
初心者がAIの画像認識を使い、ミドリゾウリムシを見分けてみた。

(閲覧注意)微生物の画像認識についての記事になります。画像等もありますのでそういったものが苦手な方(いわゆる集合体恐怖症の方も)は閲覧にはお気を付けください。
はじめに
最近Pythonを用いた機械学習をど素人ながら学んでおりまして、成果物提出課題の一環として本記事を書かせて頂きます。
エンジニア経験等全く無く、そもそもコードって何?というところから学習を開始した初心者です。プログラマーの方々本当にすごい・・・
今回のコーディングは悩みまくり、スクールの教材や色々なブログを参考にさせて頂き、そして担当して頂いた講師の方に聞きまくってアドバイス沢山頂いたことで、何とか形にすることが出来ました。
参考にさせて頂いた論文やブログの執筆者の方々、スクールの方々そして何よりも、お忙しい中親身にご指導頂いた担当講師様、本当にありがとうございました。
今回は成果物作成にあたり、微生物であるミドリゾウリムシを見分けるためにAIを用いたCNN画像認識処理を行うことをテーマにしております。
今回の作業環境としてはGoogle Colabotoryにてコーディングいたしました。
まだ研究などに使えるレベルのものではありませんが、今後もそこを目指して少しずつ改良出来たらと良いなと思っております。
ミドリゾウリムシは、正直あまり知られていない生物であり、更に全く別の微生物のミドリムシに間違えられることの方が多い生物です。
(私の経験上、微生物に詳しい方々といった例外は除いて、ミドリゾウリムシについて話した際には必ずミドリムシと言われます)
今回、画像認識のコーディングの内容と同時に、そんなミドリゾウリムシのことも知って下さる方が増えてくれたらと思ったのもこのテーマを選んだ理由の一つです。
あくまで今回はコーディングの勉強のための記事ですが、この記事を読まれたあなた様が、この緑色したやつはミドリムシではなくて『ミドリゾウリムシ』!と言ってくださるようになれば嬉しいです。
今回、こういうことが出来るのならばそれを応用してミドリゾウリの分類もできるのではないかと気づきを与えて下さった&コーディングにおいても大変参考にさせて頂いた方々の記事はこちら↓
Niziuのメンバーを機械学習で分類してみた - Qiita
機械学習を学び、愛猫判別のアプリを制作|yupimo|note
AI Academy | Deep Learningで犬・猫を分類してみよう
カラスが嫌いな友達のために画像判定AIを使って、Slackに通知 (ecomottblog.com)
猿の種類を見分ける画像判別機を転移学習、google coloboratory、kerasで作ろう!(ディープラーニング入門)|バラオ|note
1.概要と目的について
ミドリゾウリムシとは

体の中に住まわせています。大きさは約0.12mmの微生物です
ミドリゾウリムシ(学名Paramecim bursaria)とは、水中に生息する微生物であり、理科の実験や授業などでよく用いられるゾウリムシの種類の中の一つです。
最大の特徴としては、健康食品としても用いられている藻類であるクロレラを体内に約数百個住まわせ、共生(細胞内共生)させているゾウリムシであるということです。
ミドリゾウリはクロレラに対して光合成に必要な二酸化炭素などを与えます。一方クロレラは光合成で得た栄養素などをミドリゾウリに与えることで共生が成り立っています。
他者どうしの助け合いで生活が成り立つという、人間社会にも通ずるものがありますね。
こういった特徴があるため様々な研究が行われていて、『共生』という生物の進化に大きく関わる現象の解明や応用、また環境や医療分野への応用にも期待されている実はすごい生物です。
で、今回なにをしたいかというと、このクロレラを共生させているミドリゾウリムシと、クロレラを体内から取り除いたミドリゾウリムシ(便宜上シロゾウリと呼ばれています)をAIの画像認識を使って見分けることはできないのか?という検証です。
先ほど軽く触れた再共生の実験では、まずこのシロゾウリにクロレラが再共生するように手法を試みます。
その結果、再共生が成功して体内にクロレラを持っているものと、再共生に失敗しクロレラを持っていないシロゾウリのままのものを顕微鏡で見分け、カウントすることで再共生率がわかります。
今回はそのカウントをAIにしてもらうことで効率化を目指すという試みのステップ1、まずは見分けて貰えるようになろうという位置づけになります。
ではさっそくコーディングの内容について書かせて頂きます。

クロレラはいないですが元気にたくましく生きています。

記事の先頭の画像も、たまたま撮れた結晶が綺麗なものを選んでみました。
ミドリゾウリムシの参考の論文などはこちら
Kodama, Y. and Fujishima, M. (2008) Mechanism of establishment of endosymbiosis between the ciliate Paramecium bursaria and the symbiotic alga Chlorella species. Jpn. J. Protozool. Vol. 41, No. 2. 15-19.
Albers, D. and Wiessner, W. (1985) Nitrogen nutrition of endosymbiotic Chlorella spec. Endocyt. C. Res., 1, 55-64.
Brown, J.A. and Nielsen, P.J. (1974) Transfer of photosynthetically produced carbohydrate from endosymbiotic Chlorella to Paramecium bursaria. J. Protozool., 21, 569-570.
Kodama, Y. and Fujishima, M. (2005) Symbiotic Chlorella sp. of the ciliate Paramecium bursaria do not prevent acidification and lysosomal fusion of the host digestive vacuoles during infection. Protoplasma, 225: 191–203.
2.プログラムのコーディングについて
AIの機械学習においての画像認識の大まかな流れとしては、
画像収集→画像選定→画像学習→画像推定という流れです。
今回はGoogle Colabotory(一部時間制限や使用制限等があるものの無料で使えますありがたや・・・)を用いてコーディングを行った為、Colabotory上でも画像が使えるように画像データをGoogleドライブにアップロードしたうえ、マウントすることで使えるようにしています。
2.1 画像収集
まずは画像収集からです。
ここで本当ならばWebページから必要な情報を自動で抜き出してくれる作業の『スクレイピング』で画像収集を行いたいところです。
ただ残念ながらミドリゾウリはともかくシロゾウリの画像はインターネット上にはあまり無い&あっても研究者の方々の論文及びホームページで使われているものが多く、著作権の関係で勝手に使えない為、今回は私の手持ち画像を用いました。
本当はデータ1000枚ずつとかほしいところなのですが、残念ながら手持ちが少なく画像選定をしていたらデータ枚数は150枚ずつ程度で非常に少ないものとなってしまいました。
今回は、限られた枚数で試みてみたらどうなるのかという検証が、少しですが出来たのかなと思います。
今後まず試すべきなのは、TensorFlow の ImageDataGeneratorを使った画像の水増しだなとは思っています。
更に今後は元データ自体も新たに画像認識用に撮影したものを使ってみたいです・・・
↓ちなみにスクレイピングの参考の動画です。こちらも機会があれば行いたいです。
https://www.youtube.com/watch?v=hRB104ik6pQ
参考にさせて頂いたのはこちら
Google Colaboratory上でKerasを使って画像認識をやってみた - cojimaru BLOG (hatenablog.com)
2.2 画像選定
手持ちのデータから機械学習用の画像を選んだりしていきます。
各画像を分けていきます。
今回は画像を一つ一つ目視で分けました。
分け方としては、ゾウリムシの中に一つでもクロレラがあるようならば
『ミドリ』、一つも無いようならば『シロ』という様に分けています。
また全く同じ画像は除去していますが、顕微鏡のカメラで撮影しているため、同じ個体(細胞)でもピントが違ったり向きや大きさの違うものは元々のデータの数が少ない為今回はそのままにしています。
次回はここも変えてやってみたいと思っています。
ミドリゾウリ以外が写っているような学習に使いづらい画像も削除したり、ミドリやシロが大きく写るようにトリミングなどで加工したりしました。
ちなみにこれが人の顔とかならばOpenCVを使えばトリミングなどもできる様です。
OpenCVで顔認証を行いトリミングして保存する - AI人工知能テクノロジー (newtechnologylifestyle.net)
こちらも次回以降試してみたいですね。
あれこれやって結果用意できたのが150枚ずつと非常に少ないです。
何度も言いますがもっと数を増やしたいですね。
そして画像のサイズを揃え、Googleドライブへとアップロードしました。
2.3各ファイルのインポート
Google Colabotoryを使いながらコーディングするための準備としてGoogleドライブに画像データを格納しておきます。
これでColabotory上でマウントすることにより画像データが使えるようになります。
マウントのやり方の参考にさせて頂いたのはこちら
ColaboratoryでのGoogle Driveへのマウントが簡単になっていたお話 - Qiita
ディープラーニングのお勉強~その9。Google Colab Kerasのレイヤー設定を独自に解釈してみた~ | mgo-tec電子工作
まずGoogleドライブを開き、左上の新規を押します。
(Google Colabotoryを新規で開くときもまずは同じ手順のようです)
次に新しいフォルダを押して名前をつけるとフォルダが完成です。
今回はdataset1と付けました。
フォルダを開くとここにファイルをドロップと出てきました。
あらかじめ選定用意しておいたミドリのフォルダ(今回は『1』と付けています)とシロのフォルダ(こちらは『0』と付けています)をドロップしてアップロードしました。
ではGoogle Colabotoryを開きます。
処理はランタイムのところからタイプ変更でGPUに変えて行っています。
使いすぎるとしばらくの時間GPUに接続できなくなるので要注意です。
左横のファイルのアイコンを押して、その中のドライブのマウントも押しておきます。
ではコーディングを開始します。
先に今回のコーディングをまとめたものを記載いたします。
講師の方にアドバイス頂いたコードも多く、それについて私自身が理解をする為に、また数値やパラメーターなども試行錯誤してみた時に気づいた事を忘れない為にもコメントアウト#を色々つけており見にくいです。
ご容赦ください。
import glob
drive_siro ='/content/drive/MyDrive/dataset1/0/'#Google Driveの画像データフォルダ0のシロをマウント、取り出し
drive_midori ='/content/drive/MyDrive/dataset1/1/'#Google Driveの画像データフォルダ1のミドリをマウント、取り出し
image_size = 256 #256x256のサイズに指定
import os #osモジュール(os機能がpythonで扱えるようにする)
import cv2 #画像や動画を処理するオープンライブラリ
import numpy as np #python拡張モジュール
import matplotlib.pyplot as plt #グラフ可視化
from tensorflow.keras.preprocessing.image import ImageDataGenerator
#学習の際にDence、過学習予防、平滑化層、インプット、畳み込み層、プーリング層、活性化関数、バッチノーマライゼーションを使えるようインポート
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input,Conv2D, MaxPooling2D, Activation,BatchNormalization
from tensorflow.keras.applications.vgg16 import VGG16 #学習済モデルVGG16のインポート
from tensorflow.keras.models import Model, Sequential #線形モデルのインポート
from tensorflow.keras import optimizers #最適化関数のインポート
from keras.callbacks import EarlyStopping #過学習を防ぐためモデルの改善が止まった時点で学習を止めるEaelyStoppingのインポート
#os.listdir() で指定したファイル(siroとmidori)を取得
path_siro = [filename for filename in os.listdir(drive_siro) if not filename.startswith('.')]
path_midori = [filename for filename in os.listdir(drive_midori) if not filename.startswith('.')]
#ゾウリムシの画像を格納するリスト作成、データを代入
img_siro = []
img_midori = []
for i in range(len(path_siro)):
img = cv2.imread(drive_siro+ path_siro[i])#画像を読み込む
img = cv2.resize(img,(image_size,image_size))#画像をリサイズする
img_siro.append(img)#画像配列に画像を加える
for i in range(len(path_midori)):
img = cv2.imread(drive_midori+ path_midori[i])
img = cv2.resize(img,(image_size,image_size))
img_midori.append(img)
#np.arrayを用いてXに学習画像、yに正解ラベルを代入
X = np.array(img_siro + img_midori)
#正解ラベルの作成
y = np.array([0]*len(img_siro) + [1]*len(img_midori))
label_num = list(set(y))
#配列のラベルをシャッフルして学習の効率を上げる
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
#データを学習データ80%と検証データ20%に分けて用意#90%と10%に分けた時よりaccuracyの数値は良かった
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
#VGG16を使用せずに、畳み込み層ベースのモデルを使うバージョン
#活性化関数はsigmoidとreluを用いた。2値分類なので最後はsigmoidを使う。それ以外はreluの方がaccuracyは高くなった。
#filters(抽出する特徴の種類、小さすぎても大きすぎてもダメ)=32
#kernel_size(畳み込みに使用する重み行列の大きさ)
#stridesは特徴を抽出する間隔でカーネルを動かす距離を指定(小さい方が良いとされデフォルトで1×1)
#paddingは畳み込んだ時の画像の縮小を抑えるため、入力画像の周囲にピクセルを追加
#pool_sizeは一度にプーリングを適用する領域のサイズ(プーリングの粗さ)、基本的に2×2
#stridesは特徴マップをプーリングする間隔を指定、kerasではデフォルトでpool_sizeと一致させる
#Dropoutを入れて過学習を防ぐ。更なる検証必要だが今回は幾つか検証してみてこの様に。
#バッチノーマライゼーションで標準化
classifier = Sequential()
classifier.add(Conv2D(32, (3, 3), input_shape = (image_size, image_size, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(64, (3, 3), activation = 'relu'))#64
#classifier.add(Dropout(rate=0.5))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(128, (3, 3), activation = 'relu'))#128
#classifier.add(Dropout(rate=0.5))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(128, (3, 3), activation = 'relu'))#128
#classifier.add(Dropout(rate=0.5))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(128, (1, 1), activation = 'relu'))#128
classifier.add(Dropout(rate=0.5))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Flatten())
#classifier.add(BatchNormalization())#ミニバッチ学習の際にバッチごとに標準化を行う
classifier.add(Dense(units = 64, activation = 'relu'))#relu,sigmoid
classifier.add(Dropout(rate=0.5))
classifier.add(BatchNormalization())
classifier.add(Dense(units = 1, activation = 'sigmoid'))
# CNN画像認識コンパイル
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
#optimizerはadam、lossはbinary_crossentropyがaccuracy,val_accuracy共に高い数値
#loss=mean_squared_error,binary_crossentropy
#adam,SGD,Adagrad,RMSprop,Adadelta,Adamax,Nadam
# EaelyStoppingの設定
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0.0,
patience=3,
)
# 学習の実行
history = classifier.fit(X_train, y_train, batch_size=32, epochs=200, verbose=1, validation_data=(X_test, y_test))
score = classifier.evaluate(X_test, y_test, batch_size=32, verbose=0) #モデルの分類精度確認確認
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score)) #グラフで可視化
#classifier.fit()で、CNN画像認識コンパイルした内容を指定のepochs数で訓練を実行。
#historyはclassifier.fit()の戻り値として取得する学習履歴のオブジェクト。
#batch_size=16,32,64で試し今回は32がaccuracyが高かった。
#epochs=30,100,150,200,250,300回数で試し今回は200回数でaccuracyが高かった。
#verboseは、学習過程の表示の仕方で0は不表示、1はプログレスバー表示、2は結果のみ表示
#validation_data(検証データ)
#accuracy、val_accuracy、loss、val_lossの可視化プロット
fig = plt.figure(figsize=(8,6))
ax1 = fig.add_subplot(2, 2, 1)
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
ax2 = fig.add_subplot(2, 2, 2)
plt.plot(history.history["loss"], label="loss", ls="-", marker="o")
plt.plot(history.history["val_loss"], label="val_loss", ls="-", marker="x")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
#モデル保存
classifier.save('zouri.h5')
#画像推定の為のテスト用画像の準備
drive_test ='/content/drive/MyDrive/test1' #テスト用画像をマウントしてから取り出し
image_size = 256
path_test = [filename for filename in os.listdir(drive_test) if not filename.startswith('.')] #ファイル取得
img_test = [] #リスト作成
for i in range(len(path_test)):
img = cv2.imread(os.path.join(drive_test, path_test[i])) #os.path.joinでファイルパスを結合して画像を読み込む
img = cv2.resize(img,(image_size,image_size)) #画像をリサイズする
img_test.append(img) #画像配列に画像を加える
new_model = keras.models.load_model('zouri.h5')#保存した学習モデルの呼び出し
#画像の推定
for i in img_test:
pred = new_model.predict(np.expand_dims(i, axis=0))#np.expand_dimsで画像の次元拡張をしてから、モデル予測
cls = int(np.round(pred)) #約分することで0か1かを表示
print("{} : {}".format(pred, cls))
#テスト画像の可視化(通常)
fig = plt.figure(figsize=(8,6))
fig.subplots_adjust(wspace=0, hspace=0)
for i in range(10):
x = img_test[i]
plt.subplot(2, 5, i+1)
b,g,r = cv2.split(x)
plt.imshow(img_test[i])
x = cv2.merge([r,g,b])
plt.xticks([]),plt.yticks([])
plt.imshow(x)
plt.suptitle("img_test1",fontsize=30)
plt.show()
#テスト画像の可視化(クロレラみやすい)
fig = plt.figure(figsize=(8,6))
fig.subplots_adjust(wspace=0, hspace=0)
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(img_test[i])
plt.xticks([]),plt.yticks([])
plt.suptitle("img_test2",fontsize=30)
plt.show()では各コーディングの流れを拙いですが説明させて頂きます。
まず画像マウントできるようにglobをインポートしてGoogle Driveの画像データフォルダをそれぞれマウントします。あと画像サイズも設定しました。
import glob
#Google Driveの画像データフォルダ0のシロゾウリ画像をマウントして取り出す
drive_siro ='/content/drive/MyDrive/dataset1/0/'
#Google Driveの画像データフォルダ1のミドリゾウリをマウントして取り出す
drive_midori ='/content/drive/MyDrive/dataset1/1/'
image_size = 256 #256x256のサイズに指定次にライブラリやモジュールが使えるようにインポートしていきます。
import os #osモジュール(os機能がpythonで扱えるようにする)
import cv2 #画像や動画を処理するオープンライブラリ
import numpy as np #数値計算効率化用numpyモジュール
import matplotlib.pyplot as plt #グラフ描画用matplotlibライブラリ
#転移学習の際にDence、過学習予防、平滑化層、インプット、畳み込み層、プーリング層、活性化関数、バッチノーマライゼーションに必要
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input,Conv2D, MaxPooling2D, Activation ,BatchNormalization
from tensorflow.keras.applications.vgg16 import VGG16 #学習済モデルVGG16のインポート
from tensorflow.keras.models import Model, Sequential #線形モデルのインポート
from tensorflow.keras import optimizers #最適化関数のインポートインポートしたら今度は画像を使えるように取得したり、格納リストを作成したりしていきます。
#os.listdir() で指定したファイル(siroとmidori)を取得
path_siro = [filename for filename in os.listdir(drive_siro) if not filename.startswith('.')]
path_midori = [filename for filename in os.listdir(drive_midori) if not filename.startswith('.')]
#ゾウリムシの画像を格納するリスト作成、データを代入
img_siro = []
img_midori = []
for i in range(len(path_siro)):
img = cv2.imread(drive_siro+ path_siro[i]) #画像を読み込む
img = cv2.resize(img,(image_size,image_size)) #画像をリサイズする
img_siro.append(img) #画像配列に画像を加える
for i in range(len(path_midori)):
img = cv2.imread(drive_midori+ path_midori[i])
img = cv2.resize(img,(image_size,image_size))
img_midori.append(img)2.4 画像の学習、結果の可視化
画像の学習を進めていきます。
正解ラベル等を用意し、更にラベルシャッフルで効率をあげます。
#np.arrayでXに学習画像、yに正解ラベルを代入
X = np.array(img_siro + img_midori)
#正解ラベルの作成
y = np.array([0]*len(img_siro) + [1]*len(img_midori))
label_num = list(set(y))
#配列のラベルをシャッフルして学習の効率を上げる
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]参考にさせて頂いたのはこちら
numpy.random.permutation – 配列の要素をランダムに並べ替えた新しい配列を生成 | HEADBOOST
Generator.permutation – 既存の配列の要素をランダムに並べ替えた新しい配列を生成 | HEADBOOST
そしてデータを学習データと検証データに分けます。
今回は学習用データ8:検証用データ2の割合で分けました。
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]
#データを学習データ80%と検証データ20%に分けて用意#90%と10%に分けた時よりaccuracyの数値は良かった。
データを分けたところでkerasのmodel.addなどを用いてCNN構築をしていきます。
実は最初は転移学習(学習済みのモデルを使って新たなモデルの学習を行うことです)を使ってみようということで、VGG16を使わせて頂きコーディングをしていました。
ところが私の後学のために講師の方に教えて頂いた畳み込み層ベースのモデルを使うバージョンの方を色々改良してみたところVGG16を使った時より、あくまで今現在でありますがval_accuracy、val_lossの数値が安定していそうな為、今回はですがこちらのコーディングを主に使っています。
VGG16の方も現在改良中で、画像推定の前の学習までのコーディングは後ろの方に記載しています。
やることが多い・・・でも興味深い・・・時間が欲しい・・・
#VGG16を使用せずに、畳み込み層ベースのモデルを使うバージョン
#活性化関数はsigmoidとreluを用いた。2値分類なので最後はsigmoidを使う。それ以外はreluの方がaccuracyは高くなった。
#filters(抽出する特徴の種類、小さすぎても大きすぎてもダメ)=32
#kernel_size(畳み込みに使用する重み行列の大きさ)
#stridesは特徴を抽出する間隔でカーネルを動かす距離を指定(小さい方が良いとされデフォルトでは1×1)
#paddingは畳み込んだ時の画像の縮小を抑えるため、入力画像の周囲にピクセルを追加
#pool_sizeは一度にプーリングを適用する領域のサイズ(プーリングの粗さ)、基本的に2×2
#stridesは特徴マップをプーリングする間隔を指定、kerasではデフォルトでpool_sizeと一致
#Dropoutを入れて過学習を防ぐ。更なる検証必要だが今回は幾つか検証してみてこの様に。
#バッチノーマライゼーションで標準化
classifier = Sequential()
classifier.add(Conv2D(32, (3, 3), input_shape = (image_size, image_size, 3), activation = 'relu'))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(64, (3, 3), activation = 'relu'))
#classifier.add(Dropout(rate=0.5))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(128, (3, 3), activation = 'relu'))
#classifier.add(Dropout(rate=0.5))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(128, (3, 3), activation = 'relu'))
#classifier.add(Dropout(rate=0.5))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Conv2D(128, (1, 1), activation = 'relu'))
classifier.add(Dropout(rate=0.5))
classifier.add(MaxPooling2D(pool_size = (2, 2)))
classifier.add(Flatten())
#classifier.add(BatchNormalization())ミニバッチ学習の際にバッチごとに標準化を行う
classifier.add(Dense(units = 64, activation = 'relu'))#relu,sigmoid
classifier.add(Dropout(rate=0.5))
classifier.add(BatchNormalization()) #標準化
classifier.add(Dense(units = 1, activation = 'sigmoid'))
# CNN画像認識コンパイル
classifier.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
#optimizerはadam、lossはbinary_crossentropyがaccuracy,val_accuracy共に高い数値
#loss=mean_squared_error,binary_crossentropy
#adam,SGD,Adagrad,RMSprop,Adadelta,Adamax,Nadam各数値やパラメーターは色々検証してみた結果、今回は上記に落ち着きました。
更なる検証をしたいです。時間が欲しい・・・
今回の実際に作成されたモデルを確認するには
classifier.summary()で出来ます。
Model: "sequential_10"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_49 (Conv2D) (None, 62, 62, 32) 896
max_pooling2d_48 (MaxPoolin (None, 31, 31, 32) 0
g2D)
conv2d_50 (Conv2D) (None, 29, 29, 64) 18496
max_pooling2d_49 (MaxPoolin (None, 14, 14, 64) 0
g2D)
conv2d_51 (Conv2D) (None, 12, 12, 128) 73856
max_pooling2d_50 (MaxPoolin (None, 6, 6, 128) 0
g2D)
conv2d_52 (Conv2D) (None, 4, 4, 128) 147584
max_pooling2d_51 (MaxPoolin (None, 2, 2, 128) 0
g2D)
conv2d_53 (Conv2D) (None, 2, 2, 128) 16512
dropout_17 (Dropout) (None, 2, 2, 128) 0
max_pooling2d_52 (MaxPoolin (None, 1, 1, 128) 0
g2D)
flatten_8 (Flatten) (None, 128) 0
dense_16 (Dense) (None, 64) 8256
dropout_18 (Dropout) (None, 64) 0
batch_normalization_8 (Batc (None, 64) 256
hNormalization)
dense_17 (Dense) (None, 1) 65
=================================================================
Total params: 265,921
Trainable params: 265,793
Non-trainable params: 128こんな感じになりました。
参考にさせて頂いたのはこちら
Home - Keras Documentation
Modelクラス (functional API) - Keras Documentation
第4回 CNN(Convolutional Neural Network)を理解しよう(TensorFlow編):TensorFlow入門 - @IT (itmedia.co.jp)
kerasのConv2D(2次元畳み込み層)について調べてみた - Qiita
活性化関数(Activation function)とは?:AI・機械学習の用語辞典 - @IT (itmedia.co.jp)
【GIF】初心者のためのCNNからバッチノーマライゼーションとその仲間たちまでの解説 - Qiita
オプティマイザー (keras.io)
損失関数 - Keras Documentation
シグモイド関数を分類に使う理由は確率を表すから (investor-daiki.com)
第11回 機械学習の評価関数(二値分類/多クラス分類用)を理解しよう:
TensorFlow 2+Keras(tf.keras)入門 - @IT (itmedia.co.jp)
で、いよいよ学習の実行と結果の可視化です。
過学習を防ぐためにEaelyStoppingも追加しています。
# EaelyStoppingの設定
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0.0,
patience=3,
)
#学習の実行
history = classifier.fit(X_train, y_train, batch_size=32, epochs=200, verbose=1, validation_data=(X_test, y_test))
score = classifier.evaluate(X_test, y_test, batch_size=32, verbose=0) #モデルの分類精度確認確認
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score)) #グラフで可視化
#classifier.fit()で、CNN画像認識コンパイルした内容を指定のepochs数訓練を実行。
#historyはclassifier.fit()の戻り値として取得する学習履歴のオブジェクト。
#batch_size=16,32,64で試し今回は32がaccuracyが高かった。
#epochs=30,100,150,200,250,300回数で試し今回は200回数でaccuracyが高かった。
#verboseは、学習過程の表示の仕方。0は不表示、1はプログレスバー表示、2は結果のみ表示
#validation_dataは検証データ
#accuracy、val_accuracy、loss、val_lossの可視化プロット
fig = plt.figure(figsize=(8,6))
ax1 = fig.add_subplot(2, 2, 1) #左に来るように
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
ax2 = fig.add_subplot(2, 2, 2) #右に来るように
plt.plot(history.history["loss"], label="loss", ls="-", marker="o")
plt.plot(history.history["val_loss"], label="val_loss", ls="-", marker="x")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
学習結果はこちら
Epoch 198/200
8/8 [==============================] - 35s 4s/step - loss: 0.0022 - accuracy: 1.0000 - val_loss: 0.4020 - val_accuracy: 0.8500
Epoch 199/200
8/8 [==============================] - 35s 4s/step - loss: 0.0033 - accuracy: 1.0000 - val_loss: 0.3748 - val_accuracy: 0.8667
Epoch 200/200
8/8 [==============================] - 35s 4s/step - loss: 0.0054 - accuracy: 1.0000 - val_loss: 0.3733 - val_accuracy: 0.8500
validation loss:0.3732893764972687
validation accuracy:0.8500000238418579Epoch 198/200
8/8 [==============================] - 1s 73ms/step - loss: 0.0086 - accuracy: 1.0000 - val_loss: 0.2820 - val_accuracy: 0.9000
Epoch 199/200
8/8 [==============================] - 1s 74ms/step - loss: 0.0255 - accuracy: 0.9917 - val_loss: 0.2686 - val_accuracy: 0.9000
Epoch 200/200
8/8 [==============================] - 1s 75ms/step - loss: 0.0103 - accuracy: 1.0000 - val_loss: 0.2836 - val_accuracy: 0.9000
validation loss:0.28362610936164856
validation accuracy:0.8999999761581421Epoch 198/200
8/8 [==============================] - 1s 76ms/step - loss: 0.0173 - accuracy: 0.9958 - val_loss: 0.2211 - val_accuracy: 0.9167
Epoch 199/200
8/8 [==============================] - 1s 76ms/step - loss: 0.0159 - accuracy: 1.0000 - val_loss: 0.1955 - val_accuracy: 0.9000
Epoch 200/200
8/8 [==============================] - 1s 76ms/step - loss: 0.0239 - accuracy: 0.9958 - val_loss: 0.2097 - val_accuracy: 0.8833
validation loss:0.20972102880477905
validation accuracy:0.8833333253860474
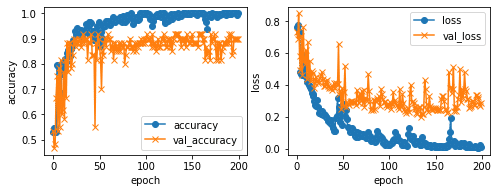

結果はランタイムを動かすごとにまちまちです。
epoch数やbatch_sizeも色々試しながらコーディングいたしましたが、再検証の余地は沢山ありますね・・・。
最終のaccuracyが0.95以上、val_accuracyも0.80以上はコンスタントに出るように、またlossも下がるような調整は出来たかなという感じですが、val_accuracyとval_lossはブレが多い感じが見受けられます。
各数値やパラメータの再検証、例えば今回はimage_sizeを256×256にしているのですが、今後はここを64×64の低bitにしても高いaccuracyや低いlossが出るように各調整したりすること等も課題かと思われます。
参考にさせて頂いたのはこちら
機械学習におけるバッチサイズとは?決め方や注意点を解説 | TRYETING Inc.(トライエッティング)
kerasでモデルの学習が進まなくなったら学習を止める方法 | 分析ノート (analytics-note.xyz)
こちらの文章がVGG16を用いた転移学習バージョンになります。
上記のコーディングだと(#データを学習データ80%と検証データ20%に分ける)までは同じで、その後コーディング内容が違ってきます。
こちらもランタイムを動かすごとにまちまちの結果です。
accuracy、val_accuracyの数値が高い時は高いのですがval_lossも高い・・・そして1epoch数目のlossがやたらと高くなります。
グラフがなんじゃこれというものになります・・・
何故かが今のところ不明なのでそこも勉強必須です。
数値やパラメーターを変更したりもっと検証&改良の必要ありです。
epoch数はVGG未使用バージョンよりも少ない回数(今回epoch=150)で学習が済む感じはいたしましたが、ここも要検証です。
#データを学習データ80%と検証データ20%に分けて用意までは上記と同じ。
import glob
drive_siro ='/content/drive/MyDrive/dataset1/0/'#Google Driveの画像データフォルダ0のシロゾウリをマウント、取り出し
drive_midori ='/content/drive/MyDrive/dataset1/1/'#Google Driveの画像データフォルダ1のミドリゾウリをマウント、取り出し
image_size = 256 #256x256のサイズに指定
import os #osモジュール(os機能がpythonで扱えるようにする)
import cv2 #画像や動画を処理するオープンライブラリ
import numpy as np #python拡張モジュール
import matplotlib.pyplot as plt #グラフ可視化
from tensorflow.keras.preprocessing.image import ImageDataGenerator
#転移学習の際にDence、過学習予防、平滑化層、インプット、畳み込み層、プーリング層、活性化関数、バッチノーマライゼーションを使えるようインポート
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input,Conv2D, MaxPooling2D, Activation,BatchNormalization
from tensorflow.keras.applications.vgg16 import VGG16 #学習済モデルVGG16のインポート
from tensorflow.keras.models import Model, Sequential #線形モデルのインポート
from tensorflow.keras import optimizers #最適化関数のインポート
#os.listdir() で指定したファイル(siroとmidori)を取得
path_siro = [filename for filename in os.listdir(drive_siro) if not filename.startswith('.')]
path_midori = [filename for filename in os.listdir(drive_midori) if not filename.startswith('.')]
#ゾウリムシの画像を格納するリスト作成、データを代入
img_siro = []
img_midori = []
for i in range(len(path_siro)):
img = cv2.imread(drive_siro+ path_siro[i])#画像を読み込む
img = cv2.resize(img,(image_size,image_size))#画像をリサイズする
img_siro.append(img)#画像配列に画像を加える
for i in range(len(path_midori)):
img = cv2.imread(drive_midori+ path_midori[i])
img = cv2.resize(img,(image_size,image_size))
img_midori.append(img)
#np.arrayを用いてXに学習画像、yに正解ラベルを代入
X = np.array(img_siro + img_midori)
#正解ラベルの作成
y = np.array([0]*len(img_siro) + [1]*len(img_midori))
label_num = list(set(y))
#配列のラベルをシャッフルして学習の効率を上げる
rand_index = np.random.permutation(np.arange(len(X)))
X = X[rand_index]
y = y[rand_index]
#データを学習データ80%と検証データ20%に分けて用意
X_train = X[:int(len(X)*0.8)]
y_train = y[:int(len(y)*0.8)]
X_test = X[int(len(X)*0.8):]
y_test = y[int(len(y)*0.8):]ここからVGG16転移学習
#転移学習のモデルとしてVGG16を使用
#input_tensorはモデルの入力画像として用いるためtensorのオプション
#input_tersorとして入力の形を与える。
#include_topをFalseにし、VGGの特徴抽出部分のみを用いてそれ以降のモデルは自分で作成したモデルと結合
input_tensor = Input(shape=(image_size,image_size, 3))
vgg16 = VGG16(include_top=False, weights='imagenet', input_tensor=input_tensor)
#転移学習の自作モデルで下記コードを作成、活性化関数はsigmoidとreluを用いた。
#最後の2値分類のsigmoid以外ではreluを使うとaccuracyが高くなる。
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation="relu"))#sigmoid,relu#256
top_model.add(Dropout(0.5))#数値変更
top_model.add(Dense(128, activation='relu'))#64#128yoi
top_model.add(Dropout(0.5))
top_model.add(Dense(64, activation='relu'))#32#64yoi
top_model.add(Dropout(0.5))
#top_model.add(Dense(64, activation='relu'))#追加
#top_model.add(Dropout(0.5))#追加
#top_model.add(Dense(16, activation='relu'))#追加
#top_model.add(Dropout(0.5))#追加0.5
top_model.add(Dense(1, activation='sigmoid'))
#vggと自作のtop_modelを連結
model = Model(inputs=vgg16.input, outputs=top_model(vgg16.output))
#vgg16による特徴抽出部分の重みを崩れないように15層までに固定(以降に新しい層(top_model)が追加)#10,15,20では15層がaccuracyが高かった
for layer in model.layers[:15]:
layer.trainable = False
#コンパイル
model.compile(loss='binary_crossentropy',#mean_squared_error
optimizer=optimizers.Adagrad(lr=0.01, epsilon=None, decay=0.0),
metrics=['accuracy'])#二値分類の時にはaccuracyと書けばbinary_accuracyクラスが選択される
#optimizer=optimizers.Adam(lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0, amsgrad=False),
#optimizer=optimizers.SGD(lr=1e-4, momentum=0.9),
#optimizer=optimizers.RMSprop(lr=0.001, rho=0.9, epsilon=None, decay=0.0),
#optimizer=optimizers.Adadelta(lr=1.0, rho=0.95, epsilon=None, decay=0.0),
#optimizer=optimizers.Adamax(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=None, decay=0.0),
#optimizer=optimizers.Nadam(lr=0.002, beta_1=0.9, beta_2=0.999, epsilon=None, schedule_decay=0.004),
#モデルを定義後、損失関数であるloss、最適化アルゴリズムであるoptimizer、表示する精度指標を何にするかなどを指定してコンパイル
#lossはbinary_crossentropy、mean_squared_errorを試しbinary_crossentropyでのaccuracyが高かった。
#optimizerはAdam、SGD、Adagrad、RMSprop、Adadelta、Adamax、Nadamを試してAdagradでのaccuracyが高かった。
# EaelyStoppingの設定
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0.0,
patience=3,
)
# 学習の実行
history = model.fit(X_train, y_train, batch_size=16, epochs=150, verbose=1, validation_data=(X_test, y_test))#batch_size=16,32,50,64#epochs=50,60,100,150,200,250,300
score = model.evaluate(X_test, y_test, batch_size=16, verbose=0)
print('validation loss:{0[0]}\nvalidation accuracy:{0[1]}'.format(score))#可視化用グラフコード
#可視化
fig = plt.figure(figsize=(8,6))
ax1 = fig.add_subplot(2, 2, 1)
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
ax2 = fig.add_subplot(2, 2, 2)
plt.plot(history.history["loss"], label="loss", ls="-", marker="o")
plt.plot(history.history["val_loss"], label="val_loss", ls="-", marker="x")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()
Epoch 1/150
15/15 [==============================] - 14s 239ms/step - loss: 1012.6661 - accuracy: 0.5250 - val_loss: 0.9007 - val_accuracy: 0.4333
Epoch 2/150
15/15 [==============================] - 2s 133ms/step - loss: 0.9320 - accuracy: 0.5417 - val_loss: 0.6661 - val_accuracy: 0.5000
Epoch 3/150
15/15 [==============================] - 2s 132ms/step - loss: 0.7340 - accuracy: 0.5083 - val_loss: 0.6767 - val_accuracy: 0.5667
Epoch 149/150
15/15 [==============================] - 2s 140ms/step - loss: 0.0189 - accuracy: 0.9875 - val_loss: 1.5602 - val_accuracy: 0.8167
Epoch 150/150
15/15 [==============================] - 2s 140ms/step - loss: 0.0017 - accuracy: 1.0000 - val_loss: 1.4352 - val_accuracy: 0.8167
validation loss:1.4351829290390015
validation accuracy:0.8166666626930237結果の1例はこんな感じ

参考はこちら参考にさせて頂いたのはこちら
アプリケーション - Kerasドキュメント
VGG16モデルを使用してオリジナル写真の画像認識を行ってみる - AI人工知能テクノロジー (newtechnologylifestyle.net)]
2.5 画像推定
学習が終わったところで最後に画像の推定です。
まず完成したモデルをgoogle driveに保存します。
今回はVGG未使用バージョンのコードの方を記載しています。
classifier.save('zouri.h5')#モデルの保存続いてgoogle drive内に用意していたテストデータをマウントしてから取得してリスト作成します。
今回はなんとかシロを7枚、ミドリを3枚用意できました。
数増やしたいです。
そして学習したモデルを使って画像推定を行いました。
#画像推定用テストデータ準備
drive_test ='/content/drive/MyDrive/test1' #テスト用画像をマウントして取り出し
image_size = 256
path_test = [filename for filename in os.listdir(drive_test) if not filename.startswith('.')] #ファイル取得
img_test = [] #リスト作成
for i in range(len(path_test)):
img = cv2.imread(os.path.join(drive_test, path_test[i])) #os.path.joinでファイルパスを結合して画像を読み込む
img = cv2.resize(img,(image_size,image_size)) #画像をリサイズする
img_test.append(img) #画像配列に画像を加える
new_model = keras.models.load_model('zouri.h5') #保存した学習モデルの呼び出し
#テスト画像の推定
for i in img_test:
pred = new_model.predict(np.expand_dims(i, axis=0))#np.expand_dimsで画像の次元拡張をしてから、モデル予測
cls = int(np.round(pred)) #約分することで0か1かを表示
print("{} : {}".format(pred, cls))
#テスト画像の可視化(通常)
fig = plt.figure(figsize=(8,6))
fig.subplots_adjust(wspace=0, hspace=0)
for i in range(10):
x = img_test[i]
plt.subplot(2, 5, i+1)
b,g,r = cv2.split(x)
plt.imshow(img_test[i])
x = cv2.merge([r,g,b])
plt.xticks([]),plt.yticks([])
plt.imshow(x)
plt.suptitle("img_test1",fontsize=30)
plt.show()
#テスト画像の可視化(クロレラみやすい)
fig = plt.figure(figsize=(8,6))
fig.subplots_adjust(wspace=0, hspace=0)
for i in range(10):
plt.subplot(2, 5, i+1)
plt.imshow(img_test[i])
plt.xticks([]),plt.yticks([])
plt.suptitle("img_test2",fontsize=30)
plt.show()
推定の結果はこちら
1/1 [==============================] - 0s 270ms/step
[[0.02102672]] : 0
1/1 [==============================] - 0s 18ms/step
[[0.00383744]] : 0
1/1 [==============================] - 0s 17ms/step
[[0.00578805]] : 0
1/1 [==============================] - 0s 19ms/step
[[0.2946266]] : 0
1/1 [==============================] - 0s 18ms/step
[[0.00644493]] : 0
1/1 [==============================] - 0s 21ms/step
[[0.00824292]] : 0
1/1 [==============================] - 0s 18ms/step
[[0.05623814]] : 0
1/1 [==============================] - 0s 19ms/step
[[0.9823496]] : 1
1/1 [==============================] - 0s 18ms/step
[[0.99794704]] : 1
1/1 [==============================] - 0s 18ms/step
[[0.9905165]] : 1↑ちなみにこちら、GPUに制限かかっている時のものなので、GPU使えばもうちょっと早くなります。


0がシロ、1がミドリです。
図だと左上から右下までの順番で読み込まれていると思われます。
結果の表では、最後の3つが1と、残りは0と表示されていますね。
こちらもランタイムを動かすごとに結果違います。
一応今回はちゃんと見分けてくれている感じがいたします。良かったです。
image1は通常色に直したもの、image2はクロレラ見やすかったので、 b,g,r = cv2.split(x)とかは書いていないバージョンになります。
参考にさせて頂いたのはこちら
numpy.expand_dims — NumPy v1.23 マニュアル
[Python]os.pathの使い方(ファイルパスの結合、ファイル名取得、フォルダ名取得) - TeDokology (12-technology.com)
Python でパスを結合する - Python でパスの取得・操作 - Python の基本 - Python 入門 (keicode.com)
NumPy配列ndarrayに次元を追加するnp.newaxis, np.expand_dims() | note.nkmk.me
自前の保存したモデルを用いて画像を分類してみる。 - Qiita
3.まとめ(考察と今後の課題について)
今回はあくまで持っている画像を使ってという範囲内でしかありませんが、コンスタントにaccuracyが0.95以上、val_accuracyが0.80以上になるようにはコーディングできました。
ただ結果のブレがまだまだ大きく、改善しなければならないです。
まだまだ果てしない道のりが続いているように思えます。
次回からの改善していきたい点としては
①TensorFlow の ImageDataGeneratorを使って画像の水増しを行い、データ数を増やす。
②改めて撮影したものをデータに加えて検証。
(例えばミドリゾウリの体内のクロレラが1個、10個、20個・・・という様に分けたものを使った場合など)←この場合は今回のような2値分類ではなく多クラス分類をした方が良いのでしょうか?更に勉強しないといけません。
③各数値の変更、パラメーターの変更…等、再検証です。
epoch数などはそれなりに足りていて、画像のトリミングなども出来ていたのかもしれませんが、やり方を変えることでもっとうまく出来たり、accuracy等の数値を上げれるかも知れません。
試してみたいことが多いのに時間があまりないのが残念です。
ただ添削課題が終了したから終わりではなくて、時間を見つけながら、少しずつ改善していきたいと思います。
また今回は講師の方のアドバイスなしではここまでコーディングは出来ませんでした。
重ね重ね感謝しているのと同時に、まだまだ勉強不足なのを改めて実感しております。
スクールで教えて頂いたことを無駄にしないために少しずつでも復習して、更に知識を深めていけたらと思っております。
ここまで読んで頂き、誠にありがとうございました。
最後に・・・
今回、プライベートで事情があり休学制度も使わせて頂きながらも3か月間(実質は4か月間ですが)スクールの学習を進める事が出来たのは、ひとえに私の拙い質問でも親切丁寧に答えて下さったり、一緒に考えて下さった講師の方々のおかげです。
この場を借りて改めて厚くお礼を申し上げさせて頂きたいです。
本当にありがとうございました。
この記事が気に入ったらサポートをしてみませんか?