
Photo by
miniminicar
E検定対策(5) - 単純パーセプトロン:サポートベクターマシーンを用いた分類

今回はサポートベクターマシーン(SVM)の勉強をしました。サポートベクターマシーンはマージン最大化、カーネルトリックという2つの手法を用いることでロジスティック回帰のモデルではできない非線形な分類を行うことができます。また分類問題だけでなく、目的変数が連続値の場合の回帰問題にも適用することができます。
サポートベクターマシーンとは
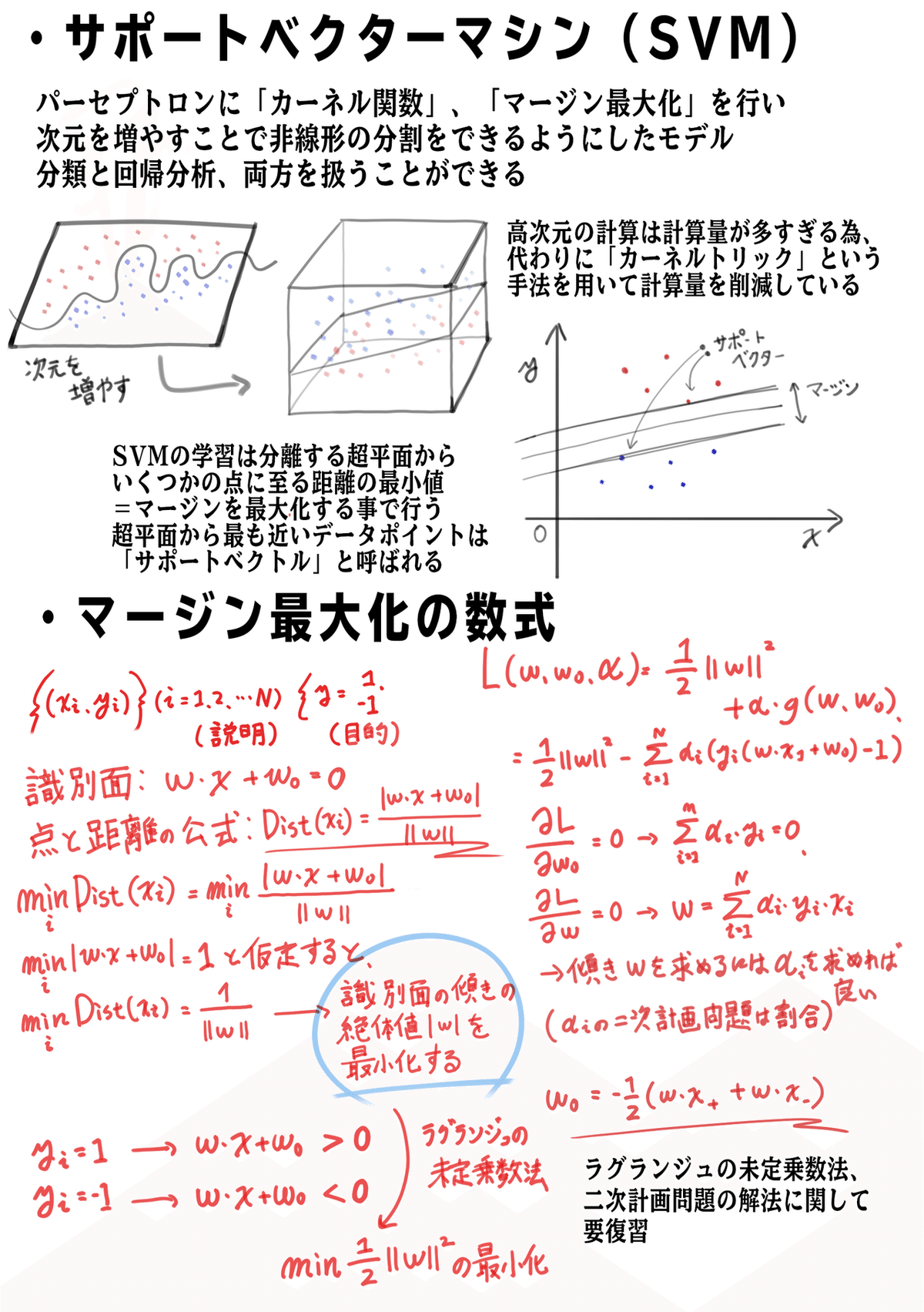

マージン最大化、カーネルトリックの数式にはラグランジュ乗数法、二次計画問題といった数学の解法が応用されているそうです...はっきり言って訳が分からなかったので(笑)、ここは要復習ですね。
サポートベクターマシーンとは
インポート・事前準備・前処理・学習・結果出力・視覚化という順でSVMを実装していきます。今回はMNISTという手書き文字のデータセットの分類を行います。
#インポート
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#データセット、SVM関数
from sklearn import datasets
from sklearn import svm
from sklearn import metrics
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression#事前準備
#今回はMNISTの0-9の手描き数字を分類する
digits = datasets.load_digits()
#データ数を確認
n_samples = len(digits.data)
print("データ数:{}".format(n_samples))
#データの可視化
print(digits.data[0])
images_and_labels = list(zip(digits.images, digits.target))
# enumerateを使ってリストを順に処理する
for index, (image, label) in enumerate(images_and_labels[:10]):
plt.subplot(2, 5, index + 1)
plt.imshow(image, cmap="PuBu", interpolation='nearest')
plt.axis('off')
plt.title('Training: %i'% label)
plt.show()#Pandasを使ってデータの具体的数値を確認する
df = pd.DataFrame(digits.data)
df["Classified"] = digits.target
df.head()
#データの形状を確認
plt.scatter(digits.data[:,0], digits.data[:,1],color = "blue", alpha = 0.25)

#学習開始
# SVM を読み込み、75%のデータを使って学習
clf = svm.SVC(gamma=0.001, C=100.)
clf.fit(digits.data[:int(n_samples * 7.5 / 10)], digits.target[:int(n_samples * 7.5 / 10)])#結果出力
#25%のテストデータのラベルを割り振る
expected = digits.target[int(n_samples *-2.5 / 10):]
predicted = clf.predict(digits.data[int(n_samples *-2.5 / 10):])
print(clf,metrics.classification_report(expected, predicted))
print(metrics.confusion_matrix(expected, predicted))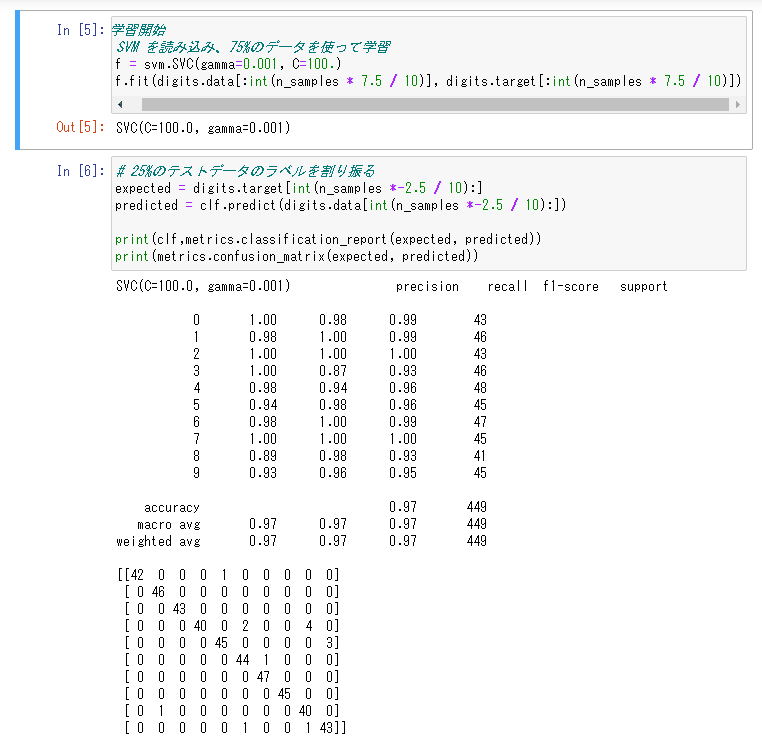
#視覚化
#予測結果を可視化。モデルがどんな判断をしているかはこのようにするとわかりやすい
images_and_predictions = list(zip(digits.images[int(n_samples *-2.5 / 10):], predicted))
for index,(image, prediction) in enumerate(images_and_predictions[:12]):
plt.subplot(3, 4, index + 1)
plt.axis('off')
plt.imshow(image, cmap="PuBu", interpolation='nearest')
plt.title('Prediction: %i' % prediction)
plt.show()
SVMを使用するメリット
・説明変数が多い場合、少ない場合両方に対応可能です。
・ニューラルネットワークよりも少ない教師データで高い汎化性能を出せます。
・計算が速く、過学習も起こしにくいそうです。
SVMのデメリット
・データ数が100000を超えるとうまく行かないケースが多いそうです。
・データを正規化・標準化する必要があります。詳しくはSKlearnのDimensionality reduction、Preprocessingのセクションを読んで復習しておきます。
次回はK近傍法について書く予定です!頑張りますね。