
LookerAPIを使ってPythonと連携して分析してみた(準備編)【データ利活用の道具箱 #1】

はじめまして!
最近、GoogleのLookerはAPIがとても充実しているという話を聞きました。
私は機械学習を専門で扱うコンサルタントなので、「LookerでMLOpsを実現するときにはどう使うのか?どんなAPIが役立つのか?」と気になり調べてみました。
調べてみると、確かにAPIは充実していたのですが、同時に「どれを、いつ、どう使えば良いのか?」分かりづらいとも思いました。そこで、自分なりに調べて分かったことを記事にして紹介することにしました。
今回と次回の2回に分けて、Lookerを使って機械学習モデルを作成する手順を説明します。まずは、準備編からです。
なおこの記事の想定読者は、Lookerのアカウントを持っていて、これからLookerAPIを利用しようとしている人です。
Lookerはデータガバナンスを強化するデータ仮想化プラットフォーム
Lookerはデータガバナンスを強化するデータ仮想化プラットフォームです。
データベースを操作する言語と言えばSQLですが、LookerではLookMLと呼ばれるモデリング言語を利用します。(LookMLについては別の記事で書く予定です。お楽しみに)
Lookerの利用者は、必ずLookMLで記述したルールにしたがってデータを取得するので、ガバナンスを効かせることができるのです。
例えば、個人情報など特定のユーザーしか見てはいけないデータがあった場合、権限のないユーザにはそのデータを見せないよう制御できます。
Lookerは何役もこなせる
データ管理業務では、SQL WorkbenchのようなDBに特化したツールを使いますが、データを分析する際はTableauのような分析ツールを使います。このように、データを扱う業務ではいくつものツールを切り替える必要があるので煩わしいのです。
しかしながら、データを扱う全ての人にフォーカスするという理念のもと、データの管理からデータ分析まで、何だってできてしまう万能ツールが存在します。それがLookerです。
さて、ここからはいよいよ、LookerAPIを使ってLookerを操作する手順を紹介します。
準備①:LookerAPIをセットアップする
LookerAPIを利用するには、Looker側の設定と環境構築が必要になります。(Lookerそのものは既に読者が利用できる状態になっている前提とします)
1.Looker側で設定を実施する
はじめに、Looker側でAPIキーを発行します。
①LookerのAdminメニューを開く
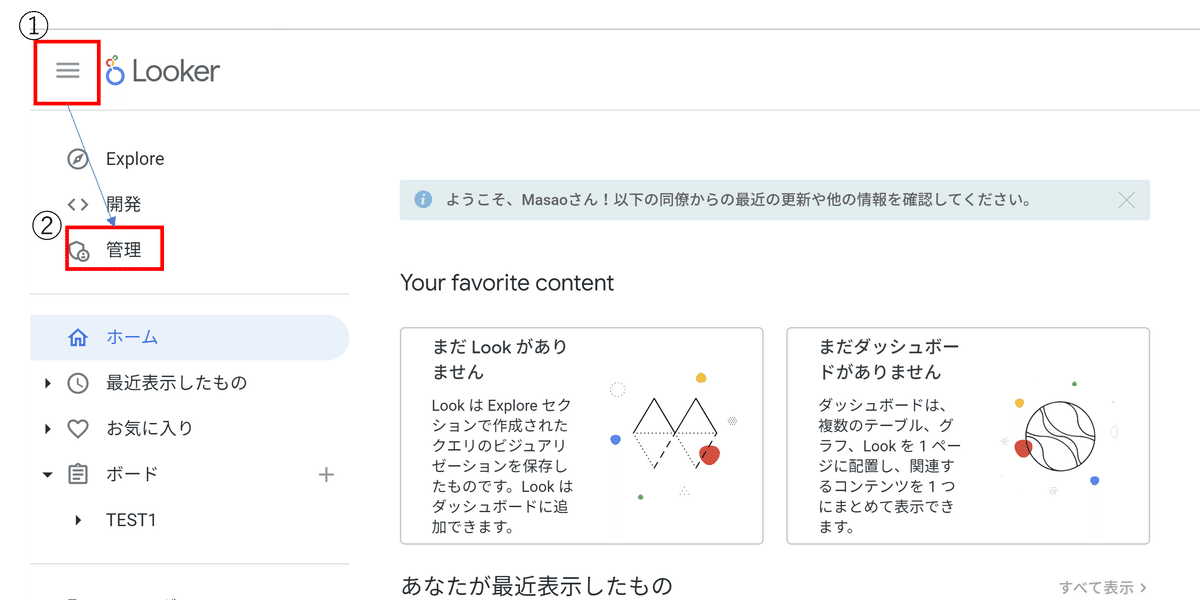
②ユーザーのページから、APIキーを発行したいユーザーを選択する

③EditAPIKEYを選択する

④NewAPIKeyを選択して、新しくAPIキーを作成する
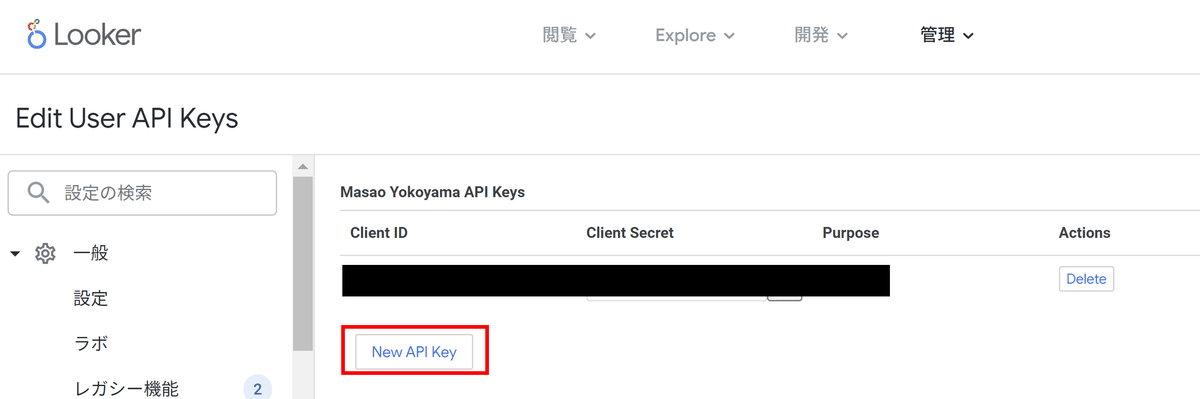
2.クライアント側で環境構築を実施する
LookerでのAPIキーを発行し終えたら、クライアント側の環境を構築します。
①ライブラリをインストールする
pip install looker-sdk②Looker側で発行したAPIキー等を設定ファイルに書き込む
[Looker]
# Base URL for API. Do not include /api/* in the url. If hosted on GCP, remove the :19999 leaving just https://your.cloud.looker.com
base_url=https://{your Looker URL}
# API client id
client_id={管理画面で発行するclient_ID}
# API client secret
client_secret={管理画面で発行するシークレットキー}
# ローカルテスト時だけFalseにする、基本的にはTRUE
verify_ssl=True準備②:Lookerからデータを取得する
環境が構築できたら、いよいよLookerからデータを取得してみます。
Lookerではデータの取得対象として、A.Lookから取得する方法と、B.テーブルから取得する方法の2つがあります。
Lookというのは、ダッシュボード上に配置されたグラフなどデータを可視化した1つ1つのオブジェクトのことです。

ここからは、LookMLを利用してLookerに集められたデータをPython上のAPIで取得する手順を説明します。
A.Lookからデータを取得する場合
以下は、顧客の性別・年齢層別にユーザ数を棒グラフ(Look)で表現したものです。

このグラフから、以下のようなコードと手順でデータを取得する事ができます。
1. JupyterLabを立ち上げて、下のコードをコピペして貼り付ける
2.dashboard_titleとelement_idを自分の環境のものに置き換える
def get_dashboard_data(title: str, element_id: str) -> pd.DataFrame:
"""Get a dashboard by title."""
title = title.lower()
dashboard = next(iter(sdk.search_dashboards(title=title)), None)
if not dashboard:
raise Exception(f'dashboard "{title}" not found')
element = None
for elem in dashboard.dashboard_elements:
if elem.id == element_id:
element = elem
break
if not element:
raise ValueError(f"Element ID {element_id} not found in dashboard {dashboard_id}")
# 要素のクエリIDを取得し、クエリを実行
# elemantの直下にquery_idが無い場合がある
# ない場合はResultMakerFilterablesListen要素にあるquery_idを指定する
# element直下のquery_idとResultMakerFilterablesListenの中にあるquery_idが等しい事は1ケースではあるが確認済み
if element.query_id:
query_id = element.query_id
else:
query_id = element.result_maker.query_id
#Jsonのフォーマットをしたstrで戻ってくる
query_result = sdk.run_query(query_id, "json")
df = pd.read_json(query_result)
return df
#取得したいタイトルとelement_idを予め用意しておく
dashboard_title = "テスト用"
element_id = "127"
get_dashboard_data(dashboard_title,element_id)このコードを実行すると、以下のようにLookのデータをPandasのDataFrame形式に格納する事ができます。

このように、Lookを使うとグラフで表示するために加工されたデータをそのまま使うことができるので、そうしたデータを再利用したい場合に有効です。
B.テーブルからデータを取得する場合
以下の機能群を実装します。
Lookerへの接続名を取得する関数
テーブル一覧を取得する関数
テーブルのカラム一覧を取得する関数
# Lookerへの接続名を取得する関数
def get_all_connection_name():
connections_list = sdk.all_connections()
all_connection_name = [connection.name for connection in connections_list]
return all_connection_name
# テーブル名を取得する関数
def show_tables(connection_name):
schemas = sdk.connection_tables(connection_name)
for schema in schemas:
if schema.is_default:
print("##active schema###############")
print(schema.name)
print("##tables######################")
for table in schema.tables:
print(table.name)
# カラムの一覧を取得する関数
def get_columns(connection_name,schema_name,table_name):
print("##table###################")
print(table_name)
columns_info = sdk.connection_columns(connection_name=connection_name,schema_name=schema_name,table_names=table_name)[0].columns
print("##columns#################")
for column_info in columns_info:
print(column_info.name)JupyterLabで上のコードを実行すると、以下のように特定のテーブルのカラム一覧を取得する事ができます。

テーブルとカラムの情報が取得できたので「order_items」の「shipped_at」と「id」を取得してみます。
1. lookertable_to_dfをコピペする
2. 取得したLookerへの接続名を「connection_name」に格納する
3. 任意のSQLのクエリをSQLの変数に格納する
def lookertable_to_df(connection_name,sql):
sql_query = sdk.create_sql_query(models.SqlQueryCreate(connection_name=connection_name,sql=sql))
sql_identify = sql_query["slug"]
json_data = sdk.run_sql_query(slug=sql_identify,result_format="json")
df = pd.read_json(json_data)
return dfJupyterLabで実行すると、以下のようになります

SQLが実行できて、「shipped_at」と「id」が取得できた事がわかります。
ここまでで、Lookerからデータを取得する方法を説明しました。
次の記事では、今回紹介したLookerAPIを利用して、機械学習のモデルの構築と機械学習の一連のフローを作っていきたいと思います。
おまけ:今回利用したAPI一覧
今回利用したAPIの一覧になります。

おわりに
この「データ利活用の道具箱」は、データ利活用を推進したり、データをもっと活用したいと奮闘している皆さんに役立つ情報をnoteで発信しています。ぜひ他の記事もご覧ください!
ウルシステムズでは「現場で使える!コンサル道具箱」でご紹介したコンテンツにまつわる知見・経験豊富なコンサルタントが多数在籍しております。ぜひお気軽にご相談ください。