
econmlのestimatorにlgb.cvをつっこむ

こんにちは。因果推論してますか?
最近、つくりながら学ぶ! Pythonによる因果分析 を読んでてmeta-learnersいいなーって思いました。
meta-learnersは実装自体はそんなに難しくないので自力で実装してもいいんですが、個人的にはeconmlを使うのが手軽で良いです。
※ econmlのmeta-learnersの解説、簡易な実験についてはusaitoさんの記事が分かりやすいです。
さて、そんなeconmlですが利用するestimatorはsklearnライクなapiである必要があります。
from econml.metalearners import TLearner
from sklearn.ensemble import GradientBoostingRegressor
est = TLearner(models=GradientBoostingRegressor())
est.fit(Y, T, np.hstack([X, W]))
treatment_effects = est.effect(np.hstack([X_test, W_test]))※ econml/READMEより抜粋
こんなかんじですね。便利ですね。
しかし、MLといえばLightGBMを使いたいし、lgbを使うならkfold cvしてearly_stoppingしてaveragingしたいですよね。
そこで本記事ではlgb.cvをsklearn apiっぽくして実際にeconmlにつっこむをやります。
コード全文(Notebook)はGitHubにあげておきました。詳細はそちらをご覧ください。
バージョン情報
Python 3.7.4
scikit-learn==0.22.2.post1
lightgbm==2.3.1
econml==0.7.0特にlightgbmのバージョンには注意が必要です。(理由は後述)
lgb + kfold cvをいい感じにsklearn likeにする
kfold cvしながらlightgbmを回すには以下の2パターンが考えられます。
① lgb.cv()を使う
② 自分でfor文を書いてkfoldをまわす
これらの違いについては、momijiameさんの記事にて詳しく解説されています。興味ある人は見てみてください。
今回は①lgb.cv()を使うでやっていきましょう。
lightgbm==2.3.1の現在、lgb.cv()を使う場合カスタムコールバックでいいかんじにしないと学習したBoosterを返してもらえません。そのあたりの実装は(再び)momijiameさんの記事を大いに参考にしました。ありがとうございます、、!
コード当該部分の抜粋(callback部分は除く)は下記のとおりです。
from sklearn.base import BaseEstimator, RegressorMixin, ClassifierMixin
class LGBCV:
def __init__(self, params, is_stratified):
self.params = params
self.is_stratified = is_stratified
def fit(self, X_train, y_train):
oof = np.zeros(X_train.shape[0])
extraction_cb = ModelExtractionCallback()
callbacks = [extraction_cb,]
lgb_train = lgb.Dataset(X_train, y_train)
lgb.cv(self.params,
lgb_train,
num_boost_round=1000000,
early_stopping_rounds=1000,
nfold=5,
shuffle=True,
stratified=self.is_stratified,
seed=42,
callbacks=callbacks,
)
# コールバックのオブジェクトから学習済みモデルを取り出す
self.proxy = extraction_cb.boosters_proxy
self.boosters = extraction_cb.raw_boosters
self.best_iteration = extraction_cb.best_iteration
return self
def predict(self, X_test):
y_pred_proba_list = self.proxy.predict(X_test, num_iteration=self.best_iteration)
y_pred = np.array(y_pred_proba_list).mean(axis=0)
return y_pred
class LGBCVBinaryClassifier(LGBCV, BaseEstimator, ClassifierMixin):
def __init__(self):
params = {
'objective': 'binary',
'metric': 'auc',
'max_depth': 8,
'num_leaves': 2 ** 8,
'learning_rate': 0.1,
'bagging_fraction': 0.8,
'random_state': 0,
'num_iterations': 100000,
'early_stopping_rounds': 1000,
}
super().__init__(params, True)
def _calc_predict_proba(self, X_test):
y_pred_1 = super().predict(X_test)
y_pred_0 = 1 - y_pred_1
y_proba = np.array([y_pred_0, y_pred_1]).T
return y_proba
def predict(self, X_test):
y_proba = self._calc_predict_proba(X_test)
return np.argmax(y_proba, axis=1)
def predict_proba(self, X_test):
return self._calc_predict_proba(X_test)
class LGBCVRegressor(LGBCV, BaseEstimator, RegressorMixin):
def __init__(self):
params = {
'objective': 'regression',
'metric': 'rmse',
'max_depth': 8,
'num_leaves': 2 ** 8,
'learning_rate': 0.1,
'bagging_fraction': 0.8,
'random_state': 0,
'num_iterations': 100000,
'early_stopping_rounds': 1000,
}
super().__init__(params, False)sklearn likeなモデルの実装についてはこちらの記事を参考にしました。
2値分類を行うLGBCVBinaryClassifierは、傾向スコアの計算に使うためpredict_proba()を実装しています。また、Outputもsklearn likeに合わせています。
paramsをクラス内でハードに定義してるのダサすぎるので直したい人は適宜直してください。今回は精度云々、Tuning云々は重きを置かないのでいったんこれでいきます。
注意: Lightgbm==3.0.0以降について
現在Pre-releaseで、もうすぐ(9月末くらい?)に本リリースされるlightgbm==3.0.0では、lgb.cv()にreturn_cv_boosterが追加され、これによって簡単にBoosterが取り出せるようになります。(momijiameさんのcontribute)
よって現在の実装は3.0.0以降では(たぶん)改修が必要になります。3.0.0が出て以降の気分次第で対応します。
meta-learnersをつかう(T-Learner, X-Learner)
まず、econmlのexamplesにあるT-Learnerの利用例を見てみます。
# Instantiate T learner
models = GradientBoostingRegressor(n_estimators=100, max_depth=6, min_samples_leaf=int(n/100))
T_learner = TLearner(models)
# Train T_learner
T_learner.fit(Y, T, X)
# Estimate treatment effects on test data
T_te = T_learner.effect(X_test)シンプルですね。上記のGradientBoostingRegressorの部分を先ほど実装したLGBCVRegressorに置き換えるだけで実行できます。
# Instantiate T learner
models = LGBCVRegressor()
T_learner = TLearner(models)
# Train T_learner
T_learner.fit(Y, T, X)
# Estimate treatment effects on test data
T_te = T_learner.effect(X_test)これでOKです。楽ですね。
また、econmlにはbootstrapで複数回実行してN%のブートストラップ信頼区間を出す機能があります。(これが捗るのでeconml使おうってなりました)
T_learner.fit(Y, T, X, inference='bootstrap')
lb, ub = T_learner.effect_interval(X_test, alpha=0.05)inferenceに'bootstrap'を渡すと、econml.inferenceのBootstrapInference()がデフォルトパラメータで使われます。
デフォルトの場合、bootstrap回数100回、n_jobs=-1 (使えるCPU全部使って並列化)で行われます。
シングルモデルのsklearnほぼデフォルトパラメータなモデルと比べると、lgbはCVもしてるしどうしても時間がかかるので、100回ではなく10回にします。
こんなかんじ↓
from econml.inference import BootstrapInference
# Instantiate T learner
models = LGBCVRegressor()
T_learner = TLearner(models)
# Train T_learner
T_learner.fit(Y, T, X, inference=BootstrapInference(n_bootstrap_samples=10, n_jobs=1))n_jobsを1にしているのは、lgb側の計算で既に並列実行されているのにそれをさらに並列にするのがなんか嫌だからですね。実際、なんか謎に止まったりして不安定だったのでシングル実行するようにしています。(このへんよく分かってないので有識者に教えてほしい)
今回の実験では、n_bootstrap_samples=10でGradientBoostingRegressorとLGBCVRegressorそれぞれでT-Learnerのモデル学習+予測にかかった時間を比較すると、前者が788 ms、後者が1min 1sでした。めっちゃ伸びとる・・・
今回のデータはサンプルサイズが1,000と小さいデータでした。これが10,000とか多くなるとlgb.cvだとめちゃ時間かかるようになるので結構トレードオフになると思います。
実験結果
ということで、econmlのexampleで使われている擬似データを使って、T-LearnerとX-Learnerをやってみました。
比較のため、exampleで使われているGradientBoostingRegressor(), RandomForestClassifier()を使ったのと、今回作成したLGBCVRegressor()とLGBCVBinaryClassifier()を使ったのを比較します。
T-Learner
個別因果効果のプロット
GradientBoostingRegressor

LGBCVRegressor

ATE
GradientBoostingRegressor: 3.63
LGBCVRegressor: 3.68
Ground Truth: 3.84
Wall Time
GradientBoostingRegressor: 788 ms
LGBCVRegressor: 1min 1s
X-Learner
個別因果効果のプロット
GradientBoostingRegressor + RandomForestClassifier
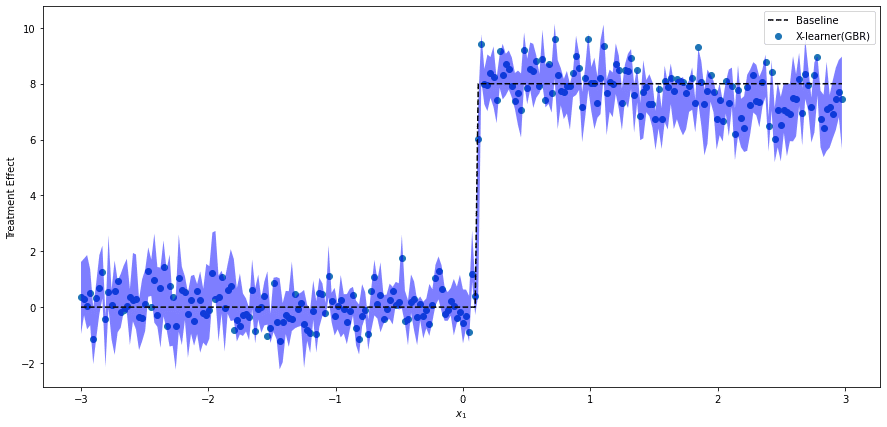
LGBCVRegressor + LGBCVBinaryClassifier

ATE
GradientBoostingRegressor: 3.78
LGBCVRegressor: 3.68
Ground Truth: 3.84
Wall Time
GradientBoostingRegressor: 2.72 s
LGBCVRegressor: 2min 28s
はい。
今回のデータだとあまりそれぞれの違いわかんないですね。どのモデルも良い感じに予測できています。気持ちX-Learnerの方がCIが狭くて良いかも?
今回の擬似データは1000行× 5列の小さいデータだったのでまあそんなもんですかね。もっと大きくなると違いが出てきそうですが、lgbの速度がさらにネックになる気がします。
おわりに
読んでいただいてありがとうございました。
今回の記事で言いたいことは、econmlのeffect_interval捗るねってことです。良いよね。。。
あと、そんなにlgbにこだわんなくてもいいかなあと思いました。やっぱり比較的時間がかかってしまうので。よっぽど精度が爆上がりするとかだったら別ですが、、
本記事について何か分からんとことか、間違ってるとことかあれば是非Twitterとかで教えてください🤗
ありがとうございました。
参考文献まとめ
econml
Python: LightGBM の cv() 関数から学習済みモデルを得る
Python: LightGBM の cv() 関数の実装について
sklearn準拠モデルの作り方
LightGBM v3.0.0rc1
この記事が気に入ったらサポートをしてみませんか?