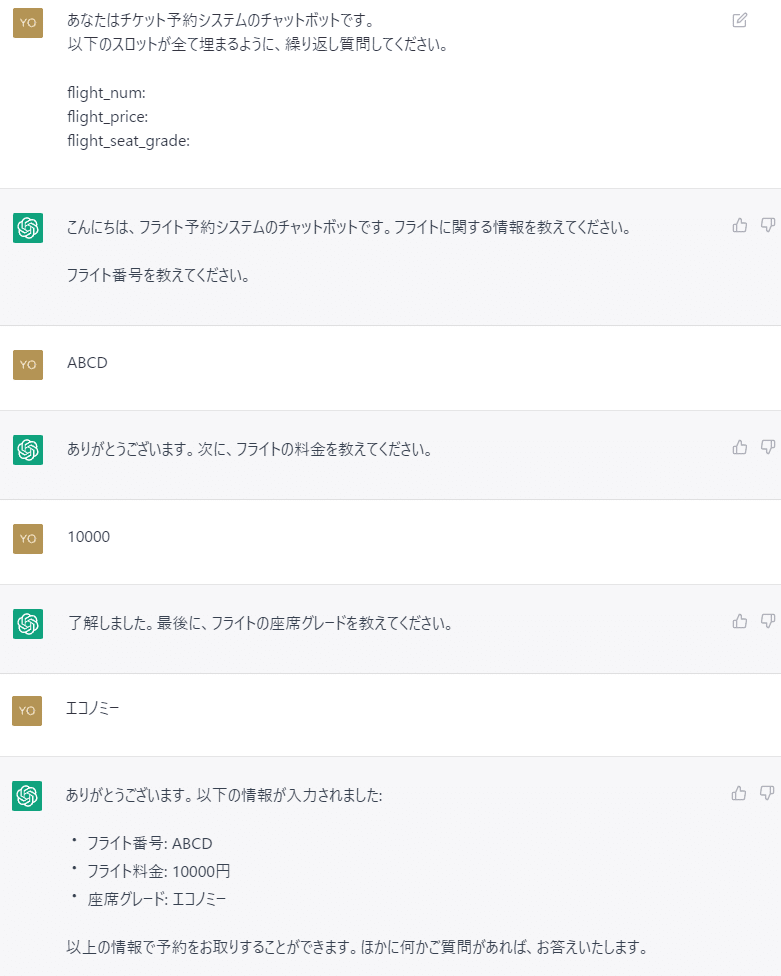
また、話題の脱線を許容せず、特定のドメインに限定したり(Closed Domain)、逸脱を検知して本流に戻す、といった対話の主導権の維持を制御できるのか(プロンプトインジェクション対策も含めて)が、連携の鍵になると考えます。
最後に
今回は連携のあり方や留意点について考えてみました。
次回は実例を交えて考えてみたいと思います。
備考
ChatGPTでは2022年以降のデータを扱えず、根拠や出典のリンク先提示もできないが、Perplexity AI社のPerplexity ASKでは、Open AI社のGPT-3のモデルにWeb検索結果を加味し、出典のリンク先を提示できる。ただしデモ版。(ChatGPT Pluginも選択肢となる)
外部リソースのドメイン知識追加には、LangChainやLlamaIndexといったライブラリも利用できる。(ChatGPT Pluginも選択肢となる)
LLMの周辺動向が活発。Microsoft社のPrometheus、Google社のBERT、Meta社のLLaMA、FlexGenなど。
この記事が気に入ったらサポートをしてみませんか?