
機械学習を学び、愛猫判別のアプリを制作

はじめに
自己紹介:文系大学を卒業し、新卒で人材広告会社に就職。記事作成やページ作成、ディレクションなどの業務に携わり、現在勤務歴7年目。業務でExcel関数を使用したデータ処理、また、HTMLやマクロを使用したことはあるが、プログラミングの知識はほぼありません。
本記事の概要
本記事では、受講開始〜終了までの学習内容、成果物についてまとめています。プログラミング未経験だけどこれから勉強を始めてみたいという方に向けて、自分なりの学習方法や学んだこと、大変だったことを伝えられたらいいなと思います。
アイデミーでの学習振り返り
昼間は仕事で平日は平均20時帰宅だったので、基本的に平日は、朝と夜の30分〜2時間、土日は7時間程度学習していました。基本的には自分で調べて、それでも分からない部分はSlackやカウンセリングで質問することで、必ず解消することができました。不明点を解消したり、コードの実行を積み重ねていくと段々自信につながり、どんどん楽しくなっていきました。
〜1ヶ月目〜
【python入門】演算・変数・型・条件分岐・基本文法など、pythonの基礎的な部分を学びました。ここでの課題は二分探索法(バイナリーサーチ)を用いて探索を行うプログラムの作成を行いました。
【Numpy基礎】数値データの配列を扱うのに便利なパッケージ「Numpy」を使って計算や処理を行うための基礎を学びました。ここでの課題は2枚の画像の差分を計算するものでした。文系の私にとっては、Numpy基礎を理解するのにすごく時間がかかりました。ここらへんで「あ、やべ、まず数学の基礎を勉強した方がいいかも」と思い、書籍で勉強を始めます。
【Pandas基礎】Numpyはデータを数学的な行列で扱う一方、Pandasは一般的なデータベース(数値以外の文字列データなどの表計算)で行える操作が実行でき、ここでは基礎を学びました。
【Matplotlib基礎】データを可視化するための様々なグラフの作成方法を学びました。ここでの課題はモンテカルロ法(乱数を用いて何らかの値を見積もる方法)による円周率の推定を行い、散布図で描画しました。
〜2ヶ月目〜
【データクレンジング】機械学習モデルにデータを読み込ませるための、lambda式による計算やOpenCVの基礎を学びました。課題では、画像を水増しする関数を作成しました。
【機械学習概論】人工知能と機械学習についての説明や、教師あり・なし学習、分類・回帰などの機械学習の各手法について学習しました。「いよいよでっせ〜」という感じが教材から伝わってきたので、ワクワクしました。
【教師あり学習(分類)】正解ラベル付きの学習データからモデルを学習させ、未知のデータに対して予測を行う教師あり学習について学びました。ロジスティック回帰などの様々な手法やハイパーパラメーターによる調整方法を学習し、手書き数字の認識・分類をするための学習機をより高い精度で作成する という課題に取り組みました。
【スクレイピング入門】WEBページから必要なデータを抜き出していく作業について学びました。エンコードについても学習し、「あれ?ITの基礎も全然ないやあああ」と思い、ここらへんからITパスポートの勉強を始めました。課題ではBeautiful Soupを使ったスクレイピングによるデータセット作りを行いました。
〜3ヶ月目〜
【ディープラーニング基礎】深層学習とは?の説明から始まり、tf.kerasを使ってニューラルネットワークモデルを実装し、手書き数字の分類を行いました。ここでの課題はBoston house-pricesデータセットを使って「住宅の価格予測問題」について取り組みました。正直最初は全く意味が分からなかったのですが・・、とりあえず、データ準備→モデル構築→モデル学習させる→精度を評価するっていうことを理解して、そういうもんだ と自分自身に言い聞かせ次に進みました・・。
【男女識別(深層学習発展)】VGG 16を使って転移学習を学習し、課題では写真に映る人物が男性か女性かを判別するモデルを作成しました。正解率は70%以上を目指せとのことだったので、最適化関数を変えてみたりエポック数を増やしてみたりと、自分で色々調整してみました。結果は正解率67%で70%に達しませんでした。正解率の推移を見ると70%をすぎた後に低下する現象がみられたので、過学習を起こしていたことが原因ではないかと考えます。より多くの訓練用データを用いて汎化させたり、ドロップアウトの様な手法を使って過学習を防ぐことで、正解率をあげることができたのではないかと推測しています。また、過学習防止の戦略として「重みの正則化」というものもある様なので今後実践してようと思いました。(ネットワークの損失関数に重みを加えることで行われる手法)
〜4ヶ月目〜
【Flask入門のためのHTML &CSS】HTML、CSSの基礎を学びました。
【Flask入門】アプリケーションソフトを開発する際に必要とされる機能をまとめて整えてくれている枠組み・雛形を簡単に構築できるウェブアプリケーションフレームワークの「Flask」について学習しました。また、Herokuの設定やデプロイについても学び、初めてPCのターミナルにて作業を行いました。
〜5ヶ月目〜
Aidemyの講座で学習した内容を元に、自作アプリを作成しました。
【アプリの概要】
機能:画像から黒猫かグレーの猫かを識別します。
作成の経緯:旦那さんの実家で飼っている2匹の猫が黒とグレーなので、2匹を判別して「はにゃ〜」と癒されたかったという単純な理由です。
【環境】
・macOS Catalina 10.15.7
・Python 3.8
・Tensorflow 2.4.1
・Sublime Text
【アプリ制作の流れ】
1.FlickrAPIを使って画像を収集
まずは下記サイトを参考にして、FlickrAPIに登録。yahoo.comのアドレスを入力と書いてありますが、普通にGmailアドレスでも登録できました。
http://ykubot.com/2017/11/05/flickr-api/
API KeyとSecret Keyを取得できたら、下記コードを実行し、画像を収集します。
import os
import time
import traceback
import flickrapi
from urllib.request import urlretrieve
import sys
from retry import retry
flickr_api_key = xxxxxx
secret_key = xxxxxx
wait_time = 1
def get_photos(cat_name):
#保存フォルダの指定
savedir = './new-image-data/' + cat_name
flicker = flickrapi.FlickrAPI(flickr_api_key, secret_key, format='parsed-json')
response = flicker.photos.search(
text=cat_name,
per_page=300,
media='photos',
sort='relevance',
safe_search=1,
extras='url_q,license'
)
photos = response['photos']
for i, photo in enumerate(photos["photo"]):
try:
url_q = photo['url_q']
except:
print("取得に失敗")
continue
filepath = savedir + '/' + photo['id'] + '.jpg'
#同じファイルが存在していた場合スキップ
if os.path.exists(filepath): continue
#url_qの画像をfilepathに保存する
urlretrieve(url_q, filepath)
#1秒おく
time.sleep(wait_time)
get_photos("Black_cat")
get_photos("Russian_Blue")黒猫とグレー猫(ロシアンブルー )それぞれ300枚くらいずつ取得し、ファイルに保存しました。猫以外の画像なども含まれてしまっているので、不要な画像をファイルから削除し、それぞれ150枚位ずつになりました(少ない、、あせあせ)。
2.水増し
「150枚じゃやっぱ少ないよなあ」とあせあせしていたので、水増しして画像を増やしてみます。画像の水増しにKerasのImage Data Generatorを使用し、1枚の画像から新たに9枚の画像を作成します。
from PIL import Image
import os,glob
import numpy as np
from sklearn import model_selection
from keras.preprocessing.image import ImageDataGenerator, array_to_img
classes = ["Black_cat","Russian_Blue"]
num_classes = len(classes)
#画像の読み込み
X_train = []
X_test = []
Y_train = []
Y_test = []
datagen = ImageDataGenerator(
#-20°〜20°の範囲でランダムに回転する。
rotation_range=20,
#ランダムで上下反転する
horizontal_flip=True,
#ランダムに左右反転する
vertical_flip=True,
#ランダムに垂直シフトする
height_shift_range=0.1,
#ランダムに水平シフトする
width_shift_range=0.1,
)
#それぞれのファイルごとにループさせる
for index, classlabel in enumerate(classes):
photos_dir = "./new-image-data/" + classlabel
#jpg形式の画像データを保存
files = glob.glob(photos_dir + "/*.jpg")
#フォルダ内の全ての画像を1つずつ渡す
for i, file in enumerate(files):
#画像データが150を超えたらループを抜ける
if i >= 150: break
image = Image.open(file)
image = image.convert("RGB")
#画像データを50×50に変換
image = image.resize((50, 50))
#画像から配列に変換
data = np.asarray(image)画像を配列に変換して、学習用・評価用のデータに分け、Numpy形式で保存します。
#トレーニング用データだけ水増し
#水増し前にテスト用データを保存
if i <45:
X_test.append(data)
Y_test.append(index)
continue
#残りのデータを3次元から4次元配列に変更する
data = data.reshape((1,) + data.shape)
#画像を9枚生成する
g = datagen.flow(data, batch_size=1)
for i in range(9):
batches = g.next()
g_img = batches[0].astype(np.uint8)
X_train.append(g_img)
Y_train.append(index)
X_train = np.array(X_train)
X_test = np.array(X_test)
y_train = np.array(Y_train)
y_test = np.array(Y_test)
xy =(X_train,X_test,y_train,y_test)
np.save("./cat_augment.npy", xy)3.モデルを定義し、学習させる
VGG 16を使って転移学習します。モデルは下記となります。
from keras import optimizers
from keras.applications.vgg16 import VGG16
from keras.layers import Dense, Dropout, Flatten, Input
from keras.models import Model, Sequential
from keras.utils.np_utils import to_categorical
from keras.utils import np_utils
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
import matplotlib.pyplot as plt
import keras.callbacks
classes = ["Black_cat","Russian_Blue"]
num_classes = len(classes)
image_size = 50
X_train,X_test,y_train,y_test = np.load("./cat_augment.npy",allow_pickle=True)
#画像ファイルの正規化
X_train = X_train.astype("float") / 256
X_test = X_test.astype("float") / 256
#教師ラベルをone_hot vectorにする
y_train = np_utils.to_categorical(y_train,num_classes)
y_test = np_utils.to_categorical(y_test,num_classes)
input_tensor = Input(shape=(50,50,3))
vgg16 = VGG16(include_top=False, weights="imagenet", input_tensor=input_tensor)
top_model = Sequential()
top_model.add(Flatten(input_shape=vgg16.output_shape[1:]))
top_model.add(Dense(256, activation="relu"))
top_model.add(Dropout(0.5))
top_model.add(Dense(2, activation="softmax"))
model=Model(inputs=vgg16.input,outputs=top_model(vgg16.output))
for layer in model.layers[:19]:
layer.trainable = False
model.compile(loss="categorical_crossentropy", optimizer=optimizers.SGD(lr=1e-4, momentum=0.9), metrics=["accuracy"])
history = model.fit(X_train, y_train, validation_data=(X_test, y_test), batch_size=32, epochs=20)
model.save("./new_cat_model.h5")
scores = model.evaluate(X_test, y_test, verbose=1)
print("Test loss:", scores[0])
print("Test accuracy:", scores[1])
model.summary()
plt.plot(history.history["accuracy"], label="accuracy", ls="-", marker="o")
plt.plot(history.history["val_accuracy"], label="val_accuracy", ls="-", marker="x")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(loc="best")
plt.show()学習結果
正解率は下記となりました。
![]()
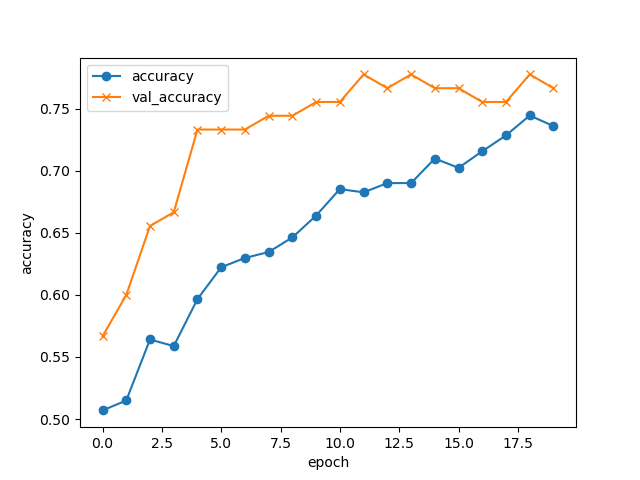
正解率は7割ほどとなりました。正解率が高くない原因を自分なりに考えてみました。原因の1つ目は、epoch数が少なすぎたこと、2つ目は画像から「猫」だけを抽出できていなかったのではないかということです。上記グラフは上昇途中の様な挙動に見られるので、epoch数を上げたらもっと高い正解率を出せたのかもしれません。また、水増し工程の前に不要画像の削除を行いましたが、物体の抽出・切り取りなどは行っておらず、モデルを学習させる際に画像内の「猫」以外の要素も学習してしまうことで精度が落ちたのではないかと考察します。
▼HTML
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8" />
<meta name="viwport" content="device-width, initial-scale-1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>Cat Classifier</title>
<link rel="stylesheet" href="./static/stylesheet.css" />
</head>
<body>
<header>
<img
class="header_img"
/>
<a class="header-logo" href="#">CatAI</a>
</header>
<div class="main">
<h2>CatAIが送信された画像が黒猫かグレーの猫か識別します</h2>
<p>画像を送信して下さい</p>
<form method="POST" enctype="multipart/form-data">
<input class="file_choose" type="file" name="file" />
<input class="btn" value="submit!" type="submit" />
</form>
<div class="answer">{{answer}}</div>
</div>
<footer>
<img
class="footer_img"
/>
<small>© 2021</small>
</footer>
</body>
</html>▼CSS
header {
background-color: #C0C0C0;
height: 60px;
margin: -8px;
display: flex;
flex-direction: row-reverse;
justify-content: space-between;
}
.header-logo {
color: #C0C0C0;
font-size: 25px;
margin: 15px 25px;
}
.header_img {
height: 25px;
margin: 15px 25px;
}
.main {
height: 370px;
}
h2 {
color: #444444;
margin: 90px 0px;
text-align: center;
}
p {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
.answer {
color: #444444;
margin: 70px 0px 30px 0px;
text-align: center;
}
form {
text-align: center;
}
footer {
background-color: #000000;
height: 110px;
margin: -8px;
position: relative;
}
.footer_img {
height: 25px;
margin: 15px 2px;
}
small {
margin: 15px 25px;
position: absolute;
left: 0;
bottom: 0;
}4.Flaskを利用してHerokuへ作成したアプリをデプロイ
cat_app(フォルダ)
├ templates(フォルダ)
|└ newcat.html
├ static(フォルダ)
|└ stylesheet.css
├ Procfile
├ requirements.txt
├ runtime.txt
├ new_cat_model.h5(保存した学習モデル)
├ cat_up_load.py
▼cat_up_load.py (アップロードされた画像を学習済モデルに渡して分類結果を返します。)
import os
from flask import Flask, request, redirect, render_template, flash
from werkzeug.utils import secure_filename
from tensorflow.keras.models import Sequential, load_model
from tensorflow.keras.preprocessing import image
import numpy as np
#分類したいクラス名をリストに格納
classes = ["黒猫","グレーの猫"]
#image_sizeには学習に用いだ画像のサイズを渡す
image_size = 50
#アップロードされた画像を保存するフォルダ名を渡す
UPLOAD_FOLDER = "uploads"
#アップロードを許可する拡張子を指定
ALLOWED_EXTENSIONS = set(["png", "jpg", "jpeg"])
app = Flask(__name__)
#アップロードされたファイルの拡張子のチェック
#andの前後の2つの条件を満たす時Trueを返す
#1つ目の条件"." in filenameは、変数filenameの中に「.」という文字が存在するか確認
#2つ目の条件filename.rsplit(".",1)[1].lower()in ALOOWED_EXTENSIONSは変数filenameの.より後ろの文字列がALLOWED_EXTENSIONSのどれかに該当するか確認
def allowed_file(filename):
return "." in filename and filename.rsplit(".", 1)[1].lower()in ALLOWED_EXTENSIONS
#学習済のモデルをロードする
model = load_model("./new_cat_model.h5")
#requestはウェブ上のフォームから送信したデータを扱う関数
@app.route("/", methods=["GET", "POST"])
#POSTリクエストにファイルデータが含まれているか、ファイルにファイル名があるかをチェック
def upload_file():
if request.method == "POST":
if "file" not in request.files:
flash("ファイルがありません")
return redirect(request.url)
file = request.files["file"]
if file.filename == "":
flash("ファイルがありません")
return redirect(request.url)
#アップロードされたファイルの拡張子をチェック
#sequre_filename()でファイル名にきけんな文字列がある場合に無効化(サニタイズ)する
if file and allowed_file(file.filename):
filename = secure_filename(file.filename)
#引数に与えられたパスをOSに応じて結合し、そのパスにアップロードされた画像を保存する
file.save(os.path.join(UPLOAD_FOLDER,filename))
#保存先をfilepathに格納する
filepath = os.path.join(UPLOAD_FOLDER, filename)
img = image.load_img(filepath, grayscale=False, target_size=(image_size, image_size))
img = image.img_to_array(img)
data = np.array([img])
result =model.predict(data)[0]
predicted = result.argmax()
print(result)
pred_answer = "これは" + classes[predicted] + "です"
#cat.htmlに書いたanswerにpred_answerを代入することができる
return render_template("newcat.html", answer=pred_answer)
#POSTリクエストがなされない時、newcat.htmlのanswerには何も表示しない
return render_template("newcat.html", answer="")
if __name__ == "__main__":
port = int(os.environ.get("PORT", 8080))
app.run(host='0.0.0.0',port=port)5.アプリの利用
▼判別アプリ
https://catapp20210711.herokuapp.com/
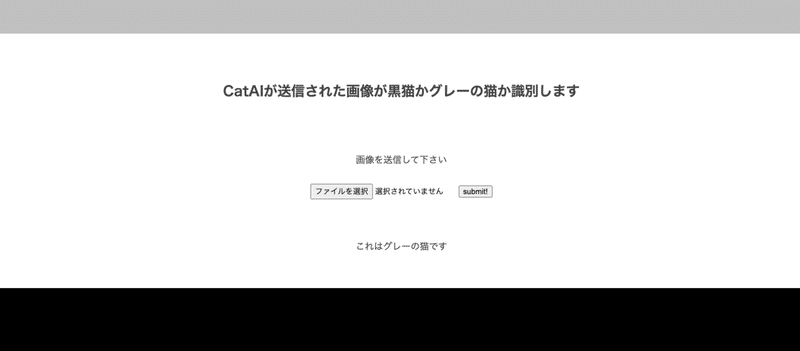
画像を入れてsubmitで実行後、結果が返ります・・が、精度が低く思う様に正確な結果が得られなかったので、3で考察した点を元に改修してみようと思います。また、今回対象ではない画像の結果も返しているので、対象外の画像の判定も必要だと感じました。
6.最後に
全くの未経験からなんとかアプリを作成することができ、まずは達成感を感じています。振り返ってみると、コードを書いている時間よりもエラーを解決させたり、そのための方法を調べたりする時間の方が多く、あっという間に時間が過ぎました。なかなかエラー対処が出来ない時はしんどかったですが、出来ることが増えていく度にあれもこれもやってみたいという興味が湧いたので、今後もアプリを自作したり、楽しくpythonを学んでいきたいと思います。最後に、私の拙い質問にも丁寧にお答えいただいたチューターの皆様に大変感謝しております。ありがとうございました!
この記事が気に入ったらサポートをしてみませんか?