WSL2でPhi-3-mini-128k-instructを試してみる

「Phi-3 データセットを使用してトレーニングされた、38 億パラメータの軽量の最先端のオープンモデル」らしい、Phi-3-mini-128k-instructを試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
venr構築
python3 -m venv phi3
cd $_
source bin/activateパッケージのインストール。
pip install torch transformers accelerate2. 流し込むコード
いつものコードです。query.pyという名前で保存した想定で以下進めます。
import sys
import argparse
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from typing import List, Dict
import time
# argv
parser = argparse.ArgumentParser()
parser.add_argument("--model-path", type=str, default=None)
parser.add_argument("--no-chat", action='store_true')
parser.add_argument("--no-use-system-prompt", action='store_true')
parser.add_argument("--max-tokens", type=int, default=256)
args = parser.parse_args(sys.argv[1:])
model_id = args.model_path
if model_id == None:
exit
is_chat = not args.no_chat
use_system_prompt = not args.no_use_system_prompt
max_new_tokens = args.max_tokens
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
#torch_dtype="auto",
torch_dtype=torch.bfloat16,
device_map="auto",
#device_map="cuda",
low_cpu_mem_usage=True,
trust_remote_code=True
)
#if torch.cuda.is_available():
# model = model.to("cuda")
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
# generation params
generation_params = {
"do_sample": True,
"temperature": 0.8,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": max_new_tokens,
"repetition_penalty": 1.1,
}
def q(
user_query: str,
history: List[Dict[str, str]]=None
) -> List[Dict[str, str]]:
start = time.process_time()
# messages
messages = ""
if is_chat:
messages = []
if use_system_prompt:
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
]
user_messages = [
{"role": "user", "content": user_query}
]
else:
user_messages = user_query
if history:
user_messages = history + user_messages
messages += user_messages
# generation prompts
if is_chat:
prompt = tokenizer.apply_chat_template(
conversation=messages,
add_generation_prompt=True,
tokenize=False
)
else:
prompt = messages
input_ids = tokenizer.encode(
prompt,
add_special_tokens=True,
return_tensors="pt"
)
print("--- prompt")
print(prompt)
print("--- output")
# 推論
output_ids = model.generate(
input_ids.to(model.device),
streamer=streamer,
**generation_params
)
output = tokenizer.decode(
output_ids[0][input_ids.size(1) :],
skip_special_tokens=True
)
if is_chat:
user_messages.append(
{"role": "assistant", "content": output}
)
else:
user_messages += output
end = time.process_time()
##
input_tokens = len(input_ids[0])
output_tokens = len(output_ids[0][input_ids.size(1) :])
total_time = end - start
tps = output_tokens / total_time
print(f"prompt tokens = {input_tokens:.7g}")
print(f"output tokens = {output_tokens:.7g} ({tps:f} [tps])")
print(f" total time = {total_time:f} [s]")
return user_messages
print('history = ""')
print('history = q("ドラえもんとはなにか")')
print('history = q("続きを教えてください", history)')3. 試してみる
Hugging Faceのパスを指定して起動です。max-tokensを4096に指定しておきます。
python -i /path/to/query.py --model-path microsoft/Phi-3-mini-128k-instruct --max-tokens 4096聞いてみる
とりあえず聞いてみましょう。
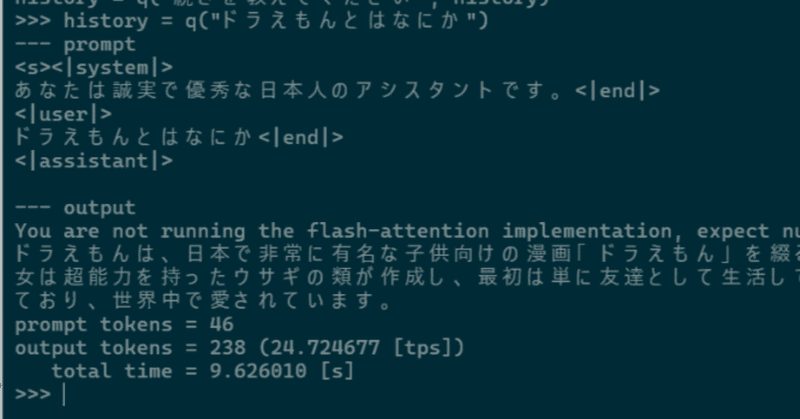
>>> history = q("ドラえもんとはなにか")
--- prompt
<s><|system|>
あなたは誠実で優秀な日本人のアシスタントです。<|end|>
<|user|>
ドラえもんとはなにか<|end|>
<|assistant|>
--- output
ドラえもん(だらいもん)は、日本で最も有名なロボットキャラクターで、作者の藤子・F・不二雄によって創造されました。主人公は青いリュック服を着た小さな男性の少年「びちゃくじ」で、その腕には彼の親友である、机の上に隠されているとされる超能力を持つ30ページの架空のテレビである「ドラえもんの世界(ドラえもんマガジン)」が付属しています。この世界は物理的に存在せず、インタラクティブ な簡単なプログラムを通じて、ドラえもんは多くの謎解きや冒険に関与しています。さらに、このメディアは幅広い年齢層に向けて設計されており、教育的価値も高められています。
prompt tokens = 46
output tokens = 306 (26.511583 [tps])
total time = 11.542125 [s]
>>>ドラえもん(だらいもん)は、日本で最も有名なロボットキャラクターで、作者の藤子・F・不二雄によって創造されました。主人公は青いリュック服を着た小さな男性の少年「びちゃくじ」で、その腕には彼の親友である、机の上に隠されているとされる超能力を持つ30ページの架空のテレビである「ドラえもんの世界(ドラえもんマガジン)」が付属しています。この世界は物理的に存在せず、インタラクティブ な簡単なプログラムを通じて、ドラえもんは多くの謎解きや冒険に関与しています。さらに、このメディアは幅広い年齢層に向けて設計されており、教育的価値も高められています。
かなり斜め上な文章でして…。わたしの頭が固いのかしら。
4. まとめ
推論の速度は26.5トークン/秒ぐらい、VRAMは8.0GBほどでした。

この記事が気に入ったらサポートをしてみませんか?