WSL2でFugaku-LLM-13B-instruct-ggufを試してみる

理化学研究所のスーパーコンピュータ「富岳」を用いて学習した、日本語能力に優れた大規模言語モデルFugaku-LLM。今回はそのうちのひとつであるFugaku-LLM-13B-instruct-ggufを試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
venv構築
python3 -m venv fugaku-gguf
cd $_
source bin/activateパッケージのインストール。huggingface-hubとAutoTokenizerを使用したいので、transformersをインストール。
pip install transformers続いて、llama-cpp-python。cuBALSを有効にするために、
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-pythonでインストールします。アップグレードするときは
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python --upgrade --force-reinstall --no-cache-dirです。
2. 流し込むコード
ggufを読み込めるようにしたコードがこちら。query4llama-cpp.pyとして保存します。
コードの詳細(説明)は以下の記事を参照ください。
import sys
import argparse
from huggingface_hub import hf_hub_download
from llama_cpp import Llama
from transformers import AutoTokenizer
from typing import List, Dict
import time
# argv
parser = argparse.ArgumentParser()
parser.add_argument("--model-path", type=str, default=None)
parser.add_argument("--ggml-model-path", type=str, default=None)
parser.add_argument("--ggml-model-file", type=str, default=None)
parser.add_argument("--no-instruct", action='store_true')
parser.add_argument("--no-use-system-prompt", action='store_true')
parser.add_argument("--max-tokens", type=int, default=256)
parser.add_argument("--n-ctx", type=int, default=2048)
parser.add_argument("--n-threads", type=int, default=1)
parser.add_argument("--n-gpu-layers", type=int, default=-1)
args = parser.parse_args(sys.argv[1:])
## check and set args
model_id = args.model_path
if model_id == None:
exit
if args.ggml_model_path == None:
exit
if args.ggml_model_file == None:
exit
is_instruct = not args.no_instruct
use_system_prompt = not args.no_use_system_prompt
max_new_tokens = args.max_tokens
n_ctx = args.n_ctx
n_threads = args.n_threads
n_gpu_layers = args.n_gpu_layers
## Instantiate tokenizer from base model
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
## Download the GGUF model
ggml_model_path = hf_hub_download(
args.ggml_model_path,
filename=args.ggml_model_file
)
## Instantiate model from downloaded file
model = Llama(
model_path=ggml_model_path,
n_ctx=n_ctx,
n_threads=n_threads,
n_gpu_layers=n_gpu_layers
)
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
# generation params
# https://github.com/abetlen/llama-cpp-python/blob/main/llama_cpp/llama.py#L1268
generation_params = {
#"do_sample": True,
"temperature": 0.8,
"top_p": 0.95,
"top_k": 40,
"max_tokens": max_new_tokens,
"repeat_penalty": 1.1,
}
def q(
user_query: str,
history: List[Dict[str, str]]=None
):
start = time.process_time()
# messages
messages = ""
if is_instruct:
messages = []
if use_system_prompt:
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
]
user_messages = [
{"role": "user", "content": user_query}
]
else:
user_messages = user_query
if history:
user_messages = history + user_messages
messages += user_messages
# generation prompts
if is_instruct:
prompt = tokenizer.apply_chat_template(
conversation=messages,
add_generation_prompt=True,
tokenize=False
)
else:
prompt = messages
print("--- prompt")
print(prompt)
print("--- output")
# 推論
outputs = model.create_completion(
prompt=prompt,
#echo=True,
#stream=True,
**generation_params
)
#for output in outputs:
# print(output["choices"][0]["text"], end='')
output = outputs["choices"][0]["text"]
print(output)
if is_instruct:
user_messages.append(
{"role": "assistant", "content": output}
)
else:
user_messages += output
end = time.process_time()
##
input_tokens = outputs["usage"]["prompt_tokens"]
output_tokens = outputs["usage"]["completion_tokens"]
total_time = end - start
tps = output_tokens / total_time
print(f"prompt tokens = {input_tokens:.7g}")
print(f"output tokens = {output_tokens:.7g} ({tps:f} [tps])")
print(f" total time = {total_time:f} [s]")
return user_messages
print('history = ""')
print('history = q("ドラえもんとはなにか")')
print('history = q("続きを教えてください", history)')3. 試してみる
実行する
ここでは query4llama-cpp.py という名前で保存しています。以下の引数で指定します。
python -i query4llama-cpp.py \
--model-path Fugaku-LLM/Fugaku-LLM-13B-instruct \
--ggml-model-path Fugaku-LLM/Fugaku-LLM-13B-instruct-gguf \
--ggml-model-file Fugaku-LLM-13B-instruct-0325b.ggufmodel-path: トークナイザのために指定します。なのでggufではないほうです
ggml-model-path: ggufのモデルへのパスです
ggml-model-file: モデルのパスにあるどのggufファイルを読み込むかを指定します
ggufのファイルは3つあります。今回はGPUを2枚使って26.9GBあるggufで試します。
Fugaku-LLM-13B-instruct-0325b-q8_0.gguf : 14.3 GB
Fugaku-LLM-13B-instruct-0325b.gguf : 26.9 GB
チャットテンプレートの設定
pythonコマンド起動後、以下をコピペして変数の内容を上書きします。
tokenizer.chat_template="{% if messages[0]['role'] == 'system' %}{% set loop_messages = messages[1:] %}{% set system_message = messages[0]['content'].strip() + '\n\n' %}{% else %}{% set loop_messages = messages %}{% set system_message = '' %}{% endif %}{{ bos_token + system_message }}{% for message in loop_messages %}{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}{% endif %}{% if message['role'] == 'user' %}{{ '### 指示:\n' + message['content'].strip() + '\n\n' }}{% elif message['role'] == 'assistant' %}{{ '### 応答:\n' + message['content'].strip() + eos_token + '\n\n' }}{% endif %}{% if loop.last and message['role'] == 'user' and add_generation_prompt %}{{ '### 応答:\n' }}{% endif %}{% endfor %}"チャットテンプレートの設定についての詳細は、以下の記事の「チャットの設定」を参照ください。
聞いてみる
いつものとおり聞いてましょう。
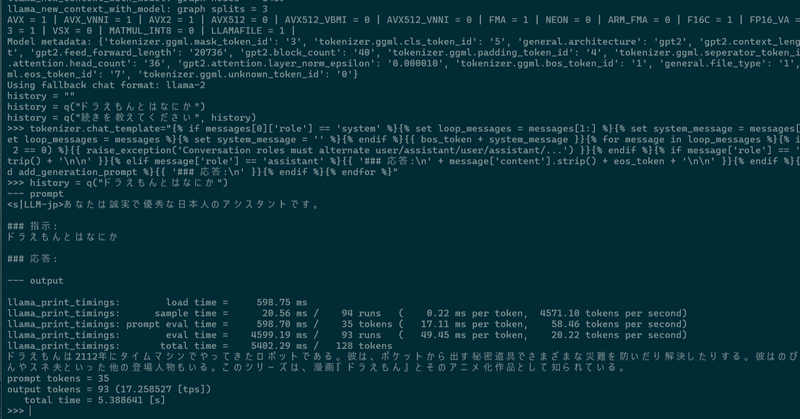
>>> history = q("ドラえもんとはなにか")
--- prompt
<s|LLM-jp>あなたは誠実で優秀な日本人のアシスタントです。
### 指示:
ドラえもんとはなにか
### 応答:
--- output
llama_print_timings: load time = 723.33 ms
llama_print_timings: sample time = 21.27 ms / 96 runs ( 0.22 ms per token, 4514.46 tokens per second)
llama_print_timings: prompt eval time = 723.24 ms / 35 tokens ( 20.66 ms per token, 48.39 tokens per second)
llama_print_timings: eval time = 4718.69 ms / 95 runs ( 49.67 ms per token, 20.13 tokens per second)
llama_print_timings: total time = 5636.91 ms / 130 tokens
ドラえもんは2112年にタイムマシンでやってきたロボット猫である。彼は青くてロップイヤーのような耳をしている。彼の好奇心旺盛な性格と、ポケットから出すさまざまな道具で知られている。彼はまた、 勉強熱心で博識でもある。多くのひみつ道具は、のび太を助けるために未来から持ってきている。
prompt tokens = 35
output tokens = 95 (16.870301 [tps])
total time = 5.631198 [s]
>>>ドラえもんは2112年にタイムマシンでやってきたロボット猫である。彼は青くてロップイヤーのような耳をしている。彼の好奇心旺盛な性格と、ポケットから出すさまざまな道具で知られている。彼はまた、勉強熱心で博識でもある。多くのひみつ道具は、のび太を助けるために未来から持ってきている。
ロップイヤー(=大きく垂れ下がった耳が特徴のうさぎ)…。
もう一度聞いてみると、
ドラえもんは2112年にタイムマシンでやってきたロボットである。彼は、ポケットから出す秘密道具でさまざまな災難を防いだり解決したりする。彼はのび太が世話をする少年少女の友人であり、しずかちゃんやスネ夫といった他の登場人物もいる。このシリーズは、漫画『ドラえもん』とそのアニメ化作品として知られている。
うーむ、「2112年『に』」ではなく「から」だし、のび太は少年少女を世話してない。
4. まとめ
推論のパフォーマンスは 16.9 ~ 17.2 トークン/秒ほど、VRAMの使用量は 27,866MiB ぐらいでした。
日本語、難しいですね。
この記事が気に入ったらサポートをしてみませんか?