LLM活用サービスのデザインパターン(UI/UX編)

この記事を読んで分かること:
LLM活用サービスの概観マップ
LLMを使うことで生じるUX上の4つの課題
LLM活用サービスにおけるデザインパターン
大規模言語モデル(LLM)を活用したサービスが次々と現れています(気がします)が、そんなLLM活用サービスの開発において、UXデザインの面からどのようなことに気を付けるべきかを、LLMの性質を踏まえて記事にしてみました。
UIデザインからできることだけでなく、エンジニアリング上の設計の面からできることについても触れています。
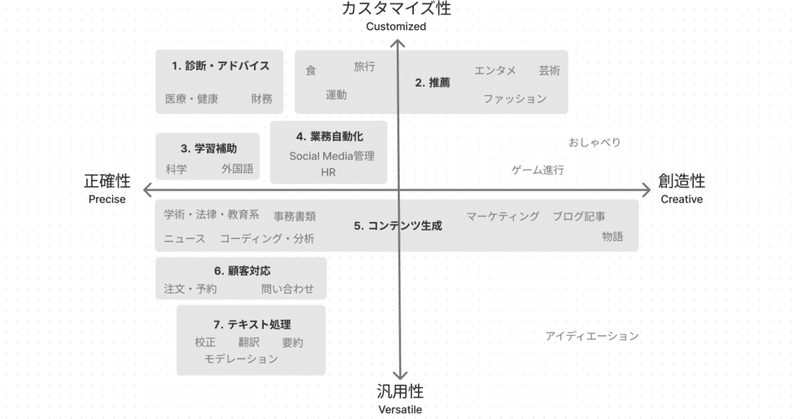
LLM活用サービスの7分類
まず、LLMを活用したサービスについて、形態ごとに7つのカテゴリに分け、以下のような図に整理しました。
「創造性 vs 正確性」「カスタマイズ性 vs 汎用性」という二軸について、それぞれどちらが強く求められるサービスなのかという観点でプロットしています。いろいろ適当なのであまり真面目に見ないでください(ChatGPTと相談して作りました)。

創造性 vs 正確性:
ここで、正確性とはサービスが提示する情報の正しさのことです。顧客の注文を受けるサービスや、医学的な情報を提示するサービスは高い正確性が求められることになります。
カスタマイズ性 vs 汎用性
カスタマイズ性は「session外の情報による個別化(カスタマイズ)の必要性」、汎用性は逆に「全てのユーザに同じように応答する性質」としています。翻訳や要約は履歴やユーザ情報にあまり依存しませんが、リコメンドや診断にはこれらの情報が重要です。
ちなみに、ここではエンドユーザに提供するサービスを想定しています。例えば、翻訳や要約という目的で自分でLLMを使うことは含んでいません。
他にも「インタラクションの頻度」や「リアルタイム応答の必要性」などの軸が考えられそうです。上記の二軸は、特にシステムやUIのデザインパターンに大きく影響すると考えられるため、今回選びました。
LLMによる4つのUX課題
次に、LLMを活用することで、どのようなUX的問題が発生するかを整理します。今回は以下の4点にまとめました。(伝統的な自然言語処理や機械学習を使った場合と比較して問題になる点を特にピックアップしています)

これらの課題に対してどのようにUIデザイン面およびシステム面から対策をしていけるかについて、これから記事にしていこうと思っています。
今回は、左上の「不適切な応答内容」を取り上げます。中でも、「誤った情報の呈示(Hallucination)」は「正確性」が求められるサービスで致命的になるので、重大です。
他の三つは次回以降に取り上げたいと思います。
LLM活用サービスのUIデザインパターン
上記のようなUXの課題を解決するために、RAGを用いたりLLMの出力をそのまま使わないようしたりするなど、システム面からは様々な解決方法があります。今回は課題を軽減するためのUIデザインパターンをまとめました。(ちなみに、[1]の記事ではDefensive UXと呼ばれています。)
主に、Googleの「People + AI Guidebook」のパターンを参考にして、LLMの課題への対応づけを検討しました。
1. チャット以外のUI
文字入力をさせないクリックで完結型のUIの採用
一般に、ユーザが入力に労を要した場合、出力へのユーザの期待は大きくなると言われています[1][2]。このため、チャットや検索などのUIの代わりに、クリックで完結するUIを採用することで、ユーザの期待値が高くなりすぎないようにコントロールできるという見方があります。LLMの出力内容が不適切であると致命的なサービスでは、ユーザの期待値を抑えることが重要になります。
チャット以外のUIの検討を勧める例:
これらの記事のように、チャット以外のUIを採用する理由として、プロンプトリテラシー対策や馴染みのあるUIの提供という点はよく取り上げられていますが、期待値コントロールになるという点は見落とされがちかもしれません。
2. 制限事項・確信度の表示
出力が誤っている場合があることの表示
こちらも期待値コントロールで、ChatGPTを始め多くのサービスで見られるUIです。

People + AI Guidebookも、AIの出力が完璧であるかのような表示は避け、制限事項を明確にし、サービスはあくまで人間の意思決定の補助であることを伝えるべきだと述べています。
最初の図で言うと、「1. 診断」、「5. コンテンツ生成」、「7. テキスト処理」などは、最終的な意思決定をユーザに委ねられるため、このような表示と相性が良いです。一方、顧客対応の場合、「注文の成功確率は60%です」などと言うのは許されませんので、システム上の工夫が必要です。
ちなみに、確信度を表示する場合、数値ではなくフレーズやアイコンで表現することで、解釈が易しくなりユーザの意思決定の支援になるとされています[3][4]。
3. 引用・根拠の表示
出力の根拠となるソース、使用したユーザ情報の呈示
「1. 診断・アドバイス」、「3. 学習補助」、「5. コンテンツ生成」などでは出力の正しさをユーザに判断させるために役に立ちます。

機械学習のUXデザインでは、「ユーザのどんな情報を加味した結果そのような出力になったのか」を表示することがGood UXに繋がるとされています[5]。「1. 診断」や「2. 推薦」などのカスタマイズ度の高いサービスでは、このような情報の表示が有効です。このことは、以下の記事でも触れています。
ただし、複雑なアルゴリズムやシステムがしていること全てを説明しようとするのではなく、あくまでユーザの意思決定に役立つ側面を呈示するべきです[3][5]。
4. LLMの出力の効率的な却下
出力をユーザが不要・不適切と思ったら、すぐに却下・無視できる
ユーザがLLMの出力を労力を要せずに却下・無視できるようにしておくことで、Hallucinationが起きてもUXに大きく影響しないとされています[1]。これは、Good MLUXの条件にも挙げられています[5]。
例えば、Github Copilotでは、AIによる予測を採用しない場合、ユーザはただただ無視して入力をし続ければよいです。ここで予測を却下するために何か操作が必要だと、UXの低下に繋がります。

また、これはそもそもLLMがなくても成立するようにサービスを設計することの重要性も示しています。
5. 制御をユーザへ
ユーザへ制御を渡す・最終確認をさせる
機械学習のデザインでは、モデルの確信度が低い場合に、自動化された処理を止めて、ユーザに制御を渡すことが勧められています。
LLMのHallucinationのことを考えると、LLMの出力の確信度を得るシステムを用意しておいたり、いかなる場合でもユーザが最終確認をする設計にすることになります。
例えば、自動応答でユーザの情報を入力するシステムにおいて、最後に最終的な情報のサマリを表示して、情報送信の確定はユーザに委ねるというのは一般的です。
また、こちらもユーザに制御を渡す以上、そもそもLLMがなくても成立しているサービスにしておくことが肝要です。
今回は、LLMの出力が誤ったり不適切であったりすることを前提に、対策となりうるUIデザインパターンについて議論しました。
次回は、システム設計面から、そもそも誤った出力を減らす方法などについて紹介したいと思います。
以上です。
参考資料
[1] https://eugeneyan.com/writing/llm-patterns/
[2] https://slideslive.com/38934788/a-human-perspective-on-algorithmic-similarity?ref=folder-59726
[3] https://pair.withgoogle.com/guidebook/patterns
[4] https://uxmag.com/articles/designing-for-ai-hallucination-can-design-help-tackle-machine-challenges
[5] https://neptune.ai/blog/good-design-machine-learning
この記事が気に入ったらサポートをしてみませんか?