
5分でわかる!Looker超入門:Lookerのスゴさと注意点【データ利活用の道具箱#8】

皆さんは、「Looker」というサービスをご存じですか?
Lookerは、Google Cloudが提供する、ユーザーのデータ体験を向上させることに重きを置いたサービスです。
具体的には、皆さんがデータを使う際の「ちょっと困ったな」を解決して、快適にデータを使えるようにしてくれる、そんなサービスです。
本記事では、そもそもLookerを知らない、名前だけは知っているけど何がすごいのかイマイチ分からない、というような方に向けて、
Lookerとは何か
Lookerの何がすごいのか
Lookerの注意点は何か
について、例を交えながら分かりやすくご紹介します。
なお、本記事では、Lookerの具体的な使い方までは触れません。
記事を通してLookerに興味を持たれたら、以下の記事も合わせてお読みください。
Lookerの具体的な使い方を知りたい場合はこちら
Looker APIを使ってLookerを使いこなしたい場合はこちら
1 Lookerって何?
Lookerは、Google Cloudが提供する、ユーザーのデータ体験を向上させることに重きを置いたサービスです。
皆さんは、データを使ってレポートを作成したり、データを分析したりする際に「データが使いづらいな」と感じたことはありませんか?
例えば、「ほしいデータを取得するたびに、自分でクエリを作らなければいけなくて手間がかかる(もしくは、担当者に依頼するたびに時間がかかる)」とか、「分析に使うデータを選ぼうとすると、似たような名前のデータがたくさんあったり、どういう成り立ちで作られたデータなのか分からなかったりして混乱する」など、データを利用する際にはこうした面倒ごとや、困りごとに直面することがよくあります。
Lookerは、こうしたユーザーのストレスを軽減させよう!という想いの元に開発されたサービスです。
2 Lookerを使うメリット
Lookerの最大の特徴は、データ基盤のアーキテクチャにセマンティックレイヤを追加できることです。
セマンティックレイヤとは、データを使うビジネスユーザーと、データが格納されているデータソースの間で働く通訳のような存在です。
この通訳機能によって、ビジネスユーザーの不満がどのように解消されるのか、見てみましょう。
例えば、「売上」というデータを使いたいとします。
「売上」のデータをください、と誰かにお願いすればすぐ手に入ると良さそうですが、そうはいきません。データソースであるシステムはビジネスユーザーの言葉を理解できないので、ユーザー側が自分でデータを取りにいく必要があります。
具体的には、まず「売上」とは「注文金額の合計」から「返金額の合計」「割引額の合計」をそれぞれ差し引いたものである、という定義をします。
売上=注文金額の合計―返金額の合計―割引額の合計
そして、それぞれのデータを取得するクエリを発行し、計算します。

では、Lookerを導入してセマンティックレイヤを挟むとどうなるでしょうか。
セマンティックレイヤを挟むことで、システムがビジネスユーザーの言葉を理解して動けるようになります。まず、セマンティックレイヤに先ほどの売上の定義を教えて、そのロジックをLookMLというLookerの独自言語で実装しておきます。(LookMLについては、こちらの記事を参考にしてください)
すると、ビジネスユーザーが「売上」というデータを要求した際、セマンティックレイヤがこのロジックを実行して自動的に適切なクエリを各データソースへ発行する仕組みです。そして、売上金額を算出したうえで、ビジネスユーザーに渡します。
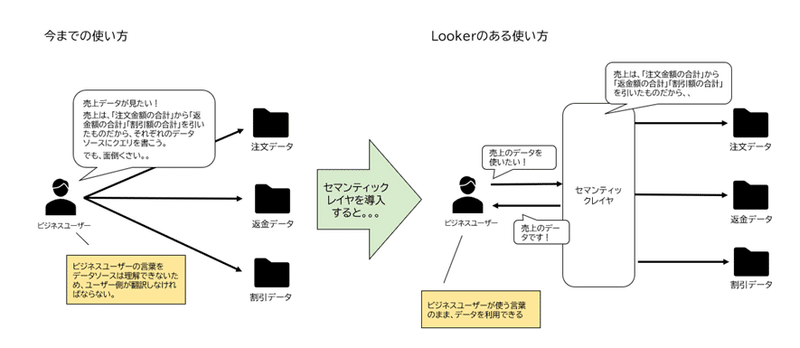
セマンティックレイヤが追加されたことにより、ビジネスユーザーはクエリを書くという面倒な作業から解放され、データを活用するという本来やりたかったことに注力することができるようになります。
他にも、セマンティックレイヤでデータを定義するメリットとして、複数のユーザー間での認識のズレを防げるというものもあります。
例えば、今回の例でいえば「割引額」を考慮した売上データと、考慮しない売上データの2種類が存在することに気づかずレポートしてしまう、といった間違いを防ぐことができるようになります。
このように、データの定義や指標を統制することで、似ているけど少し違うデータが乱立することを防ぎ、分析者にとっても、意思決定者にとっても安心してデータを利用することができるのです。
3 期待できる効果
では、Lookerを導入することによってどの程度ビジネスユーザーの業務が改善するのでしょうか。先ほどの「売上」の例を使って、作業量を比較してみます。
Lookerが無い場合、自社のデータソースから、「売上」のデータを抽出しようとすると、ユーザーには以下の作業が必要になります。
「売上」のデータ定義を確認し、必要なデータを洗い出す。
「売上」を算出するのに必要な「注文データ」「返金データ」「割引データ」がそれぞれ格納されているデータソースを特定する。
BIツールなどを利用し、それぞれのデータソースに「注文金額の合計」「返金額の合計」「割引額の合計」を問い合わせ、クエリを使ってデータを取得する。
「売上」のデータとして使うため、BIツールで「注文金額の合計-返金額の合計-割引額の合計」になるよう計算式を当て、データを加工する。
これらのステップを踏むことで、ようやく定義通りのデータを入手できます。
一方、Lookerを利用して、「売上」データを取得すると次のようになります。
1. Looker内で、「売上」と定義されているデータを検索し、選択する。
2. 実行ボタンを押下する
なんとこれだけで、ビジネスユーザーはデータを利用することができるのです。

このように、Lookerを使えば、ビジネスユーザーはデータの定義を確認したり、データソースにクエリを発行したりしなくても、簡単な操作で快適にデータを活用できるようになるのです。
つまり、ビジネスユーザーの作業ステップを減らすことができる分、その分の開発コストを抑えることができるわけです。
4 Lookerを導入する上での注意点
先ほど、Lookerを使えばビジネスユーザーの作業ステップを大幅に減らすメリットがある、と書きましたが、ユーザーが楽になることと引き換えに、セマンティックレイヤを構築したり運用したりする手間が新たに発生することには注意が必要です。
例えば、以下のような注意点があります。
LookMLを扱える専門のデータエンジニアが必要
前述の通り、セマンティックレイヤを構築したり、メンテナンスをするには、「LookML」という独自言語を使わなければなりません。
LookMLはJSONライクなフォーマットですが、コード内参照などの書き方に癖があるため、専門スキルとして習得する必要があります。そのため、こうした人材の確保や教育にはコストがかかります。
また、現時点でLookMLを扱える人材は多くないため、外部の企業に依頼してしまうとベンダーロックインに繋がることもあります。

データソースにSQLベースのDWHしか利用できない
LookerはSQLでのデータ取得に最適化されており、2024年4月1日時点ではSQLでアクセスが可能なDBのデータしか利用できません。
具体的には、一般的にDWHとして利用されるAmazon Redshiftや、SQLベースのDBであるAmazon Aurora MySQLなどはデータソースとして利用できますが、Amazon S3に代表されるオブジェクトストレージや、SQLを利用できない非構造化データを扱うApache Cassandraなどをデータソースとすることはできません。
そのため、自社の全体アーキテクチャを踏まえ、Lookerの導入によってどの程度の快適さを手に入れることができるかは慎重に見極める必要があります。
補足:S3の場合はAWS Athenaの様に、SQLで検索をかけられるサービスを経由することでデータソースとすることが可能です。ただし、詳細は、Lookerの公式ドキュメントをご確認ください。
5 おわりに
この「データ利活用の道具箱」では、データ利活用を推進する際や、データをもっと活用したいと奮闘している皆さんに役立つ情報をnoteで発信しています。ぜひ他の記事もご覧ください!
ウルシステムズでは「現場で使える!コンサル道具箱」でご紹介したコンテンツにまつわる知見・経験豊富なコンサルタントが多数在籍しております。ぜひお気軽にご相談ください。