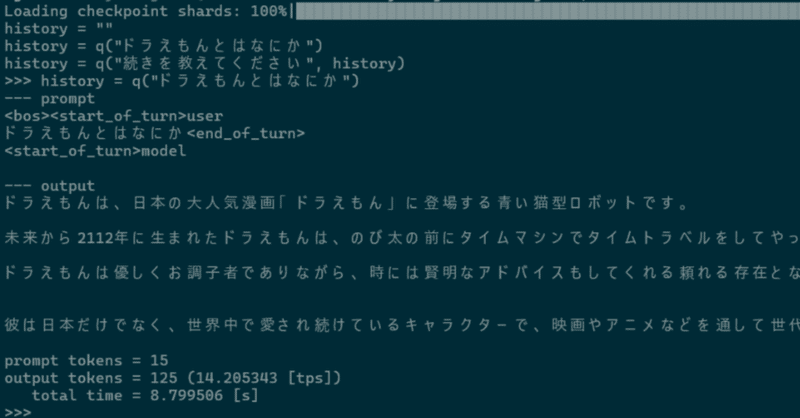
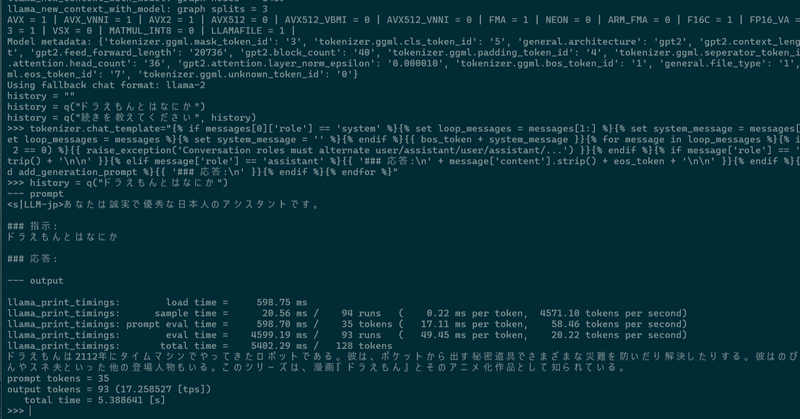
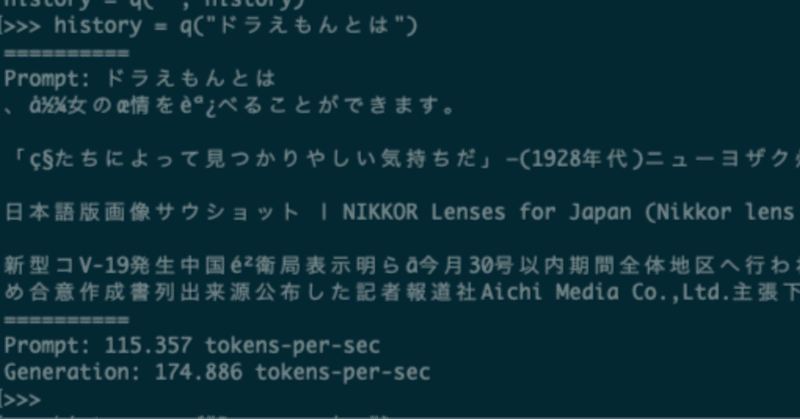
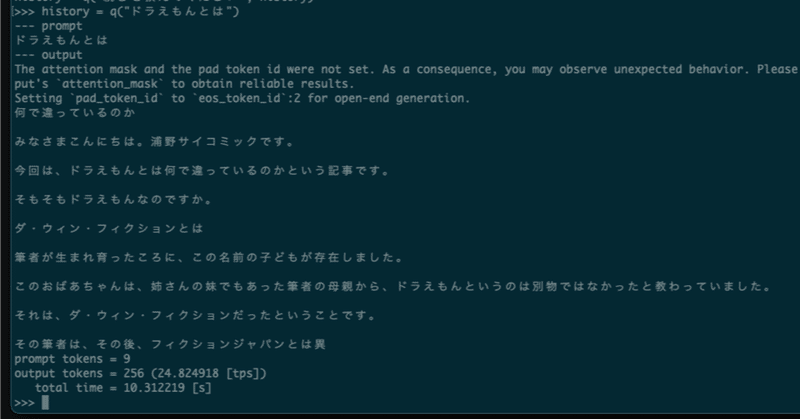
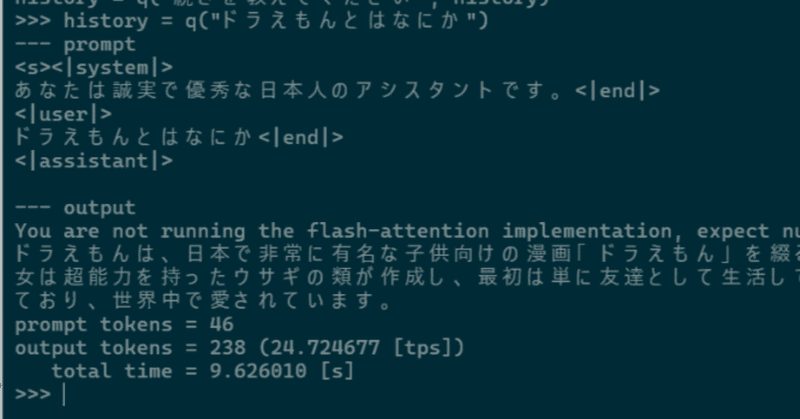
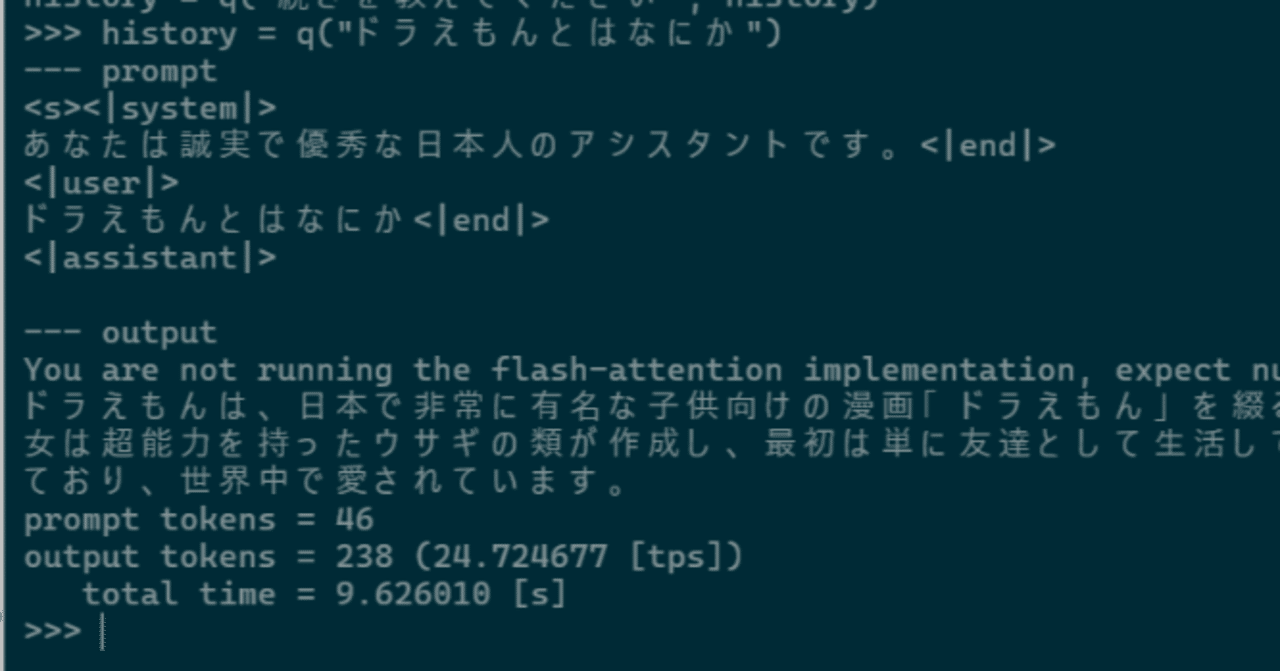
WSL2でsuzume-llama-3-8B-japaneseを試してみる
「3,000 以上の日本語会話に合わせて微調整されており、このモデルには Llama 3のインテリジェンスがありながら、日本語でチャットする機能が追加されている」らしい、Suzumeを試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB