
テーブルデータを使って予測モデルを作成してみよう

書籍『LightGBM予測モデル実装ハンドブック』より、第1章-1『予測モデルの概要-予測モデル』から「テーブルデータの予測モデル」を公開します。予測モデルの実装プロセスを学びましょう。
前回の記事『機械学習には「教師あり学習」「教師なし学習」「強化学習」があります』の続きとなります。先に読むことをおすすめします。
テーブルデータの予測モデル
テーブルデータを例に予測モデルの実装プロセスを具体化します。テーブルデータは図1.2のように、行と列で構成された表形式のデータで、行はデータ1件ごとのレコード(インスタンス)、列はレコード1件ごとの属性情報を表し、特徴量の列と目的変数の列があります。

構造化データと非構造化データ
学習データは、構造化データと非構造化データに分けることができます。構造化データはテーブル形式のデータで、非構造化データは構造化データ以外のすべての総称で画像、文章、音声などのデータを指します。一般的に構造化データは機械学習、非構造化データは深層学習と相性がよい傾向がありますが、学習データの特性やデータ量に応じて、機械学習と深層学習を使い分けます。
本書は、webで公開されているデータセットをテーブルデータに使用します。テーブルデータを使って、予測モデルを作成するとき、テーブルデータを「学習用」と「評価用」のレコードに分割する必要があります。最も簡単なデータセットの分割方法は、学習データとテストデータの2つに分割する方法です。学習データには特徴量と目的変数があり、モデルの学習に使用します。同様に、テストデータには特徴量と目的変数があり、予測値と目的変数を突き合わせて、モデルを評価します。
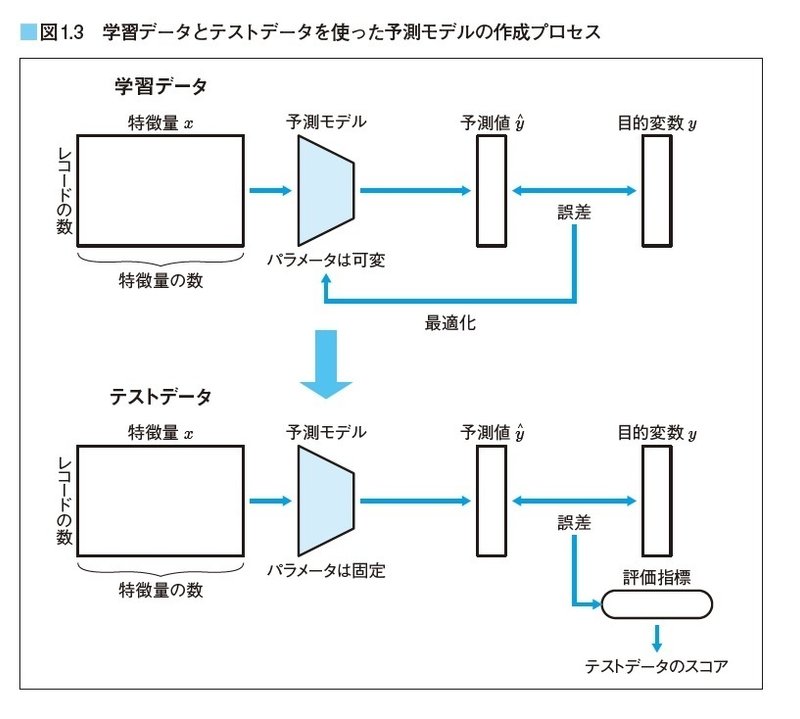
予測モデルは図1.3のように特徴量を入力し、予測値を出力します。モデルは特徴量の重みを表すパラメータを持っています。パラメータはモデルの特性を表す数値であり、モデルは入力された「特徴量の数値」と「パラメータの数値」を組み合わせて予測値を計算します。予測モデルの作成プロセスは学習→予測→評価の3プロセスに整理できます。
学習
予測モデルの中のパラメータは可変です。学習はモデルの予測値と目的変数の正解値で誤差を計算し、誤差が小さくなるようモデルの中のパラメータを最適化します。
予測
学習が終わったら、テストデータの特徴量をモデルに入力し、予測値を出力します。このとき、モデルの中のパラメータを固定して予測値を計算します。
評価
評価は、目的変数と予測値を評価指標に入力して、モデルの精度をスコア化します。図1.3の例だとモデルの堅牢性を担保するため、学習に使用していないテストデータで評価します。モデルは学習データの目的変数を使用し、学習しているため、正解値を知っています。そのため、学習データは最終的なモデルの良し悪しの評価には使えません。
次回は、第1章-2『予測モデルの概要-機械学習アルゴリズム』から「機械学習アルゴリズムの全体像」を公開します。
本書の目次
第1章 予測モデルの概要
1.1 予測モデル
イントロダクション
テーブルデータの予測モデル
1.2 機械学習アルゴリズム
機械学習アルゴリズムの全体像
決定木のアンサンブル学習
勾配ブースティングのライブラリ
1.3 環境構築
サンプルコード
Colaboratoryの初期設定とサンプルコードの格納
第2章 回帰の予測モデル
2.1 データ理解
住宅価格データセット
1変数EDA
2変数EDA
回帰の評価指標
2.2 線形回帰
単回帰のアルゴリズム
単回帰の予測値の可視化
重回帰のアルゴリズム
正則化
特徴量の標準化
重回帰の学習→予測→評価
パラメータによる予測値の解釈
2.3 回帰木
決定木
回帰木のアルゴリズム
回帰木のアルゴリズム(学習)
深さ1の回帰木の可視化
深さ1の回帰木の予測値の検証
回帰木の深さと予測値
深さ2の回帰木の可視化
回帰木の正則化
回帰木の学習→予測→評価
2.4 LightGBM回帰
勾配ブースティング回帰のアルゴリズム
深さ1のLightGBM回帰の可視化
深さ1のLightGBM回帰の予測値の検証
LightGBM回帰の学習→予測→評価
SHAP概要
SHAPによる予測値の説明
第3章 分類の予測モデル
3.1 データ理解
国勢調査データセット
数値変数EDA
カテゴリ変数EDA
前処理
分類の評価指標
混同行列と正解率の検証
3.2 ロジスティック回帰
ロジスティック回帰のアルゴリズム
ロジスティック回帰の学習→予測→評価
パラメータによる予測値の解釈
3.3 LightGBM分類
勾配ブースティング分類のアルゴリズム
LightGBM分類の学習→予測→評価
SHAPによる予測値の説明
3.4 検証データ評価
検証データのモデル評価
ホールドアウト法
不均衡ラベルのホールドアウト法
アーリーストッピング
LightGBM分類(アーリーストッピング)の実装
クロスバリデーション
クロスバリデーションの実装
第4章 回帰の予測モデル改善
4.1 データ理解
ダイヤモンド価格データセット
1数値変数EDA
2数値変数EDA
カテゴリ変数EDA
前処理
評価指標の選択
4.2 線形回帰
線形回帰の予測モデル
Lasso回帰の予測モデル
4.3 LightGBM回帰
LightGBM回帰の予測モデル
SHAPによる予測値の説明
クロスバリデーションのモデル評価
クロスバリデーション後の予測
4.4 特徴量エンジニアリング
新規特徴量の追加
新規特徴量:数値変数×数値変数
新規特徴量:数値変数×カテゴリ変数
新規特徴量:カテゴリ変数×カテゴリ変数
新規特徴量を追加した予測モデル
クロスバリデーションのモデル評価
4.5 ハイパーパラメータ最適化
LightGBMのハイパーパラメータ
Optunaを用いたハイパーパラメータ最適化の実装
最適化ハイパーパラメータを用いた予測モデル
クロスバリデーションのモデル評価
LightGBMモデル改善の結果
第5章 LightGBMへの発展
5.1 回帰木の計算量
学習アルゴリズム
回帰木の可視化
回帰木の予測値の検証
5.2 回帰木の勾配ブースティング
学習アルゴリズム
二乗誤差の重み
勾配ブースティングの可視化
勾配ブースティングの予測値の検証
5.3 XGBoost
XGBoostの改善点
アンサンブル学習の目的関数
XGBoostの目的関数
葉の分割条件
類似度によるデータ分割点の計算
二乗誤差の重みと類似度
XGBoostの可視化
XGBoostの予測値の検証
XGBoostの枝刈り
5.4 LightGBM
LightGBMの改善点
ヒストグラムによる学習の高速化
深さから葉への探索方法の変更
カテゴリ変数のヒストグラム化
LightGBMの可視化
LightGBM(leaf-wise)の可視化
5.5 学習時間の比較
太陽系外惑星データセットと前処理
ライブラリの学習時間比較
この記事が気に入ったらサポートをしてみませんか?