
LLM登場までの深層学習の歴史を振り返ってみた[前編]

はじめに
みなさんこんにちは!
ワンキャリアでデータサイエンティストをしている長谷川です!企業イメージメーカーのリリース以来、2本目の投稿になります。
今回の記事では、LLM(Large Language Model:大規模言語モデル)登場に至るまでの深層学習の歴史について、前編・後編に分けて紹介します。
昨今、世間から脚光を浴びているLLMですが、ワンキャリアでも積極的に活用しています。「ONE CAREER」では「ESの達人」という新規サービスをリリースしたり(プレスリリース)、社内では Github Copilot を活用したり(プレスリリース)しています。そしてその活用範囲をより一層広げるために、社内メンバーの深層学習に関するリテラシーを上げていこうと考えました。
実際に社内メンバー向けに深層学習に関する資料を作ったところ、「わかりやすい」「勉強になった」等の声を多くもらえました。そこで、本記事では資料の一部を皆さんにも共有したいと思います。
深層学習についてざっくり把握したい、LLM登場の背景を知りたい方はぜひご一読ください。
わかりやすさを重視してまとめたので、技術の詳細には立ち入らず、噛み砕いた表現を用いて説明をしていきます。
そもそも、AIと機械学習、そして深層学習はどう違うのか?
深層学習の歴史を振り返る前に、まず、深層学習とAI、機械学習はそれぞれどう異なるのかを説明します。
結論から言うと、三者は包含関係にあり、AIの中に機械学習、機械学習の中に深層学習があるという関係性です。今回はAIを「人間のような知能を持ったコンピュータ」と広義に解釈しました。その中に機械学習と深層学習が含まれています。

では機械学習とは何か?
一般的には “データをもとに「機械」が自身で「学習」を行い、データの背景にあるルールやパターンを発見する手法” を指します。観測されたデータから帰納的に、機械が自動で発見するというのが特徴です。
帰納的に発見する方法は大きく分けて、教師あり学習・教師なし学習・強化学習の3つがあり、それらを整理したものが下記になります。(詳細については多くの記事があるため割愛します。)
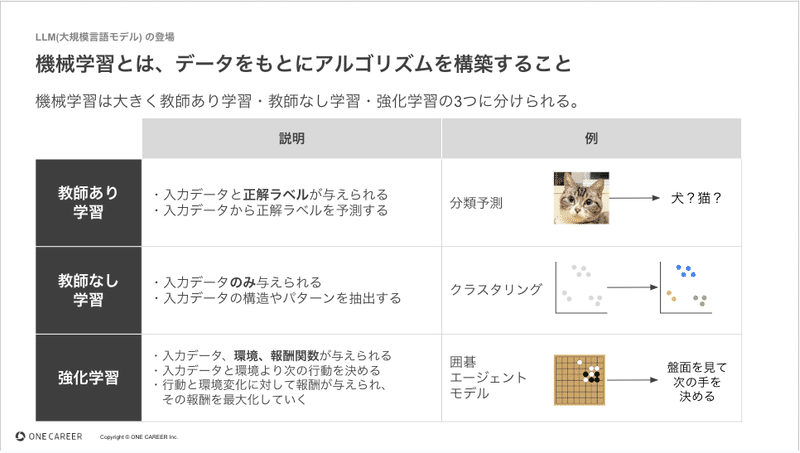
そして、深層学習とは何か?
今回は「人間の脳神経回路を模倣した構造を持つ機械学習」と定義しました。
具体的には、神経に入力された電気信号を変換し、次の神経へ伝達する機構を模しています。深層学習の計算処理は下記のようなイメージです。このイメージでは、0.8 と 0.7 という値を受け取った神経(入力層)が次の神経へ電気信号を伝達しています。その信号を受け取った神経(隠れ層・中間層)が電気信号を変換し(0.7 + 0.8 = 1.5)、次の神経(出力層)へ伝達しています。
この変換を幾重にも行う(層を深くする)ことで関数としての表現力が上がり、様々な問題を解くことができます。

深層学習時代が幕を開ける
ここからは、深層学習の歴史を振り返る上で重要な出来事をピックアップしていきます。CNN(Convolutional Neural Network:畳み込みニューラルネットワーク)から始まり、RNN(Recurrent Neural Network:回帰型ニューラルネットワーク)、GPT(Generative Pre-trained Transformer)という順で、前編では2014年のRNNの話までを記載しています。

まず、2012年に深層学習時代の幕開けとなる出来事が起こります。
ILSVRC(ImageNet Large Scale Visual Recognition Challenge、ホームページ)と呼ばれる画像認識の精度を競い合う大会で、深層学習を利用したトロント大学のモデルが他を寄せ付けないスコアを叩き出して優勝を果たしたのです。2011年の同大会のスコアを大幅に上回っていたことに加え今まであまり使用されていなかった深層学習を使用したという点でこの結果は大きな脚光を浴びました。この出来事をきっかけに深層学習の躍進が始まります。

時系列データに対応したモデルが登場
2012年に画像認識の領域で脚光を浴びた深層学習は、自然言語処理の領域においてもその真価を発揮します。それがRNNと呼ばれる深層学習モデルです。RNNは再帰的な構造を内部に持つモデルで、RNNやLSTM(Long Short Term Memory)などが該当します。2014年には、GRU(Gated Recurrent Unit)と呼ばれる軽量のモデルも登場しました。
RNN の再帰的な構造は次の通りです。まず各時刻ステップで入力データが入力層に与えられ、隠れ層のノードで計算が行われます。そして、隠れ層の出力を出力層に伝播しつつ、その値は次のステップにも渡され、再帰的な構造が形成されます。最終的に、最後の隠れ層から算出される出力を最終的な予測結果として用いることが多いです。この再帰構造は自然言語処理と相性がよく、多くのタスクで利用されることになります。例えば、下記の図では、「私は青い空が」という入力から「好き」という次の単語を予測するRNNを図示しています。過去の「私」という単語の出力を再帰的に活用し、最後の「好き」という単語を導いています。

このように、過去の入力を加味できるモデル構造は、統計的な自然言語処理とは一線を画すものであり、後に登場するGPTにも繋がっていきます。
おわりに
以上で前編は終了です。本記事では、CNNやRNNといった代表的なモデルの紹介をしてきました。後編ではいよいよChatGPTのベースとなるGPTが登場するのでお楽しみに。
▼ワンキャリアのエンジニア組織のことを知りたい方はまずこちら
▼カジュアル面談を希望の方はこちら

▼エンジニア求人票
この記事が気に入ったらサポートをしてみませんか?