「PDF」というデータと向き合ってみる

こんにちは!出戻りガツオ🐟です!
と゛お゛し゛て゛テ゛ータか゛せ゛ん゛ふ゛PDFて゛し゛か゛残って゛ないんた゛よ゛お゛お゛お゛! pic.twitter.com/u1ABF0ViC1
— 出戻りガツオ🐟 (@DemodoriGatsuo) October 3, 2022
お仕事の中で、データ貰って少し編集して配布するっていうラクショーな仕事が来たのですが、なぜかパワポだったので、無駄に長くなりました・・・。
そもそも「PDF」を使う前提や、「データとして上手く活用するにはどうしたらいいのか」、改めて見てみたいと思います!!
そもそもPDFとは
天下の富士通様のデータを遠慮なく引用します。
PDFは、「Portable Document Format」の略で、データを実際に紙に印刷したときの状態を、そのまま保存することができるファイル形式です。どんな環境のパソコンで開いても、同じように見ることができる、「電子的な紙」なのです。
通常、WordやExcelといったアプリケーションソフトで作成したデータは、同じソフトを持っていないと開くことができません。データを相手に送っても、見てもらえないこともあるのです。また、作成したパソコンとは別のパソコンで開いた場合には、フォントが置き換わってしまったり、レイアウトが崩れてしまったりすることもあります。ところがPDFなら、相手がどんな端末でも、情報をそのまま共有できるのです。
そのため、最近ではパソコンなどのマニュアルなどにもPDFが利用されています。マニュアルを紙で作成すると、紙代や印刷代などさまざまなコストがかかりますが、PDFなら紙のコストもかかりません。ユーザーとしても、紙の管理がなくなり、必要な時にいつでも取り出すことができます。
さらに、PDFは文字情報を持っているため、キーワードを使って中身を検索することもできます。紙のマニュアルでページをめくりながら探すよりも、知りたい情報のあるページが見つけやすいのです。
「紙」に近しいことを追求したデータのようですね。
ですが私は、取得する方法や取得先によって、データとしての属性が異なるように感じます。
ちょっとサマってみました。
PDFの豆知識 by 出戻りガツオ🐟

資料は興味があったらご自由に。内容に齟齬があったら、ごめんなさい🙇
ご自由に使いいただいて構いませんよ!
ここから「PDF」の属性を深堀します!
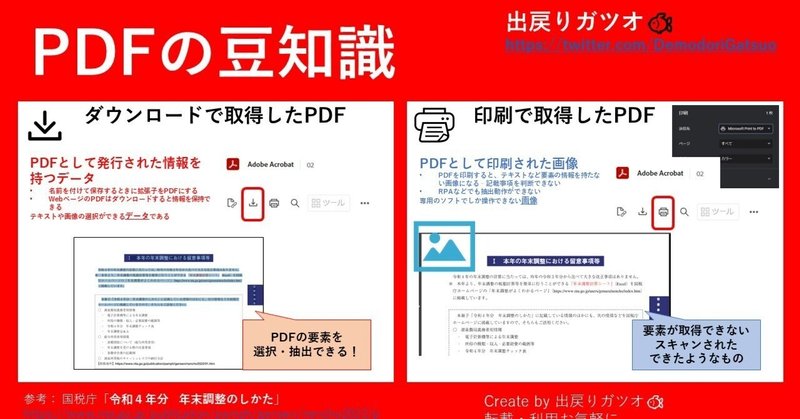
ダウンロードで取得したPDF
私はマウスで「データが直接選択できることが一番わかりやすいポイント」かなって思ってます。

「PDFとして発行された情報を持つデータ」といえます。
名前を付けて保存するときに拡張子をPDFにする
WebページのPDFはダウンロードすると情報を保持できる
テキストや画像の選択ができるデータである
こういったことができるとRPAやプログラミングでOCRを使わなくても一定の操作が可能です!
これに対し、

拡張子でこそ「.pdf」ですが「印刷された画像」ですね。
プリンタでSCANしたりすると漏れなくこうなります。
PDFを印刷すると、テキストなど要素の情報を持たない画像になる – 記載事項を判断できない
RPAなどでも抽出動作ができない
Adobe Illustrator | グラフィックデザインソフトなど、特殊なソフトではないと操作不可能。デメリットが多いです。
「OCRで何とか!?」って検証は、だいぶ前にしましたが最近はしてないです💦だいぶ前の記事ですが「Google Apps Scriptでのチャレンジした」こともありました。
なんにせよ既に持っている情報がそのまま活用できれば、それに越したことはないです。
実際にその情報活用について、これからフォーカスしていきますね!
※前者の「マウスでテキストを選択できる」と表現しているPDFを「PDFデータ」として表記を統一させていただきます🙇
「PDFデータ」であればこんなことが出来る!
Power Automate for desktopのメニューに注目👀✨
ITの力で何ができるのか、さっそく発見するには「RPAがうってつけ」です!ここでPower Automate for desktopのPDFメニューを見てみましょう。

PDFからテキストを抽出
PDFからテーブルを抽出する
PDFから画像を抽出します
新しいPDFファイルへのPDFファイルページの抽出
PDFファイルを統合
詳細はlearnに譲ります。パット見ても便利な技が色々あります。
Pythonやプログラミング言語を使う場合でも、このようなアクション中心になりますね。
Pythonの場合は?🐍
昨日のnoteの記事「かーでぃさんのハジメの一歩会の宿題をPyScript(Python)とGoogle Apps Scriptの合わせ技でドヤ顔してみる」で紹介したみやさかしんや@Python/DX/エンジニア(@miyashin_prg)さんのサマリが完璧すぎるので、Twitter引用させていただきます🙇
普段、PDFを扱う方へ😊✨ pic.twitter.com/Rh17agatwV
— みやさかしんや@Python/DX/エンジニア (@miyashin_prg) September 26, 2022
「テキストの抽出」や「データテーブルの抽出」「画像の取得」などなど、効率化の種があります✨
早速これから検証してみましょう!
テキストの抽出をPower Automate for desktopとPythonで試してみますか。
テキストの抽出
参考にするファイルは公的な文書で。
国税庁「令和4年分 年末調整のしかた」 ページ3
https://www.nta.go.jp/publication/pamph/gensen/nencho2022/pdf/02.pdf
でやってみます。
Power Automate for desktop
「ファイルダイアログで選択したPDFデータのテキストデータをテキストファイル(.txt)」にアウトプットするものです。

Display.SelectFileDialog.SelectFile Title: $'''PDFファイルを選択してください''' FileFilter: $'''*.pdf''' IsTopMost: True CheckIfFileExists: True SelectedFile=> SelectedFile ButtonPressed=> ButtonPressed
Pdf.ExtractTextFromPDF.ExtractText PDFFile: SelectedFile DetectLayout: False ExtractedText=> ExtractedPDFText
File.WriteText File: $'''C:\\PowerAutomate\\PDF\\result.txt''' TextToWrite: ExtractedPDFText AppendNewLine: True IfFileExists: File.IfFileExists.Overwrite Encoding: File.FileEncoding.DefaultEncoding
Display.ShowMessageDialog.ShowMessage Title: $'''Complete''' Message: $'''PDFからテキスト抽出が完了しました''' Icon: Display.Icon.Information Buttons: Display.Buttons.OK DefaultButton: Display.DefaultButton.Button1 IsTopMost: True ButtonPressed=> ButtonPressed2出力先は「C:\\PowerAutomate\\PDF\\result.txt」です。別に隠すこともないので隠しませんでしたw
PDFデータを都度開き、テキストを選択、コピー&ペーストという作業。
大変じゃないですけど怠いです。しかもカーソル合わせづらかったりするので不快。
こういう活用ができれば、「ファイルの内容による命名規則に沿って自動リネームなど、中身を見てできますね」。
また「正規表現を使ってほしいデータだけ抽出し、Excelに転記する」など活用の道が見えてきます。
Python
様々なライブラリがありますが「pdfminer.six」を使います!
とりあえずPower Automate for desktopっぽい操作をコードで書きました。
標準インストールのライブラリではないため、インストールが必要です。
pip install pdfminer.sixそれでPythonのコード🐍
from pdfminer.high_level import extract_text
from tkinter import filedialog
from tkinter import messagebox
def main():
#%% filedialog
typ = [('PDFファイル','*.pdf')]
dir = 'C:\\'
pdf_path = filedialog.askopenfilename(filetypes = typ, initialdir = dir)
#%% PDF read
pdf_text = extract_text(pdf_path)
#%% output txt
output_text = "C:\\Python\\pdfminer_six_demo\\result.txt"
with open(output_text, 'w', encoding='UTF-8', newline='\n') as f:
f.write(pdf_text)
messagebox.showinfo('Complete', 'Complete PDF READ')
return
if __name__ == "__main__":
main()ほかライブラリとの組み合わせで高速処理が可能!
ファイル数が多いと特に力を発揮します。大量にデータをさばくにはうってつけ!
しかしながらPower Automate for desktopなら作成時間3分ほど!
作成が手軽という点では本当に凄いです!
ドラッグアンドドロップの繰り返しですからね🐟✨
プログラミング言語とRPAは、ケースに合わせて選んでいくことが適切かもしれませんね。エディタ開いて書き始めるぞ!というのも少し体力がいるのでそれがないRPAは嬉しいです。
本日はここまで!
「画像の抽出」や「データテーブルの抽出」は、また別の日に!
いろいろ使いこなして業務効率化をしていきたいと思います!
お読みいただきありがとうございました!!
最近の記事の紹介
最後に!!!
いつもお読みいただきありがとうございます!
ITを使って仕事を楽しくする一助になりたいと思ってますので
お読みいただいた方はぜひTwitterもフォローしてください!
Power PlatformやPythonやExcel、Google Apps Scriptなどなど雑多につぶやきます。よなよなエールが大好きです🍺
リプ、いいね👍、RT大歓迎です!
強く求めてます🐟😂🐟
業務改善フレンズ大歓迎!!切磋琢磨しましょ~♪♪
それではまた今度!ばいば〜い!
この記事が気に入ったらサポートをしてみませんか?