記事一覧


https://arxiv.org/abs/2307.02472
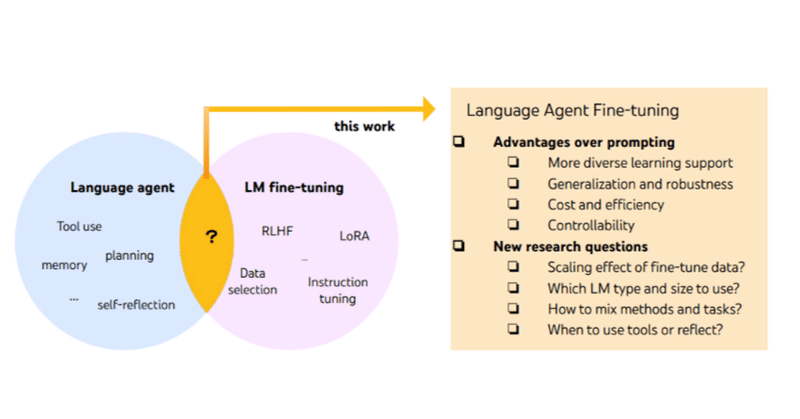
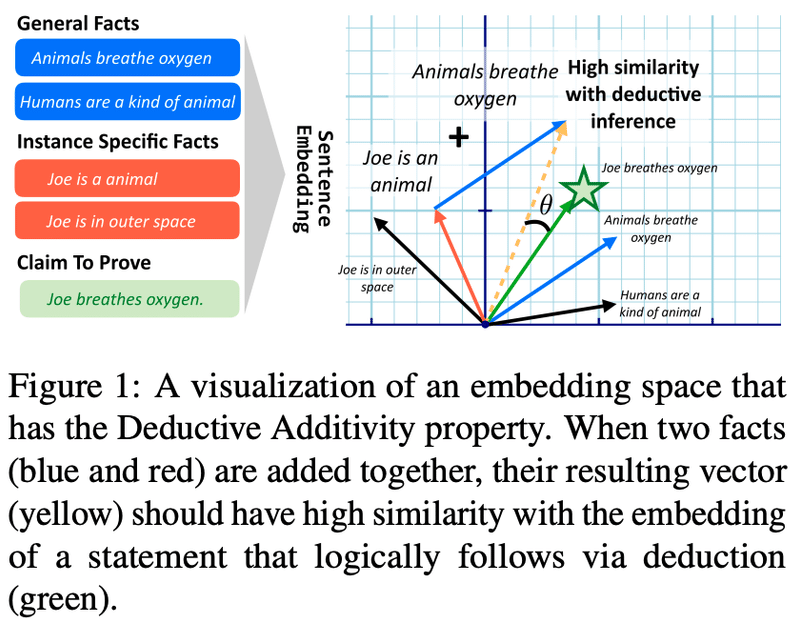
内容)埋め込み空間が演繹的加法性を示すか調査
仮説)前提文の埋め込み和は、結論の埋め込みに近い
提案)推論タイプ別性能を評価するために SSRC データセットを提案


@akeyhero (株式会社グロービス) +'23 - OpenAI の Embeddings API はイケてるのか、定量的に調べてみる (Qiita)
https://qiita.com/akeyhero/items/ce371bfed64399027c23
・Dense Retrieval 系の比較はこちらが参考になりそう
ABEJA - 外部データをRetrievalしてLLM活用する上での課題と対策案
https://tech-blog.abeja.asia/entry/retrieval-and-llm-20230703
・埋め込みベース検索の実験的まとめ記事
・未知語は TF-IDF, 微調整, 別モデルで対応
・忘却・知識衝突・別モデルの話で別記事が書けそう
Zhang+'23 - https://llavar.github.io/
LLaVA を文書画像で指示調整
LAION から 422K のテキスト画像を収集
テキスト画像の QA ペアを含む 16K の会話を生成
テキストベース VQA で LLaVA を大幅に凌駕
中川+'23 - 魅力的な技術アウトプットを出すために心がけている7つのこと (note)
https://note.com/shinyorke/n/n4daf30cbc653
① マウンティングをしない様、自己紹介を控えめにする。
② 聴衆・読者への期待値を宣言する。
③ 内輪ネタを極力回避する。
piyonakajima+'23 - チームにノリをもたらした時にいた「二人目に踊る人」の共通点
・共通点:サーバントリーダーシップを持つ
・注意:組織の成果物が特定の人になると危ない(実質的な推進者はリーダーであるべき)
https://twitter.com/fuuuuuta21/status/1672960863890993159
https://github.com/Azure-Samples/jp-azureopenai-samples
> Azure OpenAIを活用したアプリケーション実装のリファレンスを目的として、アプリのサンプル(リファレンスアーキテクチャ、サンプルコードとデプロイ手順)を無償提供しています。


キャリア選択における意思決定の構造を振り返る
はじめまして、 宮脇(@catshun_) と申します。この度 Algomatic inc. に機械学習エンジニアとして入社しました。
転職とともにキャリア相談を受ける回数も多くなりましたので、本記事では Algomatic の機械学習エンジニアとしての入社するに至った動機を入社エントリとして紹介いたします。
1. 自己紹介1.1. Algomatic 以前の経歴
大学時代は TohokuN


arxiv.org/abs/2308.16463
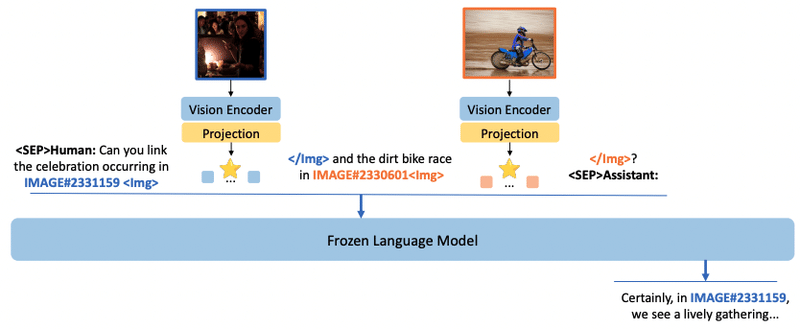
背景)既存 LVLM は複数画像間で一貫した対話を実現できない
提案)複数画像を考慮する指示追従モデル SparklesChat、GPT-4 を用いた評価ベンチマーク SparklesEval を提案


WizardLM: Instruction Tuning を行うための複雑で多様な指示データの自動構築
# Instruction Tuning # LLM # 日本語解説
WizardLM: Empowering Large Language Models to Follow Complex InstructionsCan Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Daxin
https://arxiv.org/abs/2307.02472
内容)埋め込み空間が演繹的加法性を示すか調査
仮説)前提文の埋め込み和は、結論の埋め込みに近い
提案)推論タイプ別性能を評価するために SSRC データセットを提案

arxiv: 2307.01163 (Chen+'23)
事前学習時 k 更新ごとに埋め込み層をリセット(active forgetting)することで収束が速くなり、低資源言語で XNLI, MLQA, XQuAD の精度が向上するそう

@akeyhero (株式会社グロービス) +'23 - OpenAI の Embeddings API はイケてるのか、定量的に調べてみる (Qiita)
https://qiita.com/akeyhero/items/ce371bfed64399027c23
・Dense Retrieval 系の比較はこちらが参考になりそう
ABEJA - 外部データをRetrievalしてLLM活用する上での課題と対策案
https://tech-blog.abeja.asia/entry/retrieval-and-llm-20230703
・埋め込みベース検索の実験的まとめ記事
・未知語は TF-IDF, 微調整, 別モデルで対応
・忘却・知識衝突・別モデルの話で別記事が書けそう
Zhang+'23 - https://llavar.github.io/
LLaVA を文書画像で指示調整
LAION から 422K のテキスト画像を収集
テキスト画像の QA ペアを含む 16K の会話を生成
テキストベース VQA で LLaVA を大幅に凌駕
中川+'23 - 魅力的な技術アウトプットを出すために心がけている7つのこと (note)
https://note.com/shinyorke/n/n4daf30cbc653
① マウンティングをしない様、自己紹介を控えめにする。
② 聴衆・読者への期待値を宣言する。
③ 内輪ネタを極力回避する。
piyonakajima+'23 - チームにノリをもたらした時にいた「二人目に踊る人」の共通点
・共通点:サーバントリーダーシップを持つ
・注意:組織の成果物が特定の人になると危ない(実質的な推進者はリーダーであるべき)
https://twitter.com/fuuuuuta21/status/1672960863890993159
https://github.com/Azure-Samples/jp-azureopenai-samples
> Azure OpenAIを活用したアプリケーション実装のリファレンスを目的として、アプリのサンプル(リファレンスアーキテクチャ、サンプルコードとデプロイ手順)を無償提供しています。