
CPU業界の変化を読み解く(前編・CPUの技術的背景とその歴史):思惟かねの気まぐれニュース解説

思惟かねがお届けする不定期コラム、思惟かねの気まぐれニュース解説のお時間がやってまいりました。
久しぶりの更新となる今回は「CPUと半導体業界、そのトレンド」をテーマにお届けしようと思います。
さて、今回の記事の入口となるニュースはこちら。
PCにちょっと詳しい人ならその名を知らぬ人はいないCPUメーカーの2大巨頭であるIntelとAMD。その2020年第2四半期の決算報告が見事に明暗分かれたというニュースです。
AMDは主力のCPUブランド、Ryzenが好評でノートPCへの採用が増え、PS5への採用も発表されるなど絶好調そのもの。サーバー用CPU・EPYCの躍進も続き、昨今の情勢による巣ごもり需要もあって売上は前年比45%増、純利益は4.5倍と業績を大きく伸ばしています。ちなみに私事ながら私も先日、Ryzenを採用したノートPCを買ったばかりです。
ここ数年、PCを自作する自作erの間でもコストパフォーマンスの高さからRyzenの名前とともにAMDの人気は高まっていましたが、いよいよ一般的なPCユーザ、そしてサーバーやゲーム機などにも採用が進み、AMDの大躍進が一過性のブームでないことが明白になってきました。
一方で、CPUといえばIntelと誰もが口を揃えたはずの王者・Intelは、同じく巣ごもり需要のため増収増益の結果でありながら、株価を大きく下げるという結果となりました。
見事に明暗分かれたこのIntelとAMD、両社の差の背景には何があるのでしょうか?
ここでキーワードとなってくるのが「7nmプロセス」そして「ファブレス」という単語です。
この意味をよく理解するには、CPUの技術とその歴史を読み解かねばなりません。というわけで、今回はこのニュースを読み解くため、CPUを始めとする半導体業界の技術革新と変遷の歴史を30年ほどさかのぼり、その技術の基本的な部分を解説しながら、「7nmプロセス」そして「ファブレス」という現在につながるキーワードにつながる糸を手繰ってみようと思います。
相変わらず迂遠でニッチでディープなこのコラムですが、よろしければお付き合いください。
(※今回は記事が長くなりすぎたので前後編で分割しています。前編は主にCPUの高性能化の歴史とその技術的背景についてのお話です)
CPUの高性能化の歴史:集積化と動作周波数
CPU(Central Processing Unit)はコンピュータの情報を処理する、PCの頭脳というべき部品です。少しでも詳しい方なら、CPUの性能がPCの性能を大きく左右することについては言うまでもないでしょう。
さて、現代のCPUのご先祖といえる半導体を集積し1チップ化したマイクロプロセッサが登場したのが1970年代のこと。これ以前は複数のICを組み合わせてCPUのような機能を実現していましたが、これをさらに集積したもの(いわゆるLSI)がこの頃から出てきます。

世界初の商用マイクロプロセッサであるIntel 4004
そこから現在2020年に至るまで、1チップで様々な処理を可能にするという点では変わらないものの、より高度化・大規模化したCPUは天文学的なまでの性能向上を果たしています。

AMD Ryzen 7 3700X (2019)
Smial (トーク) - 投稿者自身による作品, FAL, https://commons.wikimedia.org/w/index.php?curid=87410690による
さて、この半世紀の間の性能向上とはどれほどのものでしょうか?
例えば、上に取り上げたIntel 4004とAMD Ryzen7 3700Xを比べてみると…
発売:1971年 (Intel 4004) vs 2019年 (Ryzen7 3700X)
チップサイズ:3mm×4mm ⇒ 40mm×40mm(133倍)
トランジスタ数:2300個 ⇒ 60億個(260万倍)
動作周波数:最大741kHz ⇒ 最大4.4GHz(6000倍)
プロセス・ルール:10μm ⇒ 7nm(1/1400倍)
…と、48年に渡る技術開発の結果、もはや数字が大きすぎてよく分からないほどの恐竜的進化を遂げています。
例えば、ICの性能の一つの指標となるトランジスタ数は165万倍と、同じ人間が作ったものとは思えないほどの大きな変化をしています。チップ自体が大型化していることを差し引いて面積密度で考えても2万倍ほどになっているのが分かります。
さて、ここでCPUの性能向上を語る上で欠かせないキーワードが3つ出てきました。「トランジスタ数」と「動作周波数」、そして「プロセス・ルール」です。
一見無関係に見えるこの3者は、実は密接な関係にあるのですが、特にその中心になるプロセス・ルールについては話がかなり長くなるので、まずは分かりやすい所から解説していきます。
まずはトランジスタ数から触れていきましょう。
一般に、CPUの処理能力は集積された半導体素子=トランジスタの数に大きく左右されます。もちろん設計そのものの優劣も性能には大きく影響しますが、CPUの処理能力が爆発的に増大したのは、やはりこのトランジスタの数が大きく増えたことが決定的な要因です。
(トランジスタについては後ほどまた詳説しますが、ここではCPUに使う部品ぐらいに理解して貰えば十分です)
実際、Intel 4004というはるか昔のCPUを持ち出すまでもなく、CPUの性能向上の歴史は、そのままトランジスタ数の増加の歴史でもあります。
例えば、1971年のIntel 4004では2300個だったトランジスタ数は、1979年、シャープのX68000などで有名なMotorola 68000では68000個に。さらに1985年には代表的な初期の32bitCPUであるIntel 80836が登場し、これは27.5万個であったのが、1993年の初代Intel Pentiumでは310万個とついにミリオンのオーダーに到達。
2000年に登場した初代Intel Pentium4ではさらに1桁増えて4200万個、2008年の初代Intel Core i7では8.7億個とついに億の単位に。そして2019年のRyzen7 3900Xでは60億個…。ちなみに、今やどんなスマートフォンのCPUでも数十億個のトランジスタが乗っています。
こうしたトランジスタ数の指数関数的な増加を予言した最も有名な法則が、ムーアの法則(Moore's Law)と呼ばれる経験則です。
1965年と半世紀以上前に提唱されながら、今なお度々引き合いに出されるこの法則は「集積回路上のトランジスタ数が1.5年ごとに倍になる(実際には2年ごと)」というものです。

ムーアの法則を表したトランジスタ数と時間の相関グラフ
先程かいつまんで紹介した10年も経てば桁が一つ増えるというCPUトランジスタ数の指数関数的な増加は、まさにムーアの法則そのものです。そして乱暴に言えば、その分だけ処理できる情報量が増えているということでもあり、トランジスタの集積化が性能向上の決め手の一つというのは間違いないでしょう。
さて、トランジスタの集積化と並んで性能向上に大きな役割を果たして「いた」のが、2つ目のキーワード、動作周波数の向上です。
動作周波数はクロック周波数とも呼ばれ、CPUがどれほど細かい時間の単位(クロック)で処理ができるか…ざっくり言えばCPUが1秒間に情報を処理できる回数を表します。Intel 4004の741kHzは1秒に74万回(741×10^3回)処理するタイミングがあるということであり、Ryzen7の4.4GHzとはこれが44億回であることを意味します。これは原理的に6000倍の早さで情報処理が可能というということ。ゆえにクロックは基本的に早ければ早いほどよいといえます。
特に一昔前の方なら、動作周波数=CPUの性能というイメージが強いでしょうから、これは直感的に飲み込みやすいでしょう。
実際のところ、これは当時のIntelのイメージ戦略的な要素も大きかったそうで、動作周波数で劣りながらライバルのIntel Pentium4を超える性能を発揮していたAMD Athlonなどがこの好例として挙げられます。
また近年は動作周波数が頭打ちとなり(これについては後述)、代わってマルチコアCPUが主流となったことで潮目は変わりつつあります。動作周波数を、性能向上に大きな役割を果たして「いた」と私が表現した理由です。
もっとも、先ほどトランジスタ数の項で取り上げたCPUの動作周波数を見てみると、
1971年 Intel 4004:741kHz
1979年 Motorola 68000:20MHz(=20000kHz)
1985年 Intel 80836:40MHz
1993年 初代Intel Pentium:60MHz
2000年 初代Intel Pentium4:2GHz(=2000MHz=2000000kHz)
2008年 初代Intel Core i7:3.6GHz
2019年 Ryzen7 3900X:4.4GHz
こうしてみると、かつてのこととはいえ間違いなくCPUの長期的な技術トレンドの一つは動作周波数の高速化にあったことが分かりますね。
CPUの高性能化の歴史:プロセス・ルール
さて、前項ではCPUの性能向上にはトラジスタ数の増加(集積化)と、動作周波数の高速化が大きな役割を果たしていたことを説明しました。
では、最後のキーワードであるプロセス・ルールとはなんでしょう?
先ほども言ったとおり、これはトランジスタの集積化、そして動作周波数とも密接な関わりがあります。
プロセス・ルール(Process size)とは、半導体を作る上での「細かさ」の指標です。冒頭に取り上げたニュースを読み解く上で重要な「7nmプロセス」というキーワードは、まさにこのプロセス・ルールが7nmであり、その分、微細な構造を作ることができるということを意味します。
…ちなみに誤解されがちなのですが、7nmプロセスというのは実はCPUのどこかが7nmであるということではありません。
350、250、180、130、90、65、45、32、22、14、10、7
この数字が何を指しているか?というのはさておき、数列として見た時、勘のいい方はこれが等比数列に近いことに気づくでしょう。この数字は順におよそ0.7倍になりながら続いています。
そしてこの数列の最後の数字である7は、実は7nmプロセスを表しています。つまりこれは、7nmプロセス以前のプロセス・ルールを一覧にした数字なのです。この数学的規則正しさが、逆説的に「7nm」などといったプロセス・ルールが象徴的な数字でしかないことを示しています。
では、プロセス・ルールに具体的な意味がないのかといえば、そういう訳でもありません。2018年頃まではプロセス・ルールはCPU内の配線ピッチ(配線と配線の間隔)とほぼ比例関係にあり、それ以前の2004~2012年頃まではゲート長(トランジスタのドレインとソースの間隔)がプロセス・ルールとほぼ一致していました。
つまり、かつては実効的な意味のあった、言ってみれば歴史的な指標であり、かつての名残として使われている値がこのプロセス・ルールといえます。今なおこの数字が使われるのは、ひとえに専門家でない人にも分かりやすいから。それ以上の意味は実はないのです。
…さて、話がそれましたが、このプロセス・ルールがトランジスタの集積化、そして動作周波数とどう関係してくるのでしょうか?
(ここではプロセス・ルールが実寸法と乖離してくる以前の、もう少し原則的なお話をします。プロセス・ルールが半分=すべての回路の寸法が半分と考えてください)
前者のトランジスタの集積化については、おそらく簡単でしょう。
プロセス・ルールが半分=トランジスタの大きさが半分になるということは、面積は0.5×0.5=0.25倍(1/4)になります。つまり、同じ面積に4倍のトランジスタを詰め込めるということです。
実際、1971年のCPUのご先祖Intel 4004のプロセス・ルールは10μmであったのが、1993年の初代Pentiumでは0.8μmと1/12.5倍となった結果、面積あたりのトランジスタ数は60倍ほどに向上。2000年のPentium4はさらにプロセス・ルールが180nm(0.18μm)と1/4.4倍になった結果、面積あたりのトランジスタ数は33倍に向上しています。色々な要素が絡むため綺麗に2乗の関係にはなりませんが、やはりプロセス・ルールが集積化に決定的な役割を果たしているのが分かります。
他方、プロセス・ルールの微細化によって、なぜ動作周波数が向上するのかについては少しだけ話が難しくなります。
まず前提として、トランジスタ(正確にはICに用いるMOSFET)は電圧によって動作する電気素子です。これはゲートと呼ばれる部位に電圧をかけることで、ソースとドレンと呼ばれる電極間に電気が流れるか流れないかということを制御できる(導通したり絶縁したりできる=半導体)というのがその機能です。このオン・オフ機能を無数に組み合わせることで、CPUはその能力を実現しています。
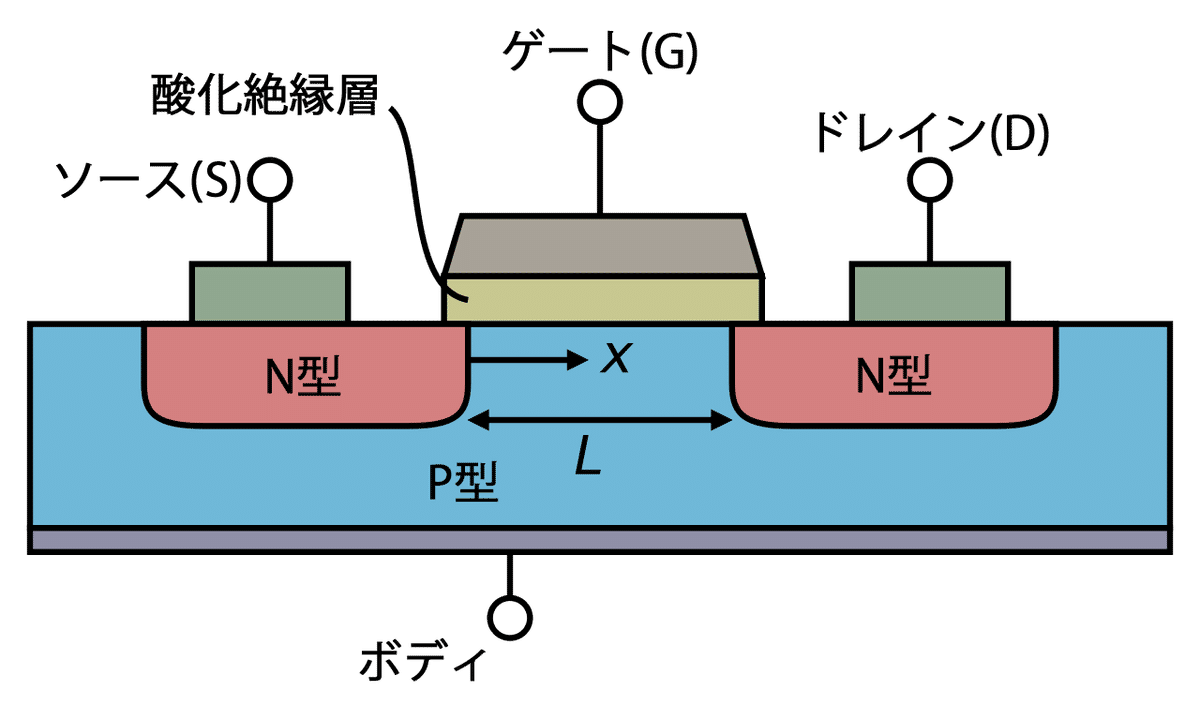
MOSFETの断面図 (wikipediaより)
さて、プロセス・ルールが半分になった時、これがトランジスタにどう影響するのでしょう?
実はMOSFETというのは、ゲート・ソース(ドレイン)間に絶縁膜を挟んでいる、コンデンサそのものの構造なので、元から静電容量(寄生容量)を持っています。このためMOSFETが動作する、つまりオン・オフを切り替えるというのはコンデンサを充放電することに他ならないため、これには一定の時間が必要となります。結果、動作速度(動作周波数)の上限が自ずと生じてきます。
しかしプロセス・ルールが半分になり、トランジスタの大きさが半分になると?
コンデンサの容量はC=ε×S/d(下記記事参照)で表され、大きさが半分になると面積(S)が1/4になりますが、ゲート酸化膜の膜圧(d)も1/2になるので、トランジスタの寄生容量(C)は差し引き1/2になります。
ちなみにこの時、トランジスタが小さくなった分、電圧が過剰になってしまうので、合わせて電圧を1/2倍に(電場が一定になるように)します。
すると、スイッチングのラグの原因になる寄生容量は1/2になるので動作周波数は2倍に上げることができる。結果、プロセス・ルールが1/2になれば動作周波数は2倍にできるというわけです。一方で電圧が1/2になっているので、2×1/2×(1/2)^2=1/4、つまり消費電力は1/4に低下することになります。
この魔法のようなルールをスケーリング則、または提唱者の名前からデナード則と呼びます。
まとめると、プロセス・ルールが半分になれば、トランジスタ密度は4倍、動作周波数は2倍にまで高めることができる。その結果、大幅に処理能力が向上する…というわけです。トランジスタ数の増加も、動作周波数の向上もこのプロセス・ルールの微細化の恩恵を受けてのことなのです。
CPUの性能の飛躍的な向上は、プロセス・ルールの微細化と切っても切れない関係にあるのですね。
他にもあるプロセス・ルール微細化のメリット
実はプロセス・ルールの微細化には、CPUの性能向上以外にも、先ほど少し触れた消費電力の低減をはじめ様々なメリットがあります。その一つが、歩留まりの改善です。
先ほど、CPUの性能向上にはトランジスタの数が決定的な役割を果たす、というお話をしました。
賢明な読者の皆さんには「それならCPUを大きくしてでも、沢山のトランジスタを積めば高性能なCPUができるのでは?」ということを疑問に思われた方もいたでしょう。実はこれは、正しいけど実際にはできないことなのです。
CPUは、実際はウェハーと呼ばれる超高純度シリコンの一枚板を加工することで作られます。フォトリソグラフィと呼ばれる光を用いた転写・加工技術によって、この上にCPUを何十個もまとめて作り出すわけです。

ウェハーと作成途中の半導体の様子 (Wikipediaより)
しかしCPUの配線というのは10nm単位と非常に微細なので、このウェハーの上にちょっとでもほこりや付着物(例えば大気中を漂っているホコリはμm単位=数千nmの大きさ)があると、たちまちその場所のCPUは断線したりショートしたりして不良品になってしまいます。
そうした不良品は検査によって後から取り除くしかないのですが、その分無駄にお金がかかるわけです。こうした不良品がどれだけ少なく、良品が多くなるかを歩留まりといい、半導体を製造する上ではこの歩留まりが常に大きなネックになります。
このような不良品を最小限にし、歩留まりを良くするため、CPUを始め半導体はクリーンルームと呼ばれる極めてほこりの少ない清浄な環境で製造されます。

半導体工場のクリーンルームの様子
Rudolf Simon, M+W Group GmbH - now Exyte AG, Stuttgart, Germany - 原版の投稿者自身による作品, CC BY-SA 2.0 de, https://commons.wikimedia.org/w/index.php?curid=3559555による
それでもほこりをゼロにはできないので、ある程度の確率で付着物による欠陥がウェハー上に生じます。
そして大量のトランジスタを積むためにCPUのサイズ(ダイサイズ)を大きくするということは、この欠陥がCPU内に含まれる確率が上がる=歩留まりが悪化するということを意味するわけですね。その分価格も跳ね上がり、現実的に売り物にならなくなってしまうわけです。
加えて、CPUの製造コストはウェハー1枚あたりでおおよそ決まり、1枚あたりから作れるCPUの個数とはあまり関係ありません。つまりCPUを小さくして1枚のウェハーから取れる個数を増やすことは、歩留まりの改善と直接的な製造コストの低減という二重の意味があります。
極端に大きくて高性能なCPUが存在しないのはこういうわけです。高性能化には、プロセス・ルールを微細化することで、サイズを大きくしないままにトランジスタ数を増やすことが現実的には必要になってくるのです。
見えてきたCPUの限界とこの20年の動向
しかしこうしたプロセス・ルールの微細化によるCPUの性能向上は、いまや様々な技術的限界に直面しています。プロセス・ルールを小さくしていけばトランジスタ数、動作周波数、歩留まり、消費電力といったあらゆるものが良くなったのも今は昔。
ここまでとは打って変わって、現在のCPUが直面している技術的な課題について触れていきましょう。
まず最も早くCPUが悩まされたのが、動作周波数の限界です。
この背景にあるのが、微細化の進展により明らかになってきたMOSFETのジレンマです。簡単に言うと、デナード則に従って微細化していくと、ある点で従来どおり電圧を下げると動作周波数が上がらなくなる現象が生じてきます(原因はMOSFET内のドレイン電流が大きく減少してくるため)。
プロセス・ルールが130nmに到達した第二世代のIntel Pentium4(Northwood)や第二世代AMD Athlon XP(Thoroughbred)の世代でこの問題は顕在化しました。
しかし電圧を上げると消費電力が悪化し、かといって閾値電圧を引き下げてもサブスレッショルド電流(リーク電流)により待機電力が増加と、にっちもさっちも行きません。
結局いずれにせよ、性能向上のためにCPUは消費電力の増加を甘受するしかありませんでした。
しかしこの消費電力の増加は、熱問題というより困難な課題を生むことに。
電気回路では、消費された電力はそのまま熱になるので、消費電力の増加はそのまま発熱の増加を意味します。そして半導体は熱に弱い(せいぜい150℃程度)ため、自ずと消費電力増と引き換えにした動作周波数の向上は早々に限界を迎えます。
これの象徴が2004年に報じられたIntel Pentium4の4GHzモデル(プロセス・ルール65nm)開発中止のニュースでした。それから15年が経った現在もなお市販のCPUで動作周波数が5GHzを超えるものはありません。動作周波数による性能向上の歩みは、こうして2000年代初頭に真っ先に挫折を余儀なくされました。
次にCPUが行き当たり、今なお頭を悩ませているのが、さらなる微細化に伴うリーク電流の増加とそれによる熱問題です。
CPUの動作周波数向上が限界を迎えた結果、AMDは2005年にAthlon X2を、Intelもそれを追いかけるように2006年にCore 2 Duoをリリースし、時代は一気にデュアルコアCPUの時代へと移り変わりました。この時、プロセス・ルールは65nm。現在につながる、CPUのマルチコア化による性能向上を目指す新たな時代の幕開けです。

既にプロセス・ルールの微細化による性能向上は、「性能を上げつつ消費電力もコストも下がる」という従来のようないいことづくめとは言えなくなりつつありましたが、それでも集積密度の向上は従来どおり可能でした。
その結果、従来では難しかったCPUのマルチコア化が可能になります。というのも、従来品をマルチコアにするとサイズが大きくなりすぎる=製造コストが高くなりすぎた(前項でお話しましたね)のですが、集積化の進展がこれを可能にしたのです。
そのためこの頃からCPUは動作周波数を上げることを諦めることで、電圧をむしろ下げて省電力性能を高めながらマルチコア化を進め、再びプロセス・ルール微細化の恩恵を受けることになりました。
教科書どおりなら、プロセス・ルールを半分にして動作周波数は据え置きにすれば、消費電力は半分になる計算ですから。
しかしこの微細化が、リーク電流の増加という避けがたい問題を引き起こします。
リーク電流とは、理想的には流れるはずではない電流が確率的に流れてしまうという現象です。Si原子1個が0.1nm程度なので、65nmというプロセススケールはすでに「原子何百個」というサイズ感になっています。ゲートの酸化絶縁膜にいたってはすでに数nm。もはや量子力学的な振る舞いが無視できないレベルに達し、回路サイズが大きかった時(マクロレベル)では起きえなかった、こうした問題が起こり始めたのです。そしてこのリーク電流による消費はトランジスタの数だけ生じるため、集積化によるトランジスタ数の増加により必然的に増えていきます。
結果、消費電力は思うように下がらず、むしろリーク電流が増えることで増加しかねないという状況になってしまいます。当然発熱も増え、再び熱の壁が立ちふさがります。
CPUの放熱はいよいよ限界を迎え、実際CPUの発熱量の指標であるTDPは、Core 2 Duo QX9775が150Wという数字とともにデビューした2006年から14年経った今なお、最も大きなものでも165Wでしかありません。2000年前後にPentium3がせいぜい40W、Pentium4初期型が60W、最終型が115Wとたった5年ほどの間に景気よく発熱が増えたことと比べると、その頭打ち具合が分かるでしょう。
それでもなんとかあの手この手で改良を続けることで集積化は進展し、勢いは鈍りながらも性能向上は続きました。
CPUでたまに聞くTurbo boostというのも、使わないコアを休ませ、その分を他のコアに回したりして、とにかく熱を抑えながらなんとか性能を出す苦肉の策として考え出された技術です。
しかし、ここに来ていよいよ新たな限界が近づきつつあります。
それは「光」の壁です。
それこそが「7nmプロセス」と「ファブレス」という今回のニュースのキーワードを読み解く鍵になるのですが…あまりに長くなりすぎたので、これについては後半でお話するとしましょう。
⇒ 後編へ続く
---------------------------------------------------------
この他にも時折、科学の色々なニュースの解説をしています。またVRやVTuberに関する考察・分析記事も書いています。
もしよければぜひnote、Twitterをフォローいただければ嬉しいです。
また次の記事でお会いしましょう。
---------------------------------------------------------
【Twitterでのシェアはこちら】
CPU業界の変化を読み解く(前編・CPUの技術的背景とその歴史):思惟かねの気まぐれニュース解説https://t.co/160WR8jkmQ
— 思惟かね(オモイカネ)📕知識系VTuber@note書いてます🔔 (@omoi0kane) August 12, 2020
皆さんのPCに必ず入っているPCの頭脳、CPU。
50年の歴史の中で、CPUはどう進化してきたのか?そして現在の技術的課題とは?
IntelとAMDという2大巨頭の現状を軸にお話しします。
---------------------------------------------------------
今回も長文にお付き合いいただきありがとうございました。
引用RT、リプライ等でのコメントも喜んでお待ちしています。

Twitter: https://twitter.com/omoi0kane
Youtube: https://www.youtube.com/channel/UCpPeO0NenRLndISjkRgRXvA
マシュマロ(お便り): https://marshmallow-qa.com/omoi0kane
Instagram(お写真):https://www.instagram.com/omoi0kane/
note: https://note.com/omoi0kane
○引用RTでのコメント:コメント付のRTとしてご自由にどうぞ(基本的にはお返事しません)
○リプライでのコメント:遅くなるかもしれませんがなるべくお返事します