
画像内テキスト編集方法 「EditingText in the Wild」 の解説と実験

こんにちは、AI inside の趙(チョウ)と申します。2020年3月に入社し、今年3月まではAI Research Unitで文字検出/認識モデルの開発をしており、4月からはLearning Center Unitに異動し「Learning Center」のバックエンド開発を担当しています。本記事では、画像内テキスト編集に関する論文である「Editing Text in the Wild」を解説すると共に、私が実際に日本語データで学習してみた結果を紹介したいと思います。
はじめに
本記事では、論文「Editing Text in the Wild」を取り上げます。
自然画像の文字編集は比較的新しい研究分野ですが、文字修正、広告画像の編集など、画像全体の視覚効果を維持しながら画像中の文字を置き換えることは、生活の中でも利用されている技術です。
この論文では、自然画像のテキストスタイルを保持したままテキスト内容を置換し、置換後のテキストが背景とシームレスに融合する非常にリアルな視覚効果を実現できるスタイル保持ネットワーク(SRNet – style retention network)を提案しています。

また、私はこの論文の手法を使って、自社収集した背景画像と日本語フォントで日本語学習データを生成しモデルを訓練していました。こちらの詳しい内容は記事の後半で説明します。

「Editing Text in the Wild」解説
論文概要
この論文の目的は、自然画像中のテキストを編集することです。論文の筆者によると背景画像とテキストのスタイルを維持し、編集後の画像がオリジナルと同じに見えるようにする必要があるため、難しいタスクです。
そこで、筆者はend to endで学習可能なスタイル保持ネットワーク(SRNet)を提案しています。このネットワークは、テキストの前景スタイル移行モジュール、背景抽出モジュール、および融合モジュールの3つのモジュールから構成されており、著者によると、自然画像に対するテキスト編集を単語レベルで行ったのは、この研究が初めてとなります。
また、合成データと実データ (ICDAR 2013)の両方における視覚効果および定量結果によって、モジュール分解の重要性と必要性を証明しました。テキスト画像合成、AR翻訳、情報隠蔽など多くの現実領域で提案手法の実用性を検証するため、実験を行いました。
論文の研究背景
自然画像におけるテキスト編集は広く生活の中で利用されていますが、難しいテーマです。
難しい理由:
・自然画像のテキストはフォント、色、サイズ、透明度などが大きく異なるため非常に多様
・自然画像の背景は多くのテクスチャや局所的な凹凸があるため、テキストスタイルの移行とテキスト背景完全融合の両方を達成することが困難
・対象文字が元文字より短い場合、文字のオーバーエリアを消去し、適切なテクスチャで埋める必要がある
SRNetの構造
SRNetは複雑なタスクを複数のシンプルなモジュールに分解した共同学習可能なサブネットワークです。具体的には前景スタイル移行モジュール、背景抽出モジュール、融合モジュールで構成されています。
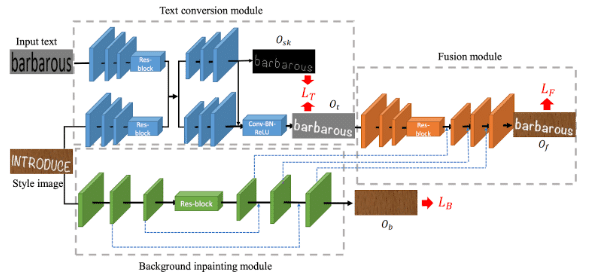
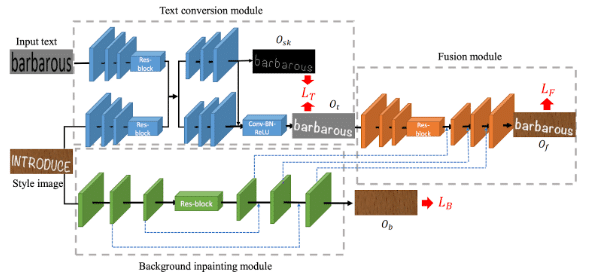
前景スタイル移行モジュール(Text conversion module)
元画像「Style image」と対象テキスト「Input text」をインプットとし、元画像のテキストスタイル(フォント、色、変形など)を対象テキストに移行する役割を担い、モジュールのアウトプットはOtになります。ここで、Encoder-DecoderはSemantic Segmentationに使った手法FCN (Fully Convolutional Network)を使用しています。元画像「Style image」と対象テキスト「Input text」は二つ同じのダウンサンプリング畳み込みレイヤーでエンコードし、特徴を結合します。デコードの段階に対し、skeleton-guided学習機構が導入されています。人間は、主に文字の骨格や字体からテキストを区別しています。元画像「Style image」の移行に伴って、 対象テキスト「Input text」の文字の骨格を保持する必要があると考えられておりますので、この学習機構を利用しています。
背景抽出モジュール(Background inpainting module)
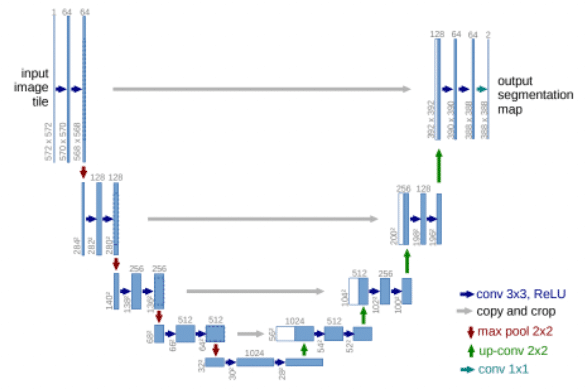
元テキストのピクセルを消去し、適切なテクスチャで埋め、モジュールのアウトプットはObになります。背景のテクスチャをできるだけ全部復元するために、U-Netスキップ接続構造を利用しています。U-Net[1]は、ミラーリングレイヤーの間にスキップ接続を追加することを提案し、セグメンテーションと画像間の通訳タスクに強く適用することが証明されています。ここでは、アップサンプリング処理にこの機構を使用し、同じサイズの以前エンコードした特徴マップを結合して、より豊かなテクスチャを残します。これにより、ダウンサンプリング処理で失った背景情報を復元することができます。
融合モジュール(Fusion module)
前景と背景のテクスチャ情報を融合し、編集されたテキスト画像を生成します。ここでも、Encoder-DecoderはFCN を使用しています。前景スタイル移行モジュール(Text conversion module)で生成した前景画像Otをインプットとし、アップサンプリングの段階に背景抽出モジュール(Background inpainting module)のデコーディング特徴マップと同じ解像度の特徴マップを連結します。これによって、背景が上手く復元でき、対象テキストと背景が上手く融合できます。また、損失$${\mathcal{L}_F}$$に ImageNetでVGG-19学習済モデルの重みを使用したVGG Lossを組み込むことで、画像歪みを抑え、よりリアルな画像を生成できます。
損失関数
$$
\mathcal{L}_G = \arg \min_G \max_{D_B, D_F} ( \mathcal{L}_T + \mathcal{L}_B + \mathcal{L}_F)
$$
$${\mathcal{L}_T}$$ , $${\mathcal{L}_B}$$ ,$${\mathcal{L}_F}$$ は3つのモジュールそれぞれの損失
$${D_B, D_F}$$は背景抽出モジュール(Background inpainting module)と融合モジュール(Fusion module)の識別器(Discriminator)
論文の実験結果
既存手法との比較

アブレーションスタディ

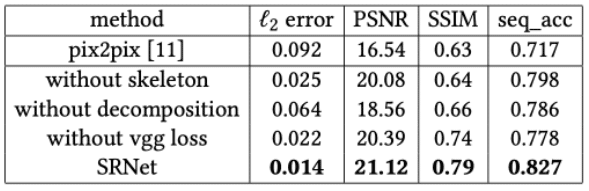
アブレーションスタディの考察により、モジュールの分解化、skeleton-guided学習機構、とVGG-lossの有効性を証明しました。
実験結果



多くの文字画像を正確に変換できる一方、複雑な形状の文字やあまり出現しないフォント、影のある文字などはうまく変換できないこともあるようです。(図10参照)
実際に日本語データで学習してみた
ここまでが論文解説でしたが、今回は自然画像ではなく、日本語帳票データでのテキスト編集効果を知りたいため、私は以下の内容の実験を実際に行いました。
学習条件
・v100 GPU一台
・自然背景画像:153枚 + 書類背景画像:756パーツ
・フォント数:26
・batch: 8
・iter: 500000
日本語コーパスから抽出したテキスト、自然背景画像とフォントをランダムに組み合わせ学習データをリアルタイムで生成しながら学習しています。

実験結果
背景は複雑ではないデータであれば、基本は問題なさそうです。
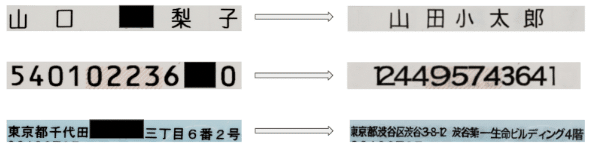
失敗例


考察
罫線、枠ありのデータを生成しておらず、かつ収集した背景データは比較的少ないため、罫線、枠ありのデータの効果がよくないです。一方で、データ生成する際に、上記の罫線、枠を水増しすれば、精度向上が可能ではないかと想定します。
まとめ
本記事では、画像内テキスト編集に関する論文である「Editing Text in the Wild」を取り上げ、その内容と日本語データで学習してみた結果についてご紹介しました。記事にあるように、文字修正、広告画像の編集などのタスクに利用されていますが、一定条件でOCRの領域では、データ拡充とマスキングなども幅広く対応できます。
今回は学習データを生成するために、比較的少ない背景データを利用していますが、もっと多くな背景データを収集すれば、さらに汎用性高いモデルを学習できるではないかなと思います。
今後も画像認識、自然言語処理などのテーマをこのテックブログで取り上げて行きますので、お楽しみに。
【参考文献】
[1] Liang Wu, Liang Wu, Chengquan Zhang, Jiaming Liu, Junyu Han, Jingtuo Liu, Errui Ding, Xiang Bai. Editing Text in the Wild, ACM MM, pages 1-9, 2019.
[2] Olaf Ronneberger, U-Net: Convolutional Networks for Biomedical Image Segmentation, MICCAI, page 2, 2015.
・・・・
この記事が気に入ったらサポートをしてみませんか?