Alluvial PlotをPythonで描く

TL;DR
・Alluvial Plotはいいぞ
・Pythonで良いかんじに描けるライブラリがなかったからつくった
・https://github.com/nekoumei/pyalluvial
はじめに
皆さんはデータを分析するときに、ある状態の数量などの遷移を可視化したい(たとえばWebページのPVやサービス利用ユーザのクラスタの時系列変化など)とき、どんな可視化を検討しますか。
いろいろあると思いますが、Sankey Diagramは代表的な手法のひとつだと思います。
こういうやつですね
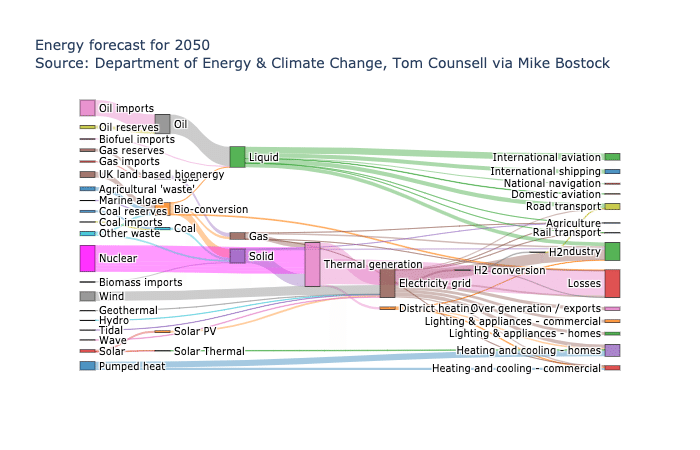
引用: https://plotly.com/python/sankey-diagram/
一方、知名度は低い(というより私が最近まで知らなかった)Alluvial Plotという可視化手法もあります。こんなかんじ。
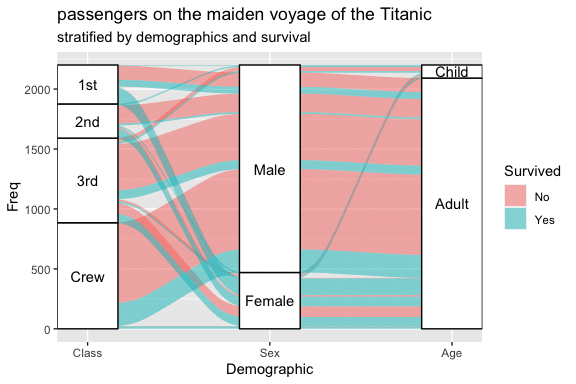
引用: https://cran.r-project.org/web/packages/ggalluvial/vignettes/ggalluvial.html
Sankey Diagramとよく似ていますが、
・各要素ごとにx軸が固定(Sankeyは自由)
・y軸も1カテゴリでまとまり、目盛りで数量が分かるようになっている(Sankeyは自由)
となっていて、雰囲気としてはStacked barに流量のフローがついたみたいな見た目ですね。Sankeyと比べると、整列されているのでy軸でのカテゴリおよびフローの量の比較がしやすいです。
より詳細については、ggalluvial(alluvial plotをかくRのggplot2拡張)のissueで述べられていて非常に参考になるので目を通すと良いと思います。
どちらが良いという話ではなく、ケースバイケースなのでそれぞれ使い分けていきたいですね。
Pythonで描きたい
Sankey Diagramは例えば下記のパッケージで描くことができます。
・matplotlib : あんまり使わない
・plotly: よく使う。ちょっとデータの渡し方がめんどくさい
・ipysankeywidget: Jupyter Notebook内で使えるやつ
一方で、alluvial plotに関してはPythonで描画できるライブラリは見つかりませんでした。(PlotlyのParallel categoriesは結構近いですがSankey寄りですね)
Rだと、上記でちょっと紹介したggalluvialがあります。
Pythonで描けるようになってもっとalluvial plotに流行ってほしいなあということで、Python(matplotlib)でAlluvial Plotを描画するライブラリpyalluvialをつくりました。pipではいるぞ。
以降では、pyalluvialの細かい使い方だったり、便利ポイントだったりの紹介をします。
Usage① データの形式
ggalluvialで言うところのwide formatにのみ対応しています。
titanic datasetを例にすると下記のようなイメージです。
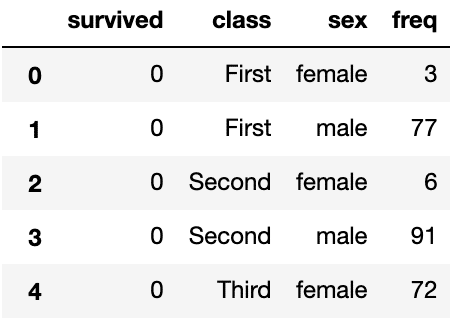
wide formatは割とイメージしやすいかと思います。Stratum, Alluviumをカラムとしてraw dataをaggregationしたような形式ですね。
より具体的に言うと、1行目(index=0)はsurvived=0且つclass=First且つsex=femaleな乗客が3人であることを表しています。
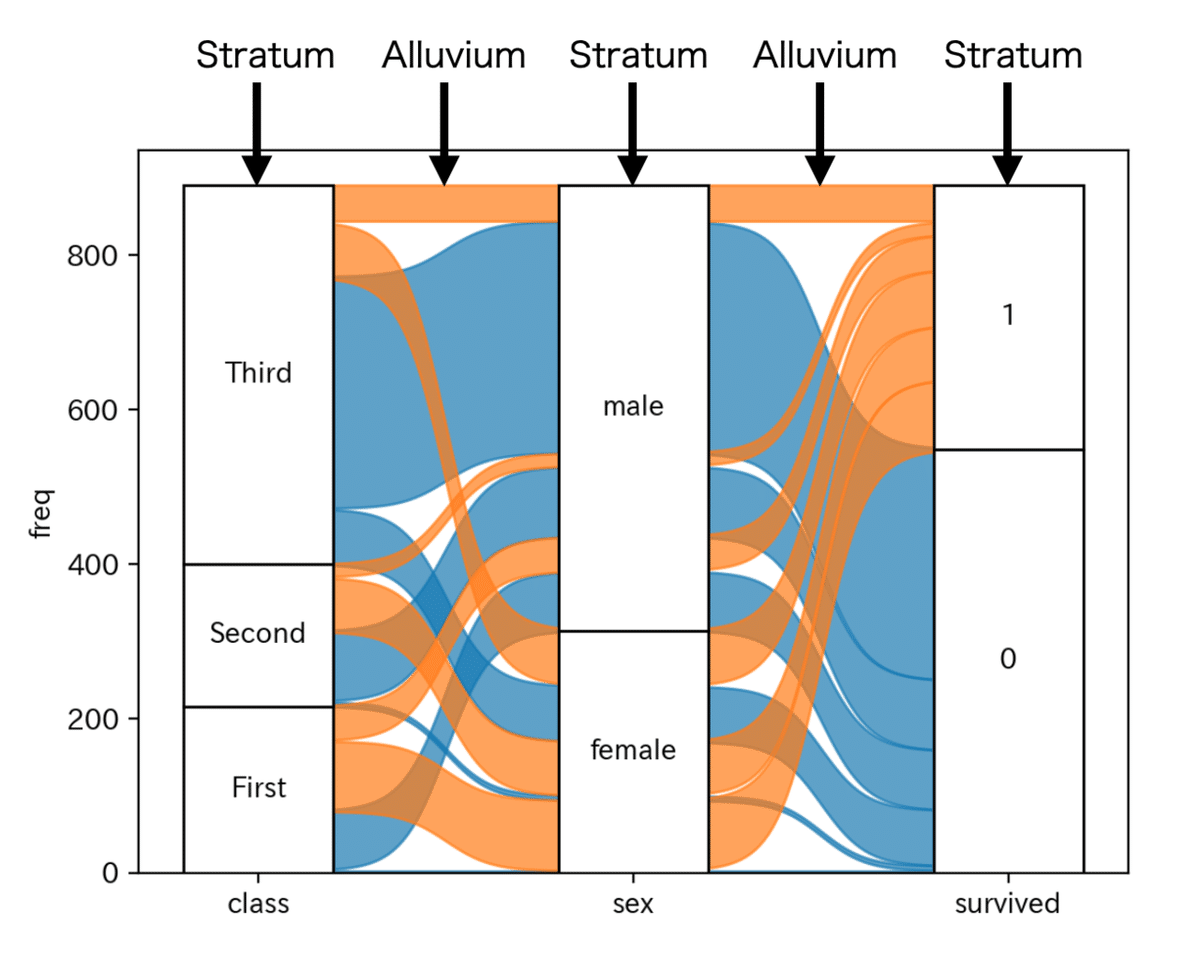
説明のため、簡単にggalluvialと同様の定義でことばを使います。Stratumは各x軸のbar要素で、Alluviumは各フローを表します。翻訳するとどっちも層みたいな意味で???ってなりました。まあ層なんだけど
上記の例でいうと、class, sex, survivedがStratumで、survivedがAlluviumです。実際plotするときは下記のように書きます。
fig = alluvial.plot(
df=wide_df,
xaxis_names=['class', 'sex', 'survived'],
y_name='freq',
alluvium='survived'
)xaxis_namesがStratumです。簡単ですね。
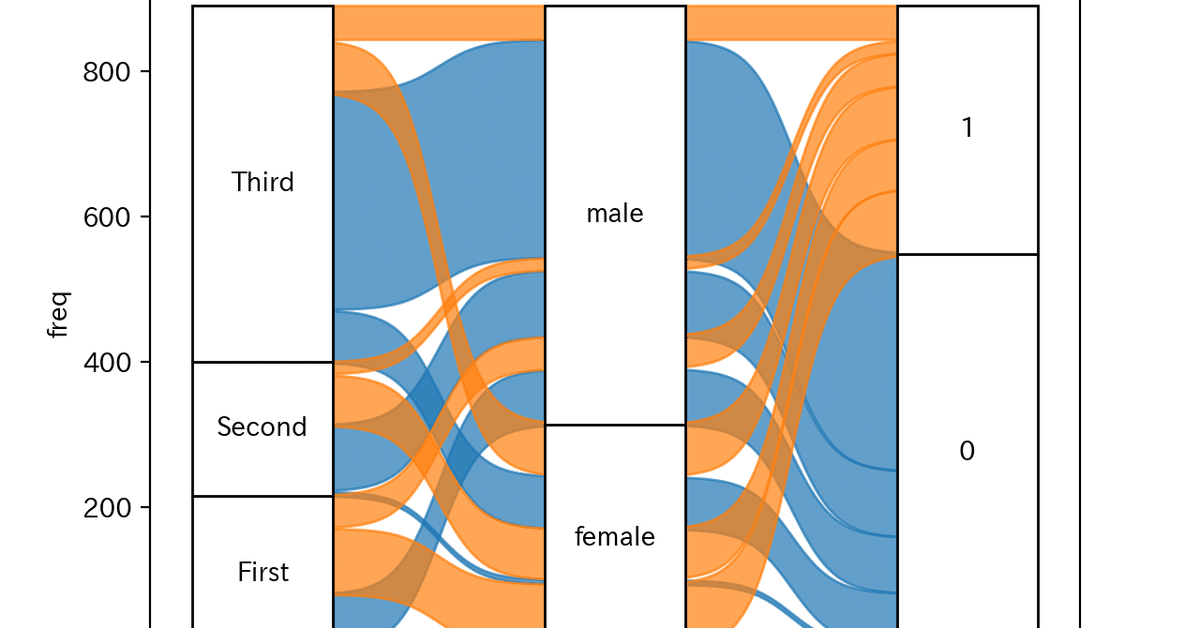
Usage② Stratumの順番を変える
デフォルトの状態だとStratumの順番が気に食わないことがあります。plotlyのsankey diagramとかだとGUIでグリグリ場所をいじったりできますね。
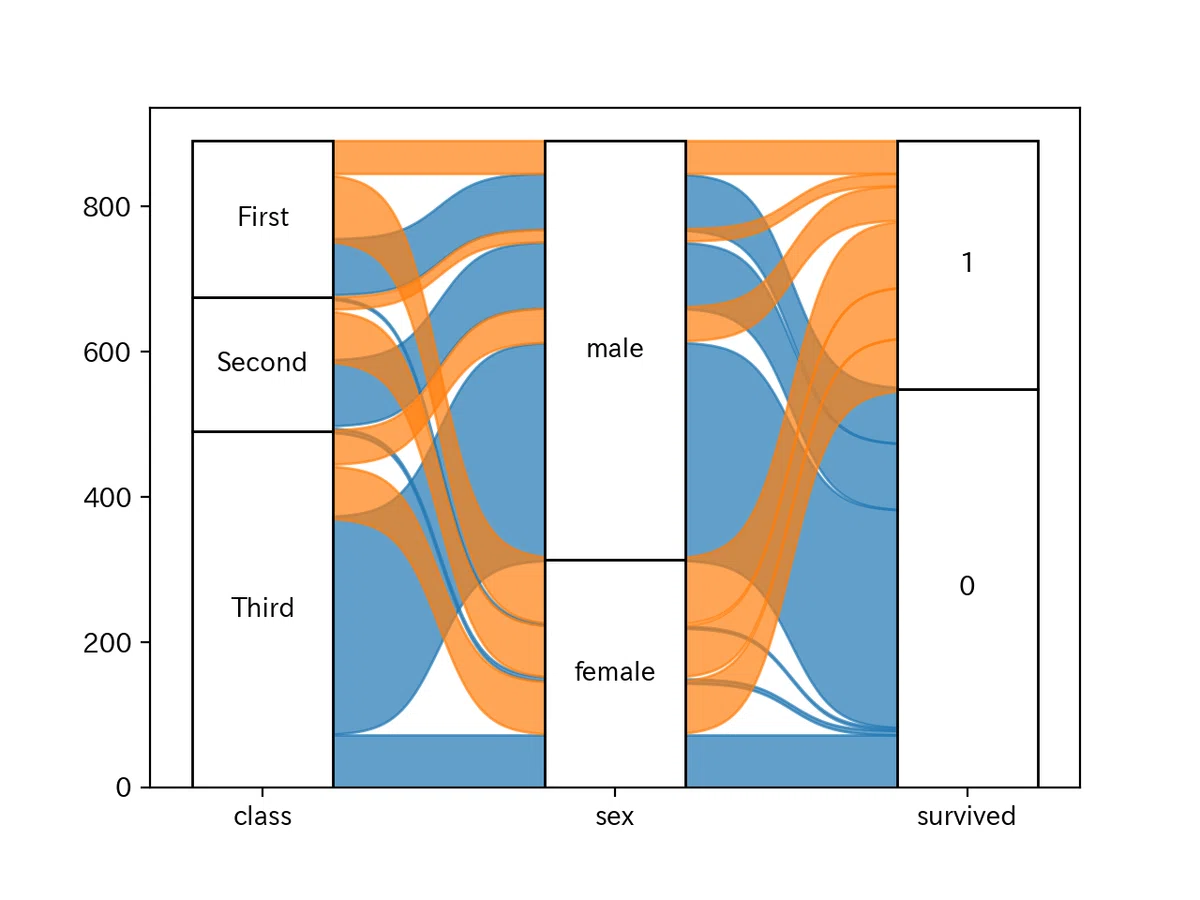
そんなときは下記のようにしてorder_dict引数にdict形式で任意の値を入れてあげてください。
fig = alluvial.plot(
df=wide_df,
xaxis_names=['class', 'sex', 'survived'],
y_name='freq',
alluvium='survived',
order_dict={'class': ['Third', 'Second', 'First']}
)上記コードではclassの順番を逆に指定しています。このコードの実行結果は下記のようになります。
Usage③ フロー間の連続性を無視する
デフォルトでは、AlluviumはすべてのStratum間で連続しています。class=First且つsex=male且つsurvived=1の流量、みたいな表し方ですね。
しかし、全体のフローではなく、Stratum間それぞれのフローを別個にみたいときがあります。ggalluvialの最後のほうで紹介されているようなパターンですね。特に時系列での推移をみたいときに、「全体を通してどんな動きか」 or 「それぞれのタイミングでどんな動きがあったか」着目したいポイントが異なる場合が多く、後者の場合はフローの連続性は無視したいです。
そんなときは、下記のようにignore_continuity=Trueにすれば無視できます。
fig = alluvial.plot(
df=wide_df,
xaxis_names=['class', 'sex', 'survived'],
y_name='freq',
alluvium=None,
ignore_continuity=True
)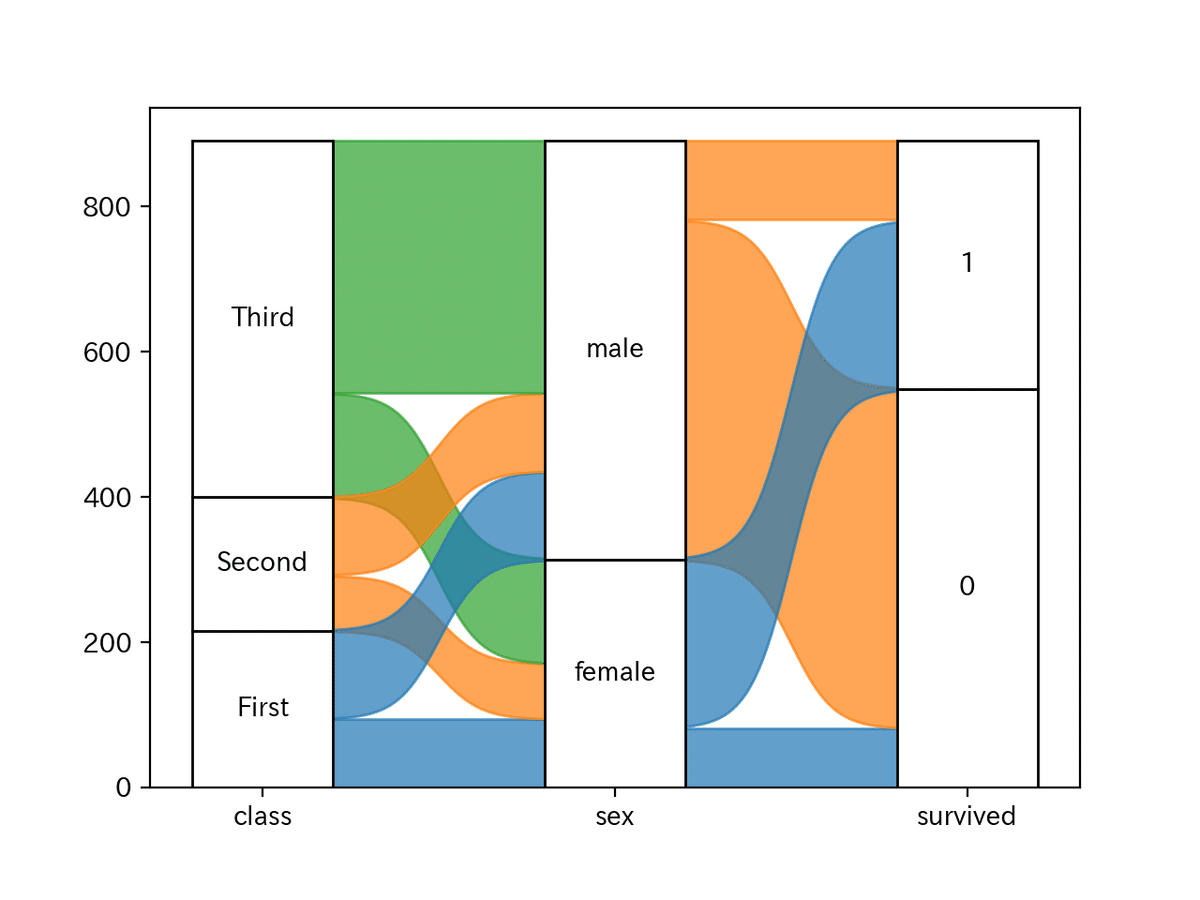
ここでポイントなのが、alluvium=Noneとしている点です。ignore_continuity=Trueの場合、alluviumをNoneとすることでalluviumを各Stratum(左側)に合わせることができます。上記の図でいえばclass-sex間はclassがalluvium, sex-survived間はsexがalluviumとなっています。それぞれのフローでalluviumを再構成しています。
もちろん、これまでのようにalluvium='survived'で描画することもできます。可視化の目的に合わせて柔軟に変えてみてください。
おわりに
Alluvial Plotもっと流行ってほしい。実は私が知らないだけで皆知ってるのかもしれないけど。。
疑問や間違いの指摘など何かあればTwitterとか、Githubで教えてくれると嬉しいです。
ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?