
GeminiAPIとPatentfieldAPIで特許公報を自動取得して読みやすく要約

こんにちは、Patentfieldの公式noteです。
Patentfield公式noteでは、PatentfieldAPIを活用した具体的な開発実装事例を紹介しています。
この記事では、PatentfieldのAPIを用いて特許公報の文書を取得し、その文書を生成AI(Google Gemini)に与えて、誰でも読みやすく要約を作成させる方法について解説します。
1.特許文書について
特許文書は、馴染みのない人にとってはとても読みづらい文章となっています。例えば、特開2012-123456の特許公報の要約は以下のように記載されています。
公報全文はこちらのリンクで参照することができます
https://patentfield.com/patents/JP2010271469A#/
【要約】
【課題】利用者の利便性を向上させること。【解決手段】決済装置100は、受付部110と、出力部130と、払出部140と、を備えている。受付部110は、利用者からの金銭の投入を受け付ける。出力部130は、受付部110に投入された金銭の額面のうちの最小単位の額面の釣銭の数が1以上である場合に利用者へ警告情報を出力する。払出部140は、受付部110に投入された金銭に基づいて利用者に釣銭を払い出し、投入された金銭の額面のうちの最小単位の額面の釣銭の数が1以上である場合は釣銭の払い出しを一時保留する。
この独特な文章が、特許文書が敬遠される理由だと思います。生成AIはコンテキストの理解にとても優れており、入力された特許文書をもとに、分かりやすい文書を瞬時に作成してくれます。さきほどの特開2012-123456をgemini-1.5-Flashを使用して分かりやすい文書に要約してもらいました。
この特許は、自動販売機などの決済装置における釣銭払い出しの利便性を向上させる技術に関するものです。従来、利用者が小銭を投入して釣銭を減らそうとした際に、誤って小銭の数が足りず、投入した小銭がそのまま釣銭として払い出されてしまう問題がありました。本発明では、決済装置が投入された金額の最小単位の額面の釣銭の数が1以上の場合、利用者に警告情報を表示し、釣銭の払い出しを一時保留することで、利用者が小銭の不足に気づき、追加投入できるようになっています。これにより、不要な釣銭の払い出しを減らし、利用者の利便性を向上させることができます。
このように、生成AIを利用することで、特許文書をとても読みやすい文書に変換することができます。
2.生成AI活用
今回は、特許調査・分析業務に生成AIを活用する最も基本的なアプローチである「要約生成」について、Patentfield APIと、Gemini APIを組み合わせて実施するWebアプリケーションの事例を紹介します。
生成AI(Google Gemini)に入力する特許公報データは、前回の記事で紹介したPatentfield APIの公報全文取得APIを使って公報全文のテキストデータを取得し、生成AI(Google Gemini)に直接入力して、要約文を生成させます。
3.事前準備
・PatentfieldのAPIトークン(APIトークンがなくても、実行環境の構築までは可能です)
※PatentfieldのAPIサービスは有料オプションですが、無料トライアルも随時受付しています。ご興味あれば、APIトークンを発行しますので、下記URLからぜひお問合せください。
https://patentfield.com/apply#/
・Google Gemini APIキー
Google AI StudioでGeminiのAPIキーを取得できます。現在(2024年8月)で、制限事項はあるものの、無料でAPIを使用する事ができます。
4.プログラミング言語、開発環境
・プログラム言語:Python
・開発環境:Google Colab
Google Colab(名称:Google Colaboratory)は、ブラウザベースの無料の開発環境で、Googleアカウントがあればインストール不要で、Pythonプログラミングを簡単に始めることができます。
5.作成したもの
今回作成したものを実行すると、以下のような出力が得られます。
生成AIを使って要約文を取得したい公報番号をまとめてリストで入力し実行すれば、Patentfield APIで公報全文のテキストデータを取得し、そのテキストデータを生成AI(Gemini)に読ませて、各公報の要約文を取得する事ができるアプリケーションになります。
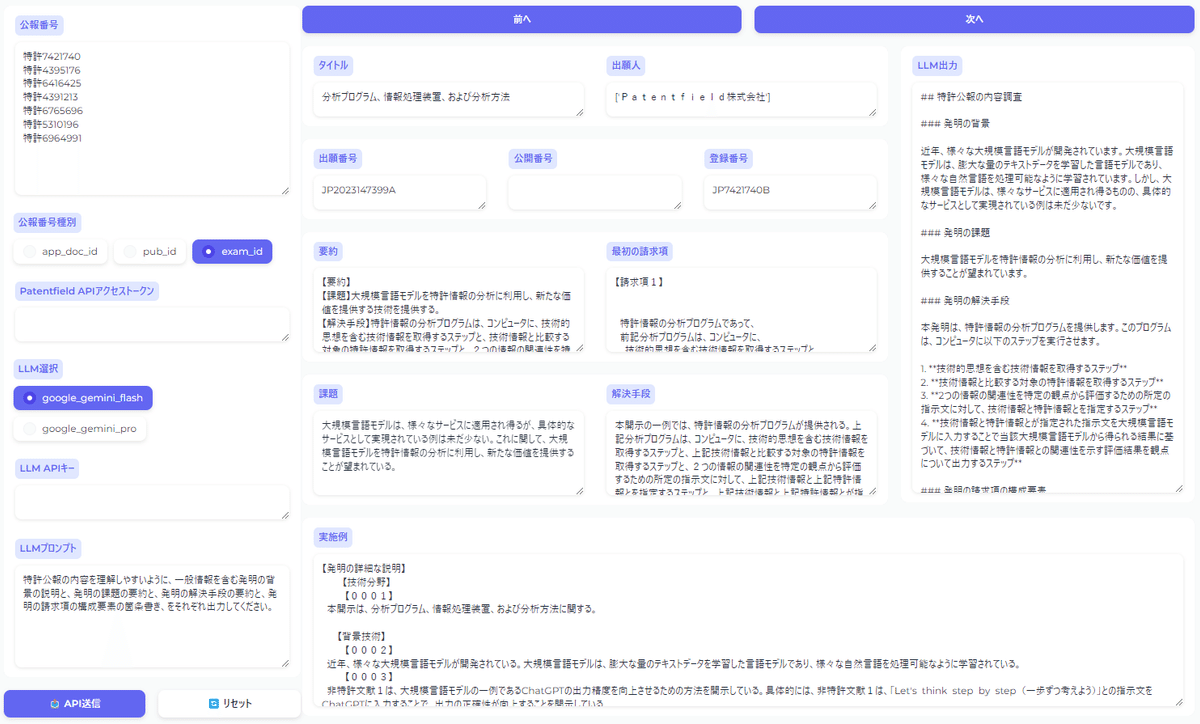
生成AI(Gemini)へのプロンプトを自由に入力する事ができますので、要約文の取得以外にも、キーワードの抽出等、様々な用途で生成AI(Gemini)を活用する事ができます。
Google Colab環境でPythonを使用して、PatentfieldのAPIと、Gemini APIにアクセスし、Gradioを使ってWebアプリ化しています。
Gradioは、機械学習モデルのデモを行うWebアプリケーションを簡単に作ることができるPythonのライブラリです。
6.実装
Google Calabでの実行手順は、次の通りです。
(1)ライブラリのインストール
# ライブラリインストール
!pip install requests
!pip install gradio
!pip install langchain
!pip install langchain-google-genai大規模言語モデル(LLM)を使ったアプリケーションの作成を簡素化するように設計されたフレームワークであるLangchainを使用します。
(2)ライブラリインポート
# ライブラリインポート
import os
import json
import requests
import gradio as gr
import pandas as pd
from datetime import datetime, timedelta, timezone
from pydantic import BaseModel, Field
from typing import Optional, List, Tuple
from langchain_google_genai import ChatGoogleGenerativeAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser(3)Googleドライブマウント
APIから取得したデータをCSVファイル・JSONファイルとして保存するために、Googleドライブをマウントします。
# Googleドライブマウント
from google.colab import drive
drive.mount('/content/drive')(4)CSVファイル保存関数
# CSVファイル保存関数
def save_csv_to_drive(df, prefix):
# タイムゾーンの生成
JST = timezone(timedelta(hours=+9), 'JST')
timestamp = datetime.now(JST).strftime("%Y%m%d%H%M%S")
# CSVファイル名を生成(クエリとタイムスタンプを含む)
csv_filename = f"{prefix}_{timestamp}.csv"
# Googleドライブの保存先パスを設定
drive_path = "/content/drive/My Drive/"
full_path = os.path.join(drive_path, csv_filename)
# DataFrameをCSVファイルとして保存
df.to_csv(full_path, index=False, encoding="cp932", errors="ignore")
return full_path(5)JSONファイル保存関数
# JSONファイル保存関数
def save_json_to_drive(df, prefix):
# タイムゾーンの生成
JST = timezone(timedelta(hours=+9), 'JST')
timestamp = datetime.now(JST).strftime("%Y%m%d%H%M%S")
# JSONファイル名を生成(クエリとタイムスタンプを含む)
json_filename = f"{prefix}_{timestamp}.json"
# Googleドライブの保存先パスを設定
drive_path = "/content/drive/My Drive/"
full_path = os.path.join(drive_path, json_filename)
# DataFrameをJSONファイルとして保存
data = df.to_dict(orient='records')
with open(full_path, 'w', encoding='utf-8') as file:
json.dump(data, file, ensure_ascii=False, indent=2)
return full_path(6)公報全文取得関数
この関数でPatentfieldのAPIを呼び出し、指定した公報に対する公報全文(明細書)データを取得します。
# 公報全文取得
# AcquireFulltextItemsクラス定義
class AcquireFulltextItems(BaseModel):
name: str = Field(..., example="特許7421740")
id_type: str = Field(default="exam_id")
columns: Optional[List[str]] = Field(default=["app_doc_id", "app_id_o", "pub_id", "pub_id_o", "exam_id", "exam_id_o", "app_date", "pub_date", "exam_date", "country", "cross_applicants", "patent_status", "title", "abstract", "ipcs", "fis", "themes", "fterms", "cpcs", "problem", "effect", "technical_field", "background", "solution", "top_claim", "app_claims", "grant_claims", "description", "description_of_embodiment", "abstract_image", "drawings", "table_claims_images", "table_desc_images", "chem_claims_images", "chem_desc_images", "math_claims_images", "math_desc_images"])
# 公報全文取得関数
def acquire_fulltext(item: AcquireFulltextItems, access_token):
# Patentfield APIエンドポイント
req_url = f'https://api.patentfield.com/api/v1/patents/{item.name}'
# Patentfield APIリクエストヘッダー
req_headers = {'Authorization': 'Token ' + access_token, 'Content-Type': 'application/json'}
# APIクエリパラメータ
query_params = {
'id_type': item.id_type
}
if item.columns:
# 各カラムを `columns[]` としてクエリパラメータに追加
query_params.update({'columns[]': item.columns})
# エラー処理
try:
# API呼出
response = requests.get(url=req_url, params=query_params, headers=req_headers)
print("Status Code:", response.status_code)
print("API Response:", response.text)
# APIレスポンス処理
if response.status_code == 200:
try:
data = response.json()
records = data.get('record', {})
# Pandas DataFrameに変換
df = pd.DataFrame([records])
return str(response.status_code), df
except json.JSONDecodeError as e:
print(f"JSON Decode Error: {str(e)}")
print(f"Response content: {response.text}")
return str(response.status_code), pd.DataFrame()
else:
print("API Error:", response.status_code, response.text)
print(f"Response content: {response.text}")
return str(response.status_code), pd.DataFrame()
except requests.RequestException as e:
print(f"Request Error: {str(e)}")
return "Request Error", pd.DataFrame()(7)LLM処理関数
この関数でLLMモデル選択(gemini-flash or gemini-pro)、プロンプト生成、LangchainのLCEL設定を行い、Patentfield APIで取得した公報データをGemini APIにリクエストし、Gemini APIからのレスポンスデータを取得します。
# LLM処理関数
def process_llm(df, model_type, api_key, user_prompt):
# LLMモデル選択
if model_type == 'google_gemini_flash':
google_api_key = api_key
llm = ChatGoogleGenerativeAI(model='gemini-1.5-flash-latest', google_api_key=google_api_key, temperature=0.0)
elif model_type == 'google_gemini_pro':
google_api_key = api_key
llm = ChatGoogleGenerativeAI(model='gemini-1.5-pro-latest', google_api_key=google_api_key, temperature=0.0)
# プロンプト設定
prompt = ChatPromptTemplate.from_template(
"""
あなたは優秀な特許調査のプロです。ユーザーの指示に厳密に従って、以下のドキュメントを調査して下さい。
ユーザーの指示:
{user_prompt}
ドキュメント:
{input}
"""
)
# 出力パーサー設定
output_parser = StrOutputParser()
# LLM Chain設定
chain = prompt | llm | output_parser
# LLMに投入するデータ列を選択
columns_to_analyze = ['abstract', 'top_claim', 'problem', 'solution', 'description']
llm_abstract_texts = []
for index in range(len(df)):
# 各列のテキストデータを結合
combined_text = ' '.join(df.iloc[index][columns_to_analyze].dropna().astype(str))
try:
# LLM Chain実行
response = chain.invoke({"input": combined_text, "user_prompt": user_prompt})
# LLMレスポンスをDataFrameの新しい列に追加
df.loc[index, "llm_abstract"] = response
except Exception as e:
print(f"Exception: {e}")
df.loc[index, "llm_abstract"] = None
return df(8)Webアプリ(Gradio)バックエンド実装
ここでWebアプリ(Gradio)から呼び出される際に実行されるバックエンド機能を関数として実装しています。
# 単一公報データ取得関数
def process_single_name(name: str, id_type: str, access_token: str) -> Optional[pd.DataFrame]:
item = AcquireFulltextItems(name=name.strip(), id_type=id_type)
status_code, df = acquire_fulltext(item, access_token)
return df if not df.empty else None
# LLM処理関数
DEFAULT_PREFIX = "FullTextsLLM"
def process_llm_and_save(df: pd.DataFrame, model_type: str, api_key: str, user_prompt: str) -> Tuple[pd.DataFrame, str, str]:
df_final_llm = process_llm(df, model_type, api_key, user_prompt)
csv_filename = save_csv_to_drive(df_final_llm, DEFAULT_PREFIX)
json_filename = save_json_to_drive(df_final_llm, DEFAULT_PREFIX)
return df_final_llm, csv_filename, json_filename
# dfから初期レコードを抽出
EMPTY_RECORD = ("", "", "", "", "", "", "", "", "", "", "")
def extract_initial_record(df: pd.DataFrame) -> Tuple[str, ...]:
if df.empty:
return EMPTY_RECORD
record = df.iloc[0]
return (
record["title"],
record["cross_applicants"],
record["abstract"],
record["top_claim"],
record["problem"],
record["solution"],
record["description"],
record.get("app_doc_id", ""),
record.get("pub_id", ""),
record.get("exam_id", ""),
record["llm_abstract"]
)
# APIレスポンスを取得し、結果をGradioの状態にマッピングする関数
def acquire_fulltext_wrapper(names: str, id_type: str, access_token: str, model_type: str, api_key: str, user_prompt: str) -> Tuple[str, pd.DataFrame, Optional[str], Optional[str], str, str, str, str, str, str, str, str, str, str, str]:
try:
all_records = [df for name in names.split("\n") if name.strip() and (df := process_single_name(name, id_type, access_token.strip())) is not None]
if not all_records:
return ("No data", pd.DataFrame(), None, None) + EMPTY_RECORD
df_final = pd.concat(all_records, ignore_index=True)
df_final_llm, csv_filename, json_filename = process_llm_and_save(df_final, model_type, api_key.strip(), user_prompt)
initial_record = extract_initial_record(df_final_llm)
return ("Success", df_final_llm, csv_filename, json_filename) + initial_record
except Exception as e:
print(f"Error occurred: {e}")
return ("Error", pd.DataFrame(), None, None) + EMPTY_RECORD
# データフレーム内のレコードをナビゲートする関数
def navigate_record(df: pd.DataFrame, current_index: int, direction: int) -> Tuple[int, str, str, str, str, str, str, str, str, str, str, str]:
if df.empty:
return (current_index,) + ("",) * 11 # 空のデータフレームの場合、空の結果を返す
new_index = (current_index + direction) % len(df)
record = df.iloc[new_index]
return (
new_index,
record["title"],
record["cross_applicants"],
record["abstract"],
record["top_claim"],
record["problem"],
record["solution"],
record["description"],
record.get("app_doc_id", ""),
record.get("pub_id", ""),
record.get("exam_id", ""),
record["llm_abstract"]
)
# 次のレコードにナビゲートする関数
def navigate_next(df: pd.DataFrame, current_index: int) -> Tuple[int, str, str, str, str, str, str, str, str, str, str, str]:
return navigate_record(df, current_index, 1)
# 前のレコードにナビゲートする関数
def navigate_prev(df: pd.DataFrame, current_index: int) -> Tuple[int, str, str, str, str, str, str, str, str, str, str, str]:
return navigate_record(df, current_index, -1)(9)Webアプリ(Gradio)フロントエンド実装
ここでWebアプリ(Gradio)のフロントエンド機能を実装しています。
# GradioカスタムCSS
custom_css = """
.gradio-container, .gradio-container *, .gradio-container .label { font-size: 12px !important; }
.container { max-width: 1200px; margin: auto; padding: 2px; }
.content { display: flex; gap: 2px; }
.sidebar { flex: 1; }
.main-content { flex: 2; }
.gradio-button { transition: all 0.3s ease; }
.gradio-button:hover { transform: translateY(-2px); box-shadow: 0 4px 6px rgba(0,0,0,0.1); }
.navigation-buttons { display: flex; justify-content: space-between; width: 100%; }
.navigation-buttons .gradio-button { flex: 1; margin: 0 5px; }
"""
# Webアプリ(Gradio)フロントエンド実装
with gr.Blocks(css=custom_css, theme='WeixuanYuan/Soft_dark') as app:
with gr.Row(elem_classes="content"):
with gr.Column(elem_classes="sidebar"):
name = gr.Textbox(label="公報番号",lines=8, placeholder="全文を取得したい公報番号を入力してください\n(例:各公報番号は改行区切り)\n特許7421740\n特許4395176\n")
id_type = gr.Radio(label="公報番号種別", choices=["app_doc_id", "pub_id", "exam_id"], value="exam_id")
access_token = gr.Textbox(label="Patentfield APIアクセストークン",lines=1, placeholder="APIのアクセストークンを入力してください")
model_type = gr.Radio(label="LLM選択", choices=["google_gemini_flash", "google_gemini_pro"], value="google_gemini_flash")
api_key = gr.Textbox(label="LLM APIキー",lines=1, placeholder="LLMのAPIキーを入力してください")
user_prompt = gr.Textbox(label="LLMプロンプト", lines=5, value="特許公報の内容を理解しやすいように、一般情報を含む発明の背景の説明と、発明の課題の要約と、発明の解決手段の要約と、発明の請求項の構成要素の箇条書き、をそれぞれ出力してください。")
with gr.Row():
submit = gr.Button("📤 API送信", variant="primary")
reset = gr.Button("🔄 リセット", variant="secondary")
status_code_output = gr.Textbox(label="APIステータスコード", lines=1, interactive=False)
download_csvpath = gr.Text(label="ダウンロードCSVファイルパス")
download_jsonpath = gr.Text(label="ダウンロードJSONファイルパス")
with gr.Column(scale=3, elem_classes="main-content"):
with gr.Row(elem_classes="navigation-buttons"):
prev_button = gr.Button("前へ", variant="primary")
next_button = gr.Button("次へ", variant="primary")
with gr.Row():
with gr.Column(scale=2):
with gr.Row():
title_output = gr.Textbox(label="タイトル", lines=1, interactive=False)
cross_applicants_output = gr.Textbox(label="出願人", lines=1, interactive=False)
with gr.Row():
app_id_output = gr.Textbox(label="出願番号", lines=1, interactive=False)
pub_id_output = gr.Textbox(label="公開番号", lines=1, interactive=False)
exam_id_output = gr.Textbox(label="登録番号", lines=1, interactive=False)
with gr.Row():
abstract_output = gr.TextArea(label="要約", lines=5, max_lines=5, interactive=False)
top_claim_output = gr.TextArea(label="最初の請求項", lines=5, max_lines=5, interactive=False)
with gr.Row():
problem_output = gr.TextArea(label="課題", lines=5, max_lines=5, interactive=False)
solution_output = gr.TextArea(label="解決手段", lines=5, max_lines=5, interactive=False)
with gr.Column(scale=1):
llm_output = gr.TextArea(label="LLM出力", lines=29, interactive=False)
with gr.Row():
description_output = gr.TextArea(label="実施例", lines=10, max_lines=10, interactive=False)
df_state = gr.State(pd.DataFrame())
current_index_state = gr.State(0)
# APIリクエスト送信ボタン
submit.click(
fn = acquire_fulltext_wrapper,
inputs = [name, id_type, access_token, model_type, api_key, user_prompt],
outputs = [status_code_output, df_state, download_csvpath, download_jsonpath, title_output, cross_applicants_output, abstract_output, top_claim_output, problem_output, solution_output, description_output, app_id_output, pub_id_output, exam_id_output, llm_output]
)
# リセットボタン
reset.click(
fn = lambda: ["", pd.DataFrame(), "", "", 0, "", "", "", "", "", "", "", "", "", "", "", "exam_id", "", ""],
inputs = [],
outputs = [status_code_output, df_state, download_csvpath, download_jsonpath, current_index_state, title_output, cross_applicants_output, abstract_output, top_claim_output, problem_output, solution_output, description_output, app_id_output, pub_id_output, exam_id_output, name, id_type, llm_output, user_prompt]
)
# 次ボタン
next_button.click(
fn = navigate_next,
inputs = [df_state, current_index_state],
outputs = [current_index_state, title_output, cross_applicants_output, abstract_output, top_claim_output, problem_output, solution_output, description_output, app_id_output, pub_id_output, exam_id_output, llm_output]
)
# 戻るボタン
prev_button.click(
fn = navigate_prev,
inputs = [df_state, current_index_state],
outputs = [current_index_state, title_output, cross_applicants_output, abstract_output, top_claim_output, problem_output, solution_output, description_output, app_id_output, pub_id_output, exam_id_output, llm_output]
)(10)Webアプリ(Gradio)を起動
ここでWebアプリ(Gradio)を起動します。
# Webアプリ(Gradio)起動
app.launch(debug=True)Gradioが起動したら、
1.特許情報を取得したい公報番号をまとめてリストで入力
2.Patentfield APIアクセストークンを入力
3.LLMを選択(google_gemini_flash or google_gemini_pro)
4.LLM APIキーを入力
5.LLMプロンプトを入力(デフォルトで要約取得のプロンプトを設定しています。)
し、「API送信」ボタンを押すと、Patentfield APIから取得した公報全文のテキストデータと、LLM(Gemini)による要約文が表示されます。
取得した公報リストと、LLMによる要約文はGoogleドライブのMy Driveに「FullTextsLLM_{YYYYMMDDhhmmss}.csv」と「FullTextsLLM_{YYYYMMDDhhmmss}.json」というファイル名で保存されています。
6.おわりに
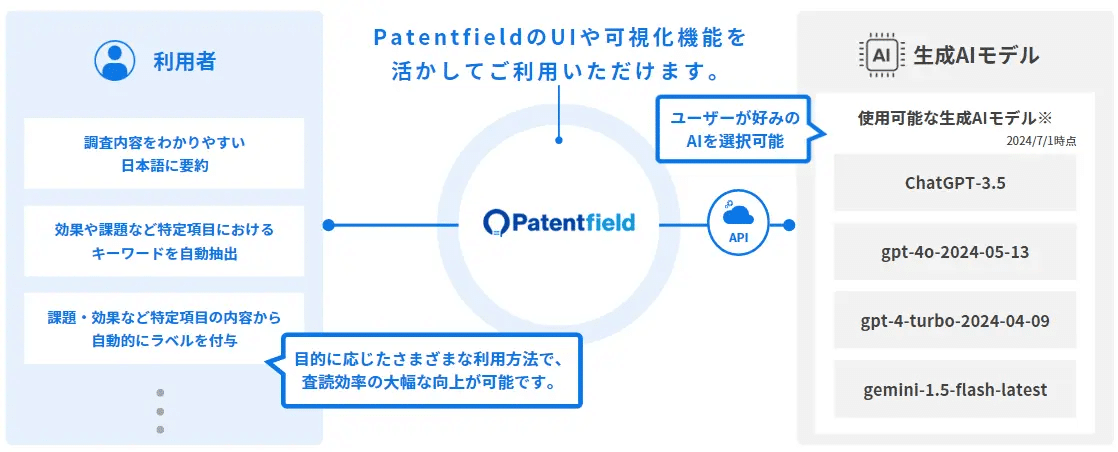
Patentfieldでは、2024年7月より、「Patentfield AIR」というPatentfieldのインターフェースに生成AI機能を組み込むことで、PatentfieldのAI検索機能をはじめ各種検索機能を利用して最大1万件の国内外の検索母集団に対して、一括で生成AIの出力結果を得ることができるオプション機能をリリースしました。
https://patentfield.com/news/256#/
Patentfieldとは
Patentfieldは、4つの機能(プロフェッショナル検索・データ可視化・AI類似検索・AI分類予測)を組み合わせて、ワンストップで総合的な検索・分析ができる『AI特許総合検索・分析プラットフォーム』です。
無料で検索もできるので、ご興味あればぜひアクセスください。
PatentfieldのAPIについて
PatentfieldのAPI連携サービスは、情報参照だけではなく、特許検索機能をはじめPatentfieldの各機能をAPI経由で連携することで、社内で運用しているグループウェアへの組み込みや、特許検索・分析の独自アプリケーションの開発が可能になります。
AIセマンティック検索やAI分類予測などのAI機能や、PFスコアや類似キーワードの取得などPatentfieldの多彩な機能を利用して、特許に関わる社内のニーズに合わせて最適なワークフローやアプリケーションを構築できます。
次回以降も、特許検索や分析実務で役立つ開発実装例を紹介していきます。
実践的なケーススタディを通じて、みなさまの知財業務変革のヒントになればと思います。
#Python
#Google Colab
#Gradio
#AI
#生成AI
#LLM
#Gemini
#Langchain
#Patentfield
#特許
#知財
#知的財産