WSL2でGemma 2を試してみる

GoogleのGemma 2 9bモデルが2つ公開されましたので、試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
python3 -m venv gemma
cd $_
source bin/activateパッケージのインストール。
pip install torch transformers accelerate2. 流し込むコード
こちらを /path/to/query.py として保存します。
import sys
import argparse
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from typing import List, Dict
import time
# argv
parser = argparse.ArgumentParser()
parser.add_argument("--model-path", type=str, default=None)
parser.add_argument("--tokenizer-path", type=str, default=None)
parser.add_argument("--no-chat", action='store_true')
parser.add_argument("--no-use-system-prompt", action='store_true')
parser.add_argument("--max-tokens", type=int, default=256)
args = parser.parse_args(sys.argv[1:])
model_id = args.model_path
if model_id == None:
exit
is_chat = not args.no_chat
use_system_prompt = not args.no_use_system_prompt
max_new_tokens = args.max_tokens
tokenizer_id = model_id
if args.tokenizer_path:
tokenizer_id = args.tokenizer_path
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
tokenizer_id,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
#torch_dtype="auto",
#torch_dtype=torch.bfloat16,
torch_dtype=torch.float16,
device_map="auto",
#device_map="cuda",
low_cpu_mem_usage=True,
trust_remote_code=True
)
#if torch.cuda.is_available():
# model = model.to("cuda")
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
def q(
user_query: str,
history: List[Dict[str, str]]=None
) -> List[Dict[str, str]]:
# generation params
generation_params = {
"do_sample": True,
"temperature": 0.8,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": max_new_tokens,
"repetition_penalty": 1.1,
}
#
start = time.process_time()
# messages
messages = ""
if is_chat:
messages = []
if use_system_prompt:
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
]
user_messages = [
{"role": "user", "content": user_query}
]
else:
user_messages = user_query
if history:
user_messages = history + user_messages
messages += user_messages
# generation prompts
if is_chat:
prompt = tokenizer.apply_chat_template(
conversation=messages,
add_generation_prompt=True,
tokenize=False
)
else:
prompt = messages
input_ids = tokenizer.encode(
prompt,
add_special_tokens=True,
return_tensors="pt"
)
print("--- prompt")
print(prompt)
print("--- output")
# 推論
output_ids = model.generate(
input_ids.to(model.device),
streamer=streamer,
**generation_params
)
output = tokenizer.decode(
output_ids[0][input_ids.size(1) :],
skip_special_tokens=True
)
if is_chat:
user_messages.append(
{"role": "assistant", "content": output}
)
else:
user_messages += output
end = time.process_time()
##
input_tokens = len(input_ids[0])
output_tokens = len(output_ids[0][input_ids.size(1) :])
total_time = end - start
tps = output_tokens / total_time
print(f"prompt tokens = {input_tokens:.7g}")
print(f"output tokens = {output_tokens:.7g} ({tps:f} [tps])")
print(f" total time = {total_time:f} [s]")
return user_messages
3. 試してみる - transformers
(1) google/gemma-2-9b
chat_templateが定義されていないので、--no-chatオプション付きで実行します。
CUDA_VISIBLE_DEVICES=0 python -i ~/scripts/query.py --model-path google/gemma-2-9b --no-chatpythonプロンプトから聞いてみましょう。
>>> history = q("ドラえもんは")
--- prompt
ドラえもんは
--- output
いいパパだ。
このアプリには、「<strong>かわいい</strong>」とか「面白い」といった<strong>笑える</strong>タグが取り付けられています。 今回は、ドラえもんの画像を投稿しました!100枚以上の画像のうち、<b>2</b>枚の写真を紹介しています。
これは、どうですか?
【出典:https://twitter.com/dora_movie_news/status/548936370654986240】
<h2>「#」から探す</h2>
<h2>「<strong>笑</strong>」から探す</h2>
<h2>略語・俗語から探す</h2>
<h2>ネット上の話題から探す</h2>
* <blockquote>【お知らせ】『スヌーピー』とコラボした映画『リトル・プリンセス ソフィア』『ミニオンズのムービー』『ペットのおすわりは大丈夫?』など8作品を同時公開します。「トイ・ストーリ ーシリーズ」「マダガスカル」「マイキー」「シンドラーズリスト」等の歴代No.1の人気タイトルを記録するハリウッドの大人気作です。</blockquote>
prompt tokens = 4
output tokens = 221 (15.204655 [tps])
total time = 14.535022 [s]--- prompt
ドラえもんは
--- output
いいパパだ。
このアプリには、「<strong>かわいい</strong>」とか「面白い」といった<strong>笑える</strong>タグが取り付けられています。 今回は、ドラえもんの画像を投稿しました!100枚以上の画像のうち、<b>2</b>枚の写真を紹介しています。
これは、どうですか?
【出典:https://twitter.com/dora_movie_news/status/548936370654986240】
<h2>「#」から探す</h2>
<h2>「<strong>笑</strong>」から探す</h2>
<h2>略語・俗語から探す</h2>
<h2>ネット上の話題から探す</h2>
* <blockquote>【お知らせ】『スヌーピー』とコラボした映画『リトル・プリンセス ソフィア』『ミニオンズのムービー』『ペットのおすわりは大丈夫?』など8作品を同時公開します。「トイ・ストーリ ーシリーズ」「マダガスカル」「マイキー」「シンドラーズリスト」等の歴代No.1の人気タイトルを記録するハリウッドの大人気作です。</blockquote>
そうか、ドラえもんもパパになったのか…(遠い目。
なかなかいい感じの創作文です。
(2) google/gemma-2-9b-it
tokenizer_config.jsonの変数chat_templateを見るに、システムプロンプトには対応していないようなので、--no-use-system-promptオプション付きで実行しています。
CUDA_VISIBLE_DEVICES=0 python -i ~/scripts/query.py --model-path google/gemma-2-9b-it --no-use-system-promptpythonプロンプトから聞いてみましょう。
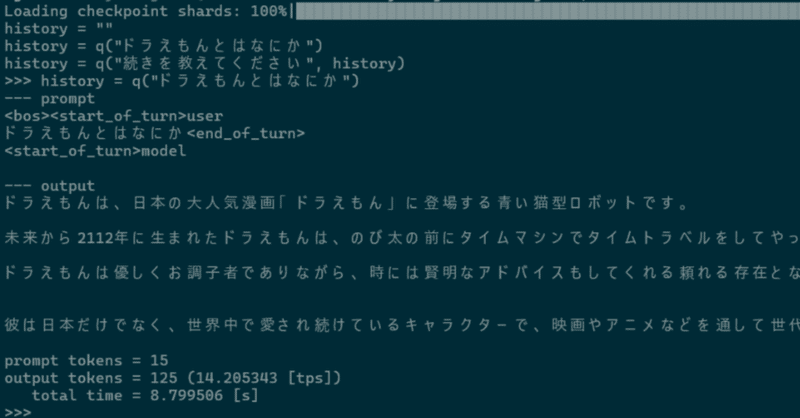
>>> history = q("ドラえもんとはなにか")
--- prompt
<bos><start_of_turn>user
ドラえもんとはなにか<end_of_turn>
<start_of_turn>model
--- output
ドラえもんは、日本の大人気漫画「ドラえもん」に登場する青い猫型ロボットです。
未来から2112年に生まれたドラえもんは、のび太の前にタイムマシンでタイムトラベルをしてやって来てくれます。 彼の道具を使って、のび太は様々な冒険を経験し、友情や優しさ、成長などを学びます。
ドラえもんは優しくお調子者でありながら、時には賢明なアドバイスもしてくれる頼れる存在となっています。
彼は日本だけでなく、世界中で愛され続けているキャラクターで、映画やアニメなどを通して世代を超えて多くの人に知られています。
prompt tokens = 15
output tokens = 125 (14.205343 [tps])
total time = 8.799506 [s]
>>>ドラえもんは、日本の大人気漫画「ドラえもん」に登場する青い猫型ロボットです。
未来から2112年に生まれたドラえもんは、のび太の前にタイムマシンでタイムトラベルをしてやって来てくれます。 彼の道具を使って、のび太は様々な冒険を経験し、友情や優しさ、成長などを学びます。
ドラえもんは優しくお調子者でありながら、時には賢明なアドバイスもしてくれる頼れる存在となっています。
彼は日本だけでなく、世界中で愛され続けているキャラクターで、映画やアニメなどを通して世代を超えて多くの人に知られています。
誕生年は2112年であっている。
ただ、「未来から」の位置が微妙。「やって来てくれます」の前ならば合っているのだが。
VRAM使用量は、9Bモデルですから18GB前後(17.8GB)でした。

4. 試してみる - vLLM
試そうとしたのですが、以下のエラー「Gemma2ForCausalLMモデルは未対応」ということで、試せませんでした。
[rank0]: ValueError: Model architectures ['Gemma2ForCausalLM'] are not supported for now. Supported architectures: ['AquilaModel', 'AquilaForCausalLM', 'BaiChuanForCausalLM', 'BaichuanForCausalLM', 'BloomForCausalLM', 'ChatGLMModel', 'ChatGLMForConditionalGeneration', 'CohereForCausalLM', 'DbrxForCausalLM', 'DeciLMForCausalLM', 'DeepseekForCausalLM', 'FalconForCausalLM', 'GemmaForCausalLM', 'GPT2LMHeadModel', 'GPTBigCodeForCausalLM', 'GPTJForCausalLM', 'GPTNeoXForCausalLM', 'InternLMForCausalLM', 'InternLM2ForCausalLM', 'JAISLMHeadModel', 'LlamaForCausalLM', 'LlavaForConditionalGeneration', 'LlavaNextForConditionalGeneration', 'LLaMAForCausalLM', 'MistralForCausalLM', 'MixtralForCausalLM', 'QuantMixtralForCausalLM', 'MptForCausalLM', 'MPTForCausalLM', 'MiniCPMForCausalLM', 'OlmoForCausalLM', 'OPTForCausalLM', 'OrionForCausalLM', 'PhiForCausalLM', 'Phi3ForCausalLM', 'QWenLMHeadModel', 'Qwen2ForCausalLM', 'Qwen2MoeForCausalLM', 'RWForCausalLM', 'StableLMEpochForCausalLM', 'StableLmForCausalLM', 'Starcoder2ForCausalLM', 'ArcticForCausalLM', 'XverseForCausalLM', 'Phi3SmallForCausalLM', 'MistralModel']対応待ち、ですね。
この記事が気に入ったらサポートをしてみませんか?