記事一覧

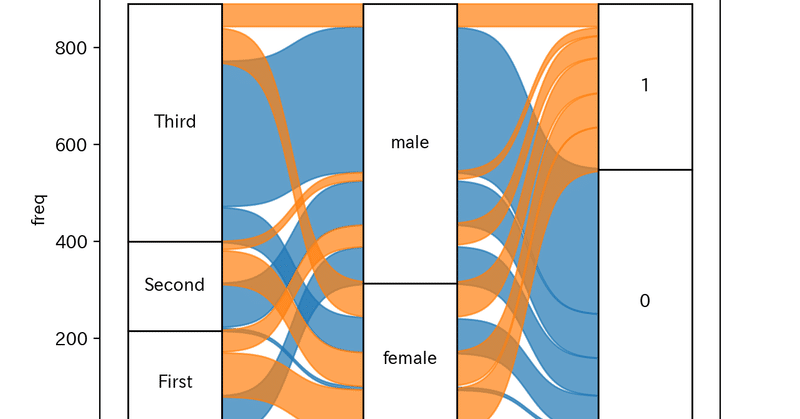
Alluvial PlotをPythonで描く
TL;DR・Alluvial Plotはいいぞ ・Pythonで良いかんじに描けるライブラリがなかったからつくった ・https://github.com/nekoumei/pyalluvial はじめに皆さんはデータを分析…


ガブリエル比較区間をpythonで出す
はじめにこんにちは。
信頼区間、便利ですよね。僕もよく使います。
あまり統計に詳しくない方向けにビジュアライズするときにも、95%信頼区間をエラーバーで描画することで意図が伝えやすくなる場面もそこそこあります。
しかし、95%信頼区間の重なり具合は必ずしも差がある/あるとは言えないを表しません。
特に、たとえば複数のカテゴリの平均値とその信頼区間を並べたとき、多重比較になるためより誤解が生まれそう

「サンプルサイズが大きすぎると良くない」ってどういうこと?
はじめにこんにちは。
データ分析界隈でたまに、「サンプルサイズ大きすぎると良くない」って話を聞きます。
主に、検定を行いp-valueから有意差を確認する文脈で言われているようです。
サンプルサイズ設計に関してー理論編より引用
基本的に、多くの検定では例数が大きくなると、有意差があるという結果が得られやすくなります。
(中略)
例数が多すぎる場合:実際には差がなくても有意と判定してしまう
統計
Alluvial PlotをPythonで描く
TL;DR・Alluvial Plotはいいぞ
・Pythonで良いかんじに描けるライブラリがなかったからつくった
・https://github.com/nekoumei/pyalluvial
はじめに皆さんはデータを分析するときに、ある状態の数量などの遷移を可視化したい(たとえばWebページのPVやサービス利用ユーザのクラスタの時系列変化など)とき、どんな可視化を検討しますか。
いろいろある

LightGBMのCalibration Curveを確認する
はじめに何らかの問題を二値分類で解くとき、予測確率を正しく求めたいことがあります。
scikit-learnのDocumentの例では、ナイーブベイズおよびSVCでの予測確率が実際の確率からずれていて、Calibrationを行うことで改善される例が紹介されています。
LightGBMの場合どうなんでしょう。
lgbの公式ドキュメントによると binary classificationの場合は b