
プロセスマイニングで継続的なプロセス改善

これまではVSMやサービスブループリント、BPMN、PFDなどのプロセスマッピング手法でAsIs / ToBeのプロセスを描き、改善してきましたが「AsIsのデータ取得ができていないため、想定効果の算出、効果測定が難しい」、「対応がワンタイムになってしまい、効率化したプロセスにツギハギで作業が追加され、しばらくすると非効率になってしまう」などの課題を抱えていました。
事実をベースに、継続的にプロセスを改善していくために、プロセスマイニングの導入を考えてみます。
■プロセスマイニングとは
プロセスを軸にしたビッグデータの分析手法です。プロセスの流れを可視化することで、プロセスに潜む様々な問題の特定を容易にし、DX(デジタルトランスフォーメーション)を促進します。捉えにくい概念なので、ここでは関連する概念との比較で考えます。
●DIKWモデル
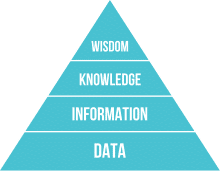
※wikipediaから引用
Data: データ
それ自体では意味を持たない生データ
信号、文字、数字、記号など
Information: 情報
データを整理して意味づけしたもの
who, what, where, when に答えられる
Knowledge: 知識
情報を分析、体系化
how に答えられる
Wisdom: 知恵
知識を正しく認識し、活用できるもの
why に答えられる
●データマイニングとの比較
Data Mining: データマイニング
大量のデータに、統計学やパターン認識などの
データ解析技法を適用して知識を取り出す手法
Text Mining: テキストマイニング
大量のテキストデータから知識を取り出す手法
Image Mining: イメージマイニング
大量の画像データから知識を取り出す手法
Process Mining: プロセスマイニング
大量のプロセスのデータから知識を取り出す手法
●BIとの比較

Business Intelligence: ビジネスインテリジェンス
ビジネスに関わるあらゆるデータ・情報を収集し、分析します。
Process Intelligence: プロセスインテリジェンス
ビジネスインテリジェンスのうち、業務プロセスに関わるデータ・情報に絞って分析します。
Process Mining: プロセスマイニング
プロセスインテリジェンスの中で、業務の流れを分析する手法です。基本になる「自動的なプロセスの発見」には、特殊なアルゴリズムが必要です。専用のプロセスマイニングツールが必要で、BIツールで代替することはできません。
■プロセスマイニングの適用範囲
プロセスマイニングはBPMの分野でAsIs分析の手法として生まれました。あらゆる業種のあらゆる職種でシステムが利用されている現在では「システムの操作というイベント」が分析の対象になるプロセスマイニングの適用範囲も、あらゆる業種・職種に及びます。
システムを利用するのは社員だけでなく顧客も同様です。顧客の行動履歴からカスタマージャーニーの分析にもプロセスマイニングが活用されています。ハードウェアの操作や、センサーのデータからも分析できるので、より広い分野での活用が期待されています。
●組織のデジタルツイン
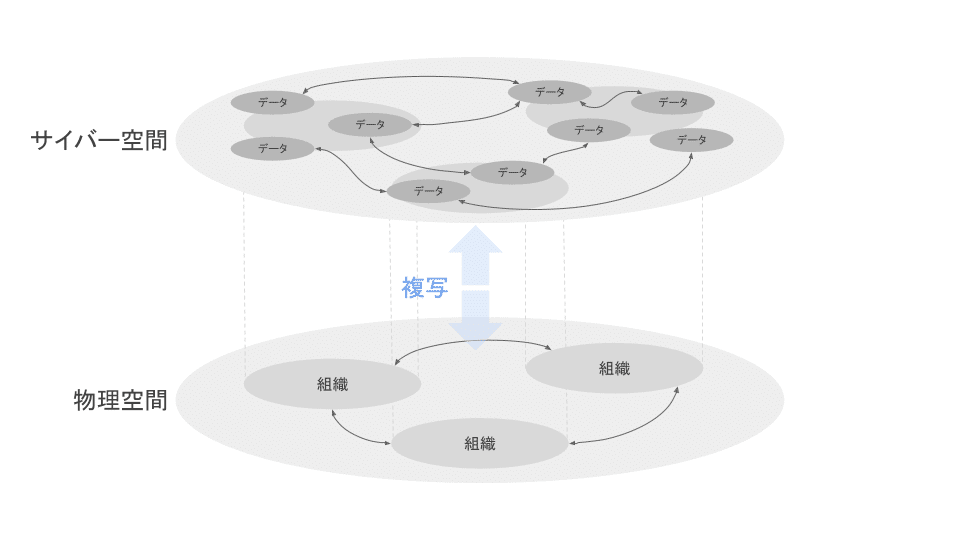
※DXを紐解くから引用
企業や組織を構成する人、環境、資産、業務プロセスなどをサイバー空間に複写したものが、DTO (Digital Twin of Organization: 組織のデジタルツイン)です。
DTOが扱う分野の内、業務プロセスを担うのはプロセスマイニングです。プロセスマイニングで可視化された組織の姿を、仮想モデルで確認することで、さまざまなシミュレーションが可能になります。
■プロセスマイニングの考え方
●従来のプロセス改善との比較
BI、プロセスマッピング
→プロセスマイニング
主観的、部分的
→客観的、全体的
時間がかかる、外部委託
→リアルタイム、内製化
ワンタイムの理解
→継続的に強化
●ライフサイクル

※Celonisのプロセスマイニング実践ハンドブックから引用
Collect: 収集
主要な業務システム、基幹システムなどからイベントログデータを収集
Discover: 発見
イベントログデータから実際の業務プロセスの流れを発見
Enhance: 強化
ビジネス成果を最適化、業務改善するためにプロセスを強化
Monitor: 監視
次の改善ポイントを模索するため、改善成果をモニタリング
●イベントログ

●必須項目
・案件ID、アクティビティ、終了時刻
案件IDでグルーピングされたアクティビティが
終了時刻順に実施されていったものとして可視化します。
●準必須項目
・リソース(担当者)
担当者間でどのような連携が
行われているかを分析する時に必要です。
・ロール(組織・役割)
組織・役割間でどのような連携が
行われているかを分析する時に必要です。
●その他の項目
・ソート順
終了時刻が同じ場合に
順序を示すために必要です。
・開始時刻
待ち時間、作業時間を分けて
分析する場合に必要です。
・成果を示す情報
成果と合わせて分析する時に必要です。
営業の売上、バックオフィスのコストなど
●プロセスの継続的なカイゼン
TOCでの集中の5段階、KPIマネジメントでのCSF、DevOpsのプロセスに関わるケイパビリティ群、イネーブルメントでのコンテンツ制作 など、プロセスを継続的にカイゼンするアプローチはどれも同じ流れです。
計測して現状を知り、ボトルネックを見つけ、解消する
計測を続けて、ボトルネックの移動に気づき、解消し続ける
ボトルネック以外のプロセスを自動化しても、効果は大きくなりません。在庫がたまることで、逆にスループットタイムは低下していきます。ムダの多いプロセスを自動化しても、高速に非効率な作業をこなすだけです。移動するボトルネックを追い続け、カイゼンを繰り返すアプローチが必要になります。
■デリバリーパフォーマンスの分析に適用
CI/CDを導入してデリバリーパフォーマンスを向上する例を題材に、プロセスマイニングを適用します。「CI/CD導入後の効果測定」を目的として操作を確認していきます。
利用するツールはSaaSとオンプレミスでの構築を想定しました。SaaSは、最大手と言われているCelonisの無料版「Celonis Snap」、オンプレミスは、LGPL-3.0で公開されている「Apromore」を利用します。
●サンプルデータの概要
サービスイン後のフェーズを想定したデータを用意しました。タスク管理システムやGitのコミット履歴、CI/CDツールなどから情報を集め、前処理を済ませてある想定です。
フェーズ
分析→設計→実装・UT→システムテスト→QA→CABレビュー→リリース
案件
1: 導入前
2: 本番リリース以外にCI/CDを適用
3〜5: 本番リリースに適用
■Celonis Snap
●概要
・サービス概要
・ウェビナー
●イベントログ
イベントログの登録
・SnapタブのNew AnalysisからGoogle Sheetsを選択
・想定データのURLを指定
・Case ID、Activity、Timestampのカラムをマッピング


イベントログの更新方法
ファイルアップロードの場合は、更新ではなく新規作成の扱いです。Google Sheetsの場合は、日次でのリロードを設定できます。
●パス
ハッピーパスの把握
最も頻度の高いアクティビティをつなげたハッピーパスが初期表示されます。アクティビティ枠内の数字は、通過したCase数です。

バリエーションの把握
Process Explorer右上のスライダーでアクティビティ、右下のスライダーでコネクションの表示数を調整できます。Developer CI / Issue CI / CD dev に置き換わった様子が確認できます。

●スループットタイム
中央、最遅、最速の値を把握
Throughput Time (Details)タブで、確認できます。中央値で22日、最遅で35日、最速で17日であることがすぐに把握できます。

バリエーションごとのスループットタイムの把握
Throughput Timeタブの右ペインで、CaseIDごとのスループットタイムが確認できます。CaseID 1が最遅、CaseID 4が最速であることが分かります。

●ボトルネック
ボトルネックアクティビティの検出
Process Explorer左上のボタンで、Throughput Time(Median)に表示を切り替えると、コネクションにアクティビティごとのスループットタイムを表示できます。最も太いコネクションはCABレビューで、7日間かかっていることが分かります

プロセスのアニメーション表示
Process Explorer左上の再生ボタンで、No groupingに表示を切り替えるとプロセスが進んでいく様子をアニメーションで確認できます。

●その他の機能
手戻りの検出、理想的なプロセスとの適合性チェック、担当者間の連携把握、条件に合わせたアクション実行など、さまざまな機能が提供されています。
■Apromore
●概要
・GitHub
docker-compose.yml が公開されているので、これを利用します。
・チュートリアル
●起動と停止
# clone
git clone https://github.com/apromore/ApromoreDocker.git
# 起動
cd ApromoreDocker
./start
# 停止
./stop●イベントログ
イベントログの登録
想定データをCSVとしてダウンロードしておきます。Fileメニューのuploadをクリックして、CSVを指定。各カラムの扱いを設定します。


イベントログの更新方法
更新ではなく、新しいファイルをアップロードします。
●パス
ハッピーパスの把握
上ペイン中央のnodeスライダーでアクティビティ、arcスライダーでコネクションの表示を調節できます。どちらも最小にした時がハッピーパスになります。

バリエーションの把握
nodeスライダーとarcスライダーを最大にしたときに全てのバリエーションが確認できます。

●スループットタイム
中央、最遅、最速の値を把握
portalでuploadしたイベントログを選択、analyzeメニューの Mine performance on map/model を開くと、スループットタイムが確認できます。中央値、最遅、最速は上ペイン右側で確認できます。


バリエーションごとのスループットタイムの把握
上ペイン下部中央のFilterボタンで表示されるポップアップで、Filterを作成します。Case Variantでパターンを指定すると絞ったバリエーションでのスループットタイムが確認できます。



●ボトルネック
ボトルネックアクティビティの検出
アクティビティ枠内の数字は、通過したCase数と、実行時間です。コネクションに表示されているのは待ち時間です。

プロセスのアニメーション表示
上ペイン下部右側のAnimateボタンから、開いているイベントログのアニメーションを確認できます。

※ https://blog.dcs.co.jp/process-mining/20200326-apromore.html から引用
●その他の機能
他のプロセスモデルとの差分チェック、担当者間の連携把握、イベントに紐付けた任意のデータでの分析など、様々な機能が提供されています。MLとの連携などplugin形式で追加機能が提供されていますが、Docker imageに含まれていないpluginもあります。
■まとめ
SaaSでもオンプレでも無料で始められる
試してみた2つを比較すると、Celonisはビジネスで活用しやすく、Apromoreは詳細を分析しやすくしている印象でした。状況や用途に合わせて使い分けられたら良いですね。
前処理のポイントになるのは、名寄せとステータスの扱い
ソフトウェア開発の現場では、ほとんどのプロセスがシステムを経由するのでイベントログの収集自体は容易です。前処理の肝になりそうなのは、「複数システムをまたがった担当者、アクティビティの名寄せ」と「イベントログの元になるシステムでのステータスの扱い」になりそうです。名寄せはビッグデータを扱う場合の共通課題ですが、どの操作をアクティビティの開始、終了として扱い、なにを除外するのかは、前処理で固めておく必要があります。
この記事が参加している募集
いつも応援していただいている皆さん支えられています。