
アイドルソングを自動生成してみた❶歌詞生成

〈AI×JapaneseIDOL / AiDolipper〉
はじめに
最近アイドルプロデュースを始めた知り合いがきっかけで始めた企画です。
個人的にも音楽は好きで自然言語処理にも興味があったので挑戦してみました。
アイドルには詳しくないですが、昔はももクロにハマったりとか最近ではBiSHをちょくちょく聞いたりしています。
今回やってみたこと
❶歌詞を生成
❷コード進行を生成
❸メロディを生成
(長文になったため記事を3つに分割しています。)
一曲をまるっと生成というのは難しそうだったので、まずは楽曲の要素を生成することにしました。作曲のちょっとしたアイデアやヒントになればいいなと思っています。
環境
環境はGoogle Colaboratoryを使用しました。
環境構築が不要なので、心が擦りへらずに安心して進められます。。
歌詞を自動生成してみよう
それではさっそく歌詞生成からやっていきます。
まずはデータ収集から始めます。
1. 歌詞データを集める (スクレイピング)
今回は、歌詞は上のサイトから取得しました。
pip install selenium%%bash
mkdir ~/src
cd ~/src
wget https://bitbucket.org/ariya/phantomjs/downloads/phantomjs-2.1.1-linux-x86_64.tar.bz2
%%bash
cd ~/src
tar jxvf phantomjs-2.1.1-linux-x86_64.tar.bz2
cd phantomjs-2.1.1-linux-x86_64/bin/
mv phantomjs /usr/local/bin/よく使われるChromeドライバーが上手くいかなかった(原因不明...)ので "PhantomJS" というものを使用しました。
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
options = Options()
options.set_headless(Options.headless)
browser = webdriver.PhantomJS()
browser.implicitly_wait(3)
lyric_list = []
a = 0
browser.get('https://gakufu.gakki.me/search/?mode=list&word=AT:BiSH')
blocks = browser.find_elements_by_class_name('mname')
print('曲数:{}'.format(len(blocks)))
for n in range(len(blocks)):
# ブラウザ開く
browser.quit()
browser = webdriver.PhantomJS()
browser.get('https://gakufu.gakki.me/search/?mode=list&word=AT:BiSH')
blocks = browser.find_elements_by_class_name('mname')
a += 1
print('{}曲目'.format(a))
# 曲名をクリック(の代わり)
href = blocks[n].find_element_by_tag_name("a").get_attribute("href")
browser.get(href)
# 1曲分の歌詞をパス取得、テキスト変換前処理
lyric_paths = browser.find_elements_by_class_name('cd_1line')
lyric_n = path2text(lyric_paths)
# 複数曲のコード進行をリストにまとめる
lyric_list.append(lyric_n)これでBiSH(アイドルグループ)の歌詞データ58曲分をあっさりと取得できます。次に取得したデータを整えていきます。
2. 歌詞データを整理する (前処理)
import re
def path2text(lyrics):
song = []
for lyric in lyrics:
text = lyric.text
text = re.sub(r'[A-z]+', "", text) #アルファベットの削除
text = re.sub(r'[0-9]+', "", text) #数字の削除
text = re.sub(r'[\r\n/##♭()]', '', text) #改行などの削除
if text.count(' ') == 1: #1つのだけの空白を削除
text = text.strip()
song.append(text)
song = ''.join(song) #空白がバラバラ
song = song.split() #一度リストに分割して
song = ' '.join(song) #再び半角空白で均一につなぐ
return song取得したデータには不要なスペースや改行などがあるので、それらを削除して必要なデータだけに整理します。(この関数は1.に組込み済)
そうしてBishの歌詞58曲分が1曲を1文としてリストにまとめます。
ちなみに非常に卑猥な歌詞が含まれていますが....見つけてしまったらスミマセン

※ BiSH(ビッシュ)は日本の女性アイドルグループ。「楽器を持たないパンクバンド」を謳っている。wikipedia
3. 歌詞データを学習させる (LSTM)
歌詞を変換してデータセットを作成し、モデルに学習させていきます。
from janome.tokenizer import Tokenizer
chars_list = []
for text in lyric_list:
text =Tokenizer().tokenize(text, wakati=True) # 分かち書きする
chars_list.append(text)
count = 0
char_indices = {} # 辞書初期化
indices_char = {} # 逆引き辞書初期化
for chars in chars_list:
for word in chars:
if not word in char_indices: # 未登録なら
char_indices[word] = count # 登録する
count +=1
print(count, word) # 登録した単語を表示
# 逆引き辞書を辞書から作成する
indices_char = dict([(value, key) for (key, value) in char_indices.items()])

まず歌詞に登場する単語のリスト(辞書)を作成します。およそ2400種類の単語が登場しています。
ありのまま、走り出す、などアイドル感のある言葉に加えて、
不平等、うわべ、などBiSHっぽい言葉も出て来ています。
maxlen = 6
step = 1
sentences = []
next_chars = []
for text in text_list:
for i in range(0, len(text)-maxlen, step):
sentences.append(text[i : i+maxlen])
next_chars.append(text[i+maxlen])
print('nb sequences:', len(sentences))

次に "連続した(今回は6)単語をひとまとめにしたセンテンス" と "その次にくる1単語(7語目)" のリストをそれぞれ作成します。これは先ほどの辞書とは別で、元の歌詞データから作成します。1単語ずつずらしていき、およそ16000ほどの要素になります。
import numpy as np
x = np.zeros((len(sentences), maxlen, len(chars)), dtype=np.bool)
y = np.zeros((len(sentences), len(chars)), dtype=np.bool)
for i, sentence in enumerate(sentences):
for t, char in enumerate(sentence):
x[i, t, char_indices[char]] = 1
y[i, char_indices[next_chars[i]]] = 1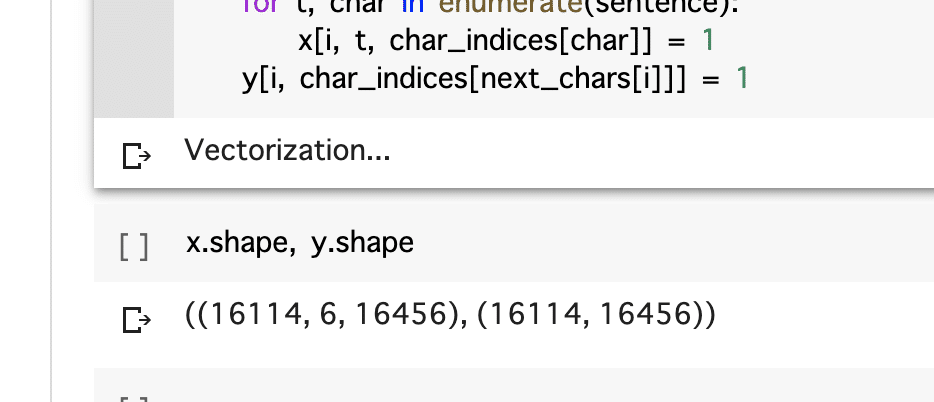
先ほどつくった辞書とセンテンスをベクトルに変換します。
(16114:サンプル数, 6(or 1):語数, 16456:総単語数)
x : 16456語の内(連続した)6語をチェックしたデータが16114サンプル
y : 16456語の内(その次=7語目)1語をチェックしたデータが16114サンプル
from tensorflow.keras.callbacks import LambdaCallback
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
from tensorflow.keras.optimizers import RMSprop
# build the model: a single LSTM
print('Build model...')
model = Sequential()
model.add(LSTM(128, input_shape=(maxlen, len(chars))))
model.add(Dense(len(chars), activation='softmax'))
optimizer = RMSprop(lr=0.01)
model.compile(loss='categorical_crossentropy', optimizer=optimizer)def sample(preds, temperature=1.0):
# 確率配列からインデックスをサンプリングするヘルパー関数
preds = np.asarray(preds).astype('float64')
preds = np.log(preds) / temperature
exp_preds = np.exp(preds)
preds = exp_preds / np.sum(exp_preds)
probas = np.random.multinomial(1, preds, 1)
return np.argmax(probas)モデルを立ち上げます。LSTMを使用しています。
def on_epoch_end(epoch, _):
# Function invoked at end of each epoch. Prints generated text.
print()
print('----- Generating text after Epoch: %d' % epoch)
#random.seed(2)
#start_index = random.randint(0, len(text)-maxlen-1) #テキストのランダム位置からスタート
start_index = 0 #テキストの最初からスタート
for diversity in [0.2]: #diversityは0.2のみ使用
print('----- diversity:', diversity)
generated = ''
sentence = chars[start_index : start_index+maxlen]
# sentence はリストなので文字列へ変換して使用
generated += "".join(sentence)
print(sentence)
# sentence はリストなので文字列へ変換して使用
print('----- Generating with seed: "' + "".join(sentence)+ '" ')
sys.stdout.write(generated)
for i in range(100): #100単語出力
x_pred = np.zeros((1, maxlen, len(chars)))
for t, char in enumerate(sentence):
x_pred[0, t, char_indices[char]] = 1.
preds = model.predict(x_pred, verbose=0)[0]
next_index = sample(preds, diversity)
next_char = indices_char[next_index]
generated += next_char
sentence = sentence[1:]
# sentence はリストなので append で結合する
sentence.append(next_char)
sys.stdout.write(next_char)
sys.stdout.flush()
print()import sys
print_callback = LambdaCallback(on_epoch_end=on_epoch_end)
model.fit(x, y,
batch_size=128,
epochs=20,
callbacks=[print_callback])
学習させて結果を表示していきます。
" 見上げ / た / あの / 夜空 / に / _ "という6語をスタートにして歌詞を生成していきます。そして最終的に生成した歌詞が...
見上げたあの夜空に 浮かぶ星てる ふとし 萎え萎えて まだ生まて よりないそののを 君と強くない かっの? 生きてて 見えたという な きっと た その君と 生きてる だぜ 待って待って 未来を待って立って ずっと生きてるって 感じてた かったから だから君を待って待って 未来を待って立って ずっと生きてるって 感じてた かったから だから
むーん、かなりめちゃくちゃです。。
そして後半は似たようなフレーズの繰り返されています。
連続する言葉は前処理での工夫が必要そうです。
音楽は繰り返しも大事な要素だと思うので、どの程度に削るのか、その加減が重要になってきそうです。
3. 歌詞データを学習させる (マルコフ連鎖)
気をとりなおして!もう1つのモデルを試してみます。
from janome.tokenizer import Tokenizer
import json
# テキストファイルを読み込む
path = '/content/drive/My Drive/AIDOL/pre_song.txt'
sjis = open(path, 'rb').read()
text = sjis.decode('utf_8')
# テキストを形態素解析読み込みます
t = Tokenizer()
words = t.tokenize(text)
# 辞書を生成
def make_dic(words):
tmp = ["@"]
dic = {}
for i in words:
word = i.surface
if word == "" or word == "\r\n" or word == "\n": continue
tmp.append(word)
if len(tmp) < 3: continue
if len(tmp) > 3: tmp = tmp[1:]
set_word3(dic, tmp)
# if word == "":
# tmp = ["@"]
# continue
return dic
# 三要素のリストを辞書として登録
def set_word3(dic, s3):
w1, w2, w3 = s3
if not w1 in dic: dic[w1] = {}
if not w2 in dic[w1]: dic[w1][w2] = {}
if not w3 in dic[w1][w2]: dic[w1][w2][w3] = 0
dic[w1][w2][w3] += 1
dic = make_dic(words)
json.dump(dic, open("markov-blog.json", "w", encoding="utf-8"))
##自動生成
import json
dic = open("markov-blog.json" , "r")
dic = json.load(dic)
tweets_list = []
import random
random.seed(1)
def word_choice(sel):
keys = sel.keys()
ran = random.choice(list(keys))
return ran
def make_sentence(dic):
ret = []
if not "@" in dic: return "no dic"
top = dic["@"]
w1 = word_choice(top)
w2 = word_choice(top[w1])
ret.append(w1)
ret.append(w2)
while True:
w3 = word_choice(dic[w1][w2])
ret.append(w3)
if len(ret)>100 : break
w1, w2 = w2, w3
tweets_list.append(ret)
return "".join(ret)
for i in range(1):
s = make_sentence(dic)
tweets_list.append(s)
print(s)
" 見上げ / た / あの " をスタートにして文章が生成していきます。
結果はこちら...
見上げたあの夜空に 紅誘うと 変わるはずないベイベー ほんの少し優しくしていた授業中思いだすたび悩みだす 近づきつつあるバーコードマフィア あなたはいつも さないで 記憶に居座るグレーな日々よ アホじゃねぇ ただみてる 行く当てはない嘘じゃ あのときの景色が見えたらそれでオッケー ! 優しいアイツもお洒落かあいつもそのうち私の中 つばさをください 虚無な時よ いつか死ぬと 変わるはずない
おお、さっきよりいい感じかもしれません。ある程度文章として読めなくはないです。文脈はあまり理解できませんが、とにかくパッションはハンパない!アイドルソングと言われれば、それっぽく見えてきます。
...ちなみにお気に入りのフレーズは
" 優しいアイツもお洒落なあいつもそのうち私の中...つばさをください "
めっちゃかっこよくないですか...
そこでちょっと歌わせてみました。
(以下のサイトを利用しました。かなり自然な歌声でスゴい技術です。)
メロディのせいか、ちょっと狂気も感じます。。
次回の記事は、コード進行の自動生成になります。
もしよければそちらも是非どうぞ!
参考
この記事が気に入ったらサポートをしてみませんか?