
Neuromatch Academy 2021(US時間)の体験談(Week1編)

みなさんこんにちは!
前回の記事では、神経科学に関する夏期集中講座であるNeuromatch Academy 2021の概要と参加登録方法に関してまとめました。
実際にNeuromatch Academy 2021に参加をしてみて、とにかく講座内容の充実度の高さに驚いています。私は、ニューヨーク大学の大学院の授業で、Computational Neuroscienceの授業を取りましたが、内容としてはその授業に全く引きをとらないものだと感じています。しかし、一方でまだまだ日本人の参加者が少ないという現状があります。
個人的にその一つの要因は、講義資料が全て英語であることが挙げられるかと思っています。そのため、これから数本の記事を通じて、Neuromatch AcademyのComputational Neuroscience講座に関して、どのようなことが学べるのがその概要を日本語でまとめていきたいと思います。日本語で概要を理解することで、少しでも講座内容を理解する上での力になれると嬉しいです。
1日目:モデルの種類
Computational neuroscienceで用いられる具体的なモデルについて学習をしていく前に、まずは、そもそもモデルとは何なのか、どのような種類のモデルがあるのかを一日目では学んでいきます。キーメッセージは、解明したい問い・ゴールによって、使うべきモデルを選択する必要があるということです。
モデルとは何なのか?
・モデル = 現実世界の抽象的表現
現実世界をそのまま理解することは、人間の頭脳にとって複雑すぎ、非常
に困難である。モデルは、そのような事象を部分的、かつ完璧ではない形
で、抽象的に表現し、人間が理解できる形にしたものである
・そのため、モデルを構築する際は、説明したい事象を説明するために必要
最低限の複雑さに留め、できる限りシンプルにすべきである
Computational Neuroscienceでは、どのようなモデルの種類があるのか?
・Whatモデル
大規模なデータを簡易的にまとめ、データから何が読み取れるかを明らか
にする
・Howモデル
脳がどのように複雑な機能・働きを可能にしているかを説明する
・Whyモデル
なぜ脳がそのような活動をするのかを説明する
例:なぜならそれがxxxをする上で最適だから
Inter-spike interval(ISI)の分析における具体例を通じてそれぞれのモデルを理解すると。。。?
・Whatモデル
ISIのヒストグラムの傾向を線形、反比例、指数関数のどれが最もよく捉え
ることができるかどうかを解析した。結果、指数関数を用いて、傾向が最
もよく説明できることがわかった
・Howモデル
Leaky Integrate-and-Fire (LIF) neuron modelを用いて、ニューロンがどの
ようにスパイクを生成しているかを表現するモデルを構築した。結果、観
測されたISIヒストグラムと同様の傾向を持つスパイク活動を再現すること
ができた
・Whyモデル
ニューロンがスパイクできる回数に制限がある環境下で、ISIがどのように
分布をしていると、最も多くの情報量を含むことができるのかを検討し
た。結果、指数関数的なISIの分布が情報量を最大化できることがわかった
それぞれのモデルのComputational Neuroscienceにおける使われ方
・多くの研究では、まずはWhatモデルを用いて、収集したデータを説明する
ことを目指す
・次に、Howモデルを用いて、どんなメカニズムがWhatモデルが説明するよ
うな事象を引き起こしているのかを考える
・最後に、Whyモデルを用いて、なぜHowモデルを用いて考えたモデルが脳
によって用いられているのかを考える。
例:あるモデルは、取得できる情報量を最大化できるようなアルゴリズム
になっているため、生物学的に効率が良い等
・必ずしもそうという訳ではないが、一般的に、Whyモデルを構築すること
が最も難しく、Whatモデルを構築することが最も容易である
・ただし、モデル構築の難度以上に、どのような質問に答えたいかに基づい
て、3つのうち、どのモデルを用いるかは検討すべきである
2日目:モデリング実践
1日目で、解明したい質問に基づいてモデルを選択することが重要であることを学びました。つまり、具体的なモデリングの手順に進む前に、質問が明確になっていることが非常に重要です。2日目では、質問とゴールの立案、文献レビュー、また仮説立ても含めて、どのようにモデリングを進めていく必要があるかを学びます。
Computational Neuroscienceの研究におけるモデリングの大きな流れ
1. 問いを立てる
2. モデルを実装する
3. モデルをテストする
4. 結果をまとめる
この中でも特に、プロジェクトをデザインしていく、"1. 問いを立てる" がどれだけ検討されているかによって、2-4のステップは非常に簡単になる。
そのため、以降では、1を中心により細かいステップを紹介していく。
"1. 問いを立てる" の具体的な進め方
step1. 問いとゴールを定義
・問いに答えるためにどのようなデータが必要か?(できるだけ具体的に)
・どのようにモデルを評価するか?
・どのような実験を通じてモデルの妥当性を評価することができるか?
step2. 文献レビュー
・過去の研究から現状どこまでわかっている?
・どんな仮説が過去の研究から考察されている?
・ベースラインとなるような過去に試されたモデルはある?
・問いに答えるためにどのようなスキルセットが必要?
step3. 必要な要素の洗い出し
・問いに答えるために、どのような変数を検討する必要がある?
・どのような変数をモデルのinput&outputとして用いる?
・それぞれの変数は実験から観測されるものか、モデルを通じて推測する
必要があるものか?
step4. 仮説の定量化
・step3で洗い出した要素を関係づけて、具体的な仮説を言葉にする
・具体的な仮説を数学的な表現で表す 例:y(t) = f(x(t), k)
実際のプロジェクトでは。。。?
・step1-4を一度だけ検討すれば良いとは限らない
・多くの場合、モデリングを進めていく過程でstep1-4を何度も再検討して
いき、徐々に磨き上げていく
3日目:モデルフィッティング
1・2日目を通じて、モデリングにおいて、問いにあったモデルを構築していくことが重要であり、そのためにどのような手順を追って進めていけば良いかを学びました。3日目では、問いたい質問や用いたいモデルを具体的に決定でき、実際にモデリングを行っていく際に、どのように構築したモデルをfitし、その性能を評価・比較していけば良いのかを学んでいきます。
モデルをfitするための手法例
1. 予測エラーを最小化する
モデルを関数として考え、その予測エラーを最小化する方針。予測エラー
を測る指標として、平均二乗誤差(Mean Squared Error, MSE)が挙げられ
る。
※ MSEは、それぞれのエラー値の2乗値を元に計算されるため、外れ値
(特に大きなエラーを持つ値)に影響を受けやすい評価指標である。
2. 尤度(likelihood)を最大化する
モデルを発生器(generator)として考え、尤もらしいモデルを見つける方
針。モデルが観測データを生成したと考えた場合に、最も尤もらしいモ
デルのパラメーターの組み合わせを見つける。
モデルの不確実性(uncertainty)を評価するための手法例
・データ量が限られた環境下では、fitされたモデルのパラメータは不確実性
を含んでいる
・そのため、不確実性を評価するための手法がモデルの評価において用いら
れている
手法例1. 統計テスト
統計テストを用いて、fitされたパラメーターが統計的優位な意味を持つ
かを確認する。つまり、パラメーターの値が0であるという帰無仮説を棄
却できるかどうかを確認する。
手法例2. ブートストラッピング(Bootstrapping)
同じデータセットから、リサンプリングを何度も行い、複数のデータセッ
トに対してモデルをfitさせた際のパラメーターのばらつきから、95%信頼
区間を推定する。計算量が多くかかる。
複数のモデルの中からベストモデルを選択するための考え方
・Bias:モデルの精度が及ばず、説明をすることができていない構造的な
エラー (underfitting)
・Variance:モデルが構造的なエラー以外のノイズを捉えることで発生して
しまっているエラー (overfitting)
・エラーの合計 = Bias + Variance
・Bias-varianceトレードオフ
ベストモデルは、BiasとVarianceのバランスを取る必要がある。
構造的なデータの傾向を最大限に説明をしつつ、ノイズの影響を最低限し
か受けないモデルがベストモデル。
複数のモデルの中からベストモデルを選択するための手法例
手法例1. 適合度 (Goodness of fit)
モデルの尤度を計算し、モデルに用いられたパラメーター数による調整
を加えた指標を用いて、モデルを評価する 例:赤池情報量規準(AIC)
手法例2. クロスバリデーション (Cross validation)
トレーニングデータとテストデータを分け、未知のデータであるテストデ
ータに対する性能を用いてモデルを評価する。計算量が多くかかる。
具体的なモデルfit & 評価プロセス例
step1. 示したい仮説に基づいた計算モデルを考える
step2. step1で考えたモデルと性能を比較するためのコントロールモデルを
数個考える
step3. 実験データを用いて、step1, 2で考えたモデルをfitする
step4. step1で考えたモデルが仮説として考えていた現象をうまく説明でき
るかをを確認する
step5. step1で考えたモデルは、step2で考えたモデルよりも仮説として考え
ていた現象をうまく説明できるかを確認する
step6. step1で考えたモデルのパラメーターに、実験のコンディションや、
被験者毎に何か違いがみられるかどうかを検証する
4日目:一般化線形モデル
1-3日目は、Computational Neuroscienceにおけるモデリングの基礎・基盤となる内容を学んできました。4日目からはComputational Neuroscienceにおいて用いられる詳細なモデルに関して学んでいきます。
具体的には、4日目は、一般化線形モデルについて学んでいきます。一般化線形モデルは、多くの機械学習アルゴリズムでも用いられている単純ながらも非常に有効な手法です。神経科学においても、様々な問いに答えるために一般化線形モデルは広く用いられています。
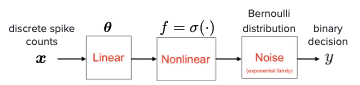
一般化線形モデルとは?
・入力に対して、線形フィルタ、非線形関数、そしてノイズ項を組み合わせ出力を行うモデル

・出力の形式、出力データの分布、非線形関数の組み合わせによって、様々
な一般化線形モデルを構築することができる
・例えば、以下のイメージにあるように、コインの裏表のような二値(表 or
裏)からなる出力を考える場合、表(もしくは裏)が出る確率は、ベルヌーイ
分布で表現をすることができ、非線形関数としてロジスティック関数を用
いることで、ロジスティック回帰を用いて予測を行うことができる

ポアソン一般化線形モデルを用いたエンコーディング (encoding)
・一定期間の刺激に対するニューロンのスパイク数を予測するエンコーディ
ングモデルを考える
・ポアソン分布を用いて、一定のタイムインターバル内で起こるスパイク数
を表現することができる
・ポアソン分布を用いることで、以下のようなポアソン一般化線形モデルを
用いて、あるタイムインターバル内(t)に起こるスパイクカウント数(y)を予
測することができる

ロジスティック回帰モデルを用いたデコーディング (decoding)
・サルの二つの選択肢(例:右 or 左)に対する意思決定をスパイク数のデータから予測するデコーディングモデルを考える
・サルの二値間における選択は、ベルヌーイ分布を用いることで表現することができる
・ベルヌーイ分布を用いることで、以下のようなロジスティック回帰モデル
を用いて、スパイク数のデータ(x)からサルの意思決定(y)を予測することが
できる
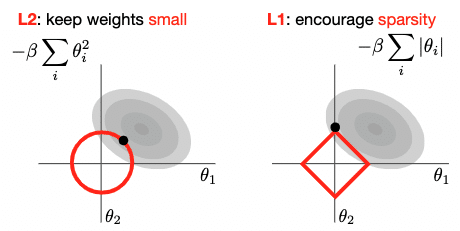
正則化 (Regularization)で用いられる手法例
・overfittingを避けるために、正則化は重要な手法である
手法1:L1正則化
パラメーターが疎になるように制限をかける
(つまり多くのパラメーターが0になるように調整をする)
手法2:L2正則化
パラメーターのweightsが小さくなるよう制限をかける
5日目:次元削減
5日目は、高次元データを低次元データに変換する手法である次元削減に関して学びます。次元削減は、高次元な神経レコーディングデータを扱う神経科学において頻繁に用いられる機械学習手法です。
なぜ神経科学において次元削減は有効な解析手法なのか?
・ニューロンはネットワークを形成しているため、それぞれのニューロンは
独立して活動することはできない (それぞれのニューロンの活動には何か
しらの相関関係が生まれる)
・つまり、脳活動は、実際のニューロンの数よりも少ない自由度で表現する
ことができる
・そのため、高次元で記録された脳活動データを低次元に変換する次元削減
が有効な解析手法として用いられている
次元削減の神経科学分野における活用例
・実験1トライアルにおけるニューロン集団(高次元データ)の活動を解析する
例:Afshar et al., Neuron 2011; Harvey et al., Nature, 2012
・ニューロン集合の活動構造に関する仮説を立証する
例:Mante et al., Nature 2013; Sadtler et al., Nature 2014
・大規模なデータセットを低次元データに変換することで、探索的データ解
析を行う
例:Ahrens et al., Nature 2012
次元削減手法例
・主成分分析 (Principal components analysis (PCA))
複数トライアルの平均値を分析する際に向いている。観測データのノイズ
の存在は考慮されない。
・因子分析 (Factor analysis (FA))
単一トライアルの分析を行う際に向いている。観測データのノイズは考慮
されるが、時間的平滑化は行われない。
・ガウス過程因子分析 (Gaussian-process factor analysis (GPFA))
FAと同様に単一トライアルの分析を行う際に向いている。時間的平滑化が
行われる。
・潜在的な動的システム (Latent dynamical systems, eg. LDS, LFADS)
神経活動の時間的な変化を引き起こす、動的なルールをモデルとして扱い
たい場合に用いることができる。
・非線形手法 (eg. Isomap, LLE, t-SNE)
線形的な傾向だけでは捉えることができないような傾向を扱う場合に用い
ることができる。ただし、それぞれの手法の利用条件が神経活動データの
場合満たされないことが多いため、その点は利用前に注意が必要である。
・教師あり学習手法 (eg. LDA, dPCA)
実験に用いられた入力や、行動、また時間を表す次元を特定したい際に向
いている。
手法の具体的な説明:主成分分析(PCA)とは?
・PCAは、共分散行列に基づくデータクラウドに対して、最大のデータの分
散を表現することができる正規直交基底を探す
・数学的には、そのような正規直交基底は、共分散行列の固有ベクトルと一
致する
・それぞれの基底に射影された際に表現されるデータの分散は、その基底に
紐づく固有値と一致する
・そのため、それぞれの基底に紐づく固有値を、全基底に紐づく固有値の合
計値で割ることで、全体の分散のうち、ある基底がどれだけの割合の分散
を説明することができるかを理解することができる
・ある基底に紐づく固有値が0であるということは、その基底がデータの分
散を全く説明しないことを意味する。そのため、そのような基底(次元)
は、元のデータに含まれた情報を全く失うことなく、削減することができ
る
・データ表現に必要な次元数を決定するためには、スクリープロット (Scree
plot)や次元数によって説明される分散を表現した以下のような積み上げグ
ラフを用いる
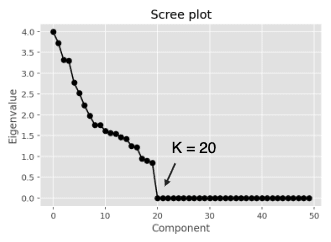
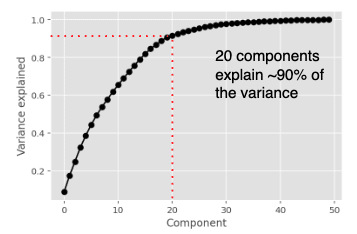
最後に
内容のまとめがとても長くなってしまいましたが、ここまでがWeek1で扱われた内容の私個人の理解ベースの概要です。Week1では、これからより具体的な神経活動モデルを学んでいくための基盤を作るための内容が多くあるような印象を受けました。
またWeek2、Week3に関する講座の内容も同じようにまとめていきたいと思うので、そちらももしよければ読んでみてください。
今日は以上です。
追記(2021.08.21):
Week2の記事をアップしました。
追記(2021.08.28)
Week3の記事をアップしました。
この記事が気に入ったらサポートをしてみませんか?