
ガブリエル比較区間をpythonで出す

はじめに
こんにちは。
信頼区間、便利ですよね。僕もよく使います。
あまり統計に詳しくない方向けにビジュアライズするときにも、95%信頼区間をエラーバーで描画することで意図が伝えやすくなる場面もそこそこあります。
しかし、95%信頼区間の重なり具合は必ずしも差がある/あるとは言えないを表しません。
特に、たとえば複数のカテゴリの平均値とその信頼区間を並べたとき、多重比較になるためより誤解が生まれそうです。
このあたりの詳しい話は 【翻訳】ダメな統計学 (6) 有意であるかないかの違いが有意差でない場合 や、 ■ Rでガブリエル比較区間を計算する方法 にて解説されています。
で、上記ページでも紹介されているように、ガブリエル比較区間であればより視覚的にもっともらしい比較区間を得られるみたいです。全然知らなかったんですが、結構むかしに提案された手法のようです。ググってもあまり情報が出てこず、あんまり流行ってないみたいです。なんか理由があるんでしょうか、、
多重比較もいいかんじに補正してくれるみたいで、良さそうですね。
Rではrgabriel パッケージがあり、簡単に求めることができますが、pyhtonにはそういった便利パッケージはなさそうだったので、pyhtonで実装しました。
GitHub
nbviewer(上記で見れない場合)
実際にガブリエル比較区間を計算する部分を抜き出すと下記のとおりです。
import numpy as np
import pandas as pd
import math
from scipy import stats, integrate, optimize
def psmm_x(x, c, r, nu):
snu = math.sqrt(nu)
sx = snu * x # for the scaled Chi distribution
lgx = math.log(snu) - math.lgamma(nu/2) +\
(1 - nu/2) * math.log(2) + (nu - 1) * math.log(sx) + (-pow(sx, 2) /2)
return math.exp(r * math.log(2 * stats.norm.cdf(c * x) - 1) + lgx)
def psmm(x, r, nu):
return integrate.quad(lambda x_: psmm_x(x_, c=x, r=r, nu=nu), 0, np.inf)[0]
def qsmm(q, r, nu):
r = r * (r - 1) / 2
if nu is None:
return stats.norm.ppf(1 - .5 * (1 - pow(q, (1 / r))))
fx = lambda c: psmm(c, r, nu) - q
return optimize.bisect(fx, 1e-8, 100)
def gabriel(x, f, a=0.025):
data = pd.DataFrame({
'val': x,
'cat': f
}).dropna()
stds = data.groupby('cat').std()
nums = data.groupby('cat').count()
dfs = nums - 1 #自由度
dfstar = dfs.sum().values[0]
sr = qsmm(1-a, len(np.unique(f)), dfstar)
return sr * stds / np.sqrt(2 * nums)R実装との差分が1点あり、rgabrielではニュートン法(uniroot())で求解している箇所を二分法(scipy.optimize.bisect())に変更しています。そのため厳密には値が合わない可能性があるかもしれません。
notebook内ではrgabrielとの比較も行っています。
以降では、①有意差あるけど95%信頼区間が重なっているパターン と ②多重比較のパターン を可視化した様子について述べていきます。
①有意差あるけど95%信頼区間が重なっているパターン
先ほど紹介した記事 ■ Rでガブリエル比較区間を計算する方法 にて実験されているケースと同じデータを使用します。ここでいう有意差とは、5%水準でp-valueが0.05以下であることを意味します。
2群(C, T-1)のデータがあり、これらの平均値に差があるかを可視化する目的です。
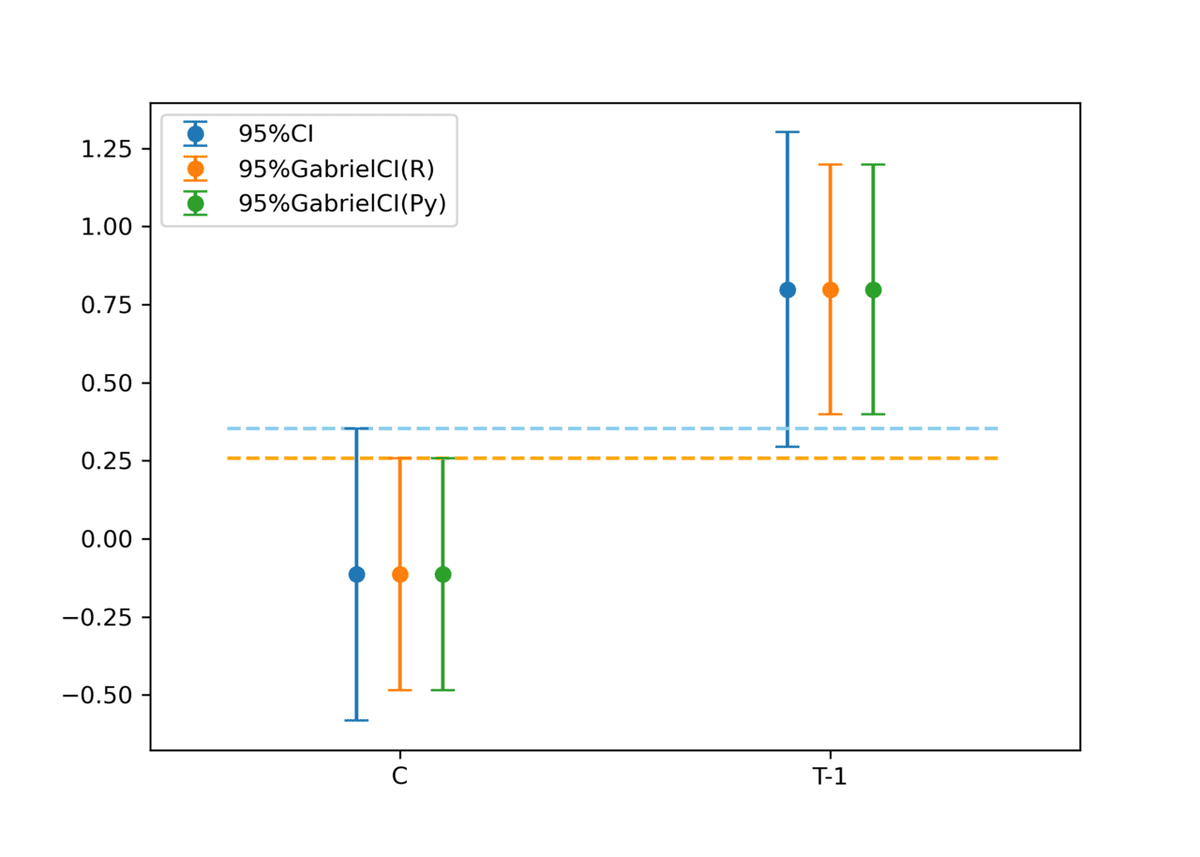
R実装およびPython実装のいずれのガブリエル比較区間においても信頼区間より狭まり、信頼区間では重なっていた区間が重なっていないことがわかります。
上述の記事のとおり、これら2群は5%水準で有意差があるので、ガブリエル比較区間のほうがよりそれっぽい可視化になっていると思います。(p-value至上主義じゃないのでこうしたふわっとした言い方に留めています)

実際に得られた値を比較しても、R実装とほぼほぼ同じ結果が得られていそうです。よかった。
②カテゴリがたくさんあるパターン(多重比較)
次に、多重比較になるケースを考えます。
ちなみに、多重比較そのものの話についてはTJO氏の記事 が日本語だと参考になると思います。
おなじ一様分布で乱数を10個作成した10カテゴリの平均値の95%信頼区間および95%ガブリエル比較区間を可視化します。
もちろん同じ分布からつくられたデータなので差はないです。ガブリエル比較区間における多重比較補正の様子をみてみることが目的です。

先ほどの2群のときとは異なり、ガブリエル比較区間の方が広がっていることがわかります。すなわち、エラーバーの重なりをもとに差があると判断する基準が厳しくなってると言えます。うまいこと補正されているようです。
ただ、上述の記事にもある通り多重比較補正の手法によって結果が異なるため必ずしも検定結果と一致するわけではないようです。こちらでもR実装とPython実装の結果は概ね一致してそうです。よかった。
おわりに
ガブリエル比較区間、なんだかすごいマイナーなのでなんでだろうって思っています。ともかく、python実装を書くことができたのでよかったです。
本記事に関して間違っているところなどあれば、是非Twitter 等で教えてほしいです。
読んでいただいてありがとうございました。
この記事が気に入ったらサポートをしてみませんか?