
ChatGPTによる人事データ分析(どこまでお任せできるのか)

ChatGPTが人事データ分析にどの程度使えるか試してみたのですが、あまりの出来の良さにびっくりしましたのでご紹介します。
ChatGPTでAdvanced Data Analysisというプラグインを使うことで対話的にデータ分析をすることができます。言葉で分析したいことを投げかけるだけでChatGPTが分析を進めてくれるというイメージです。すごい世の中になったものですね。
このプラグインは元々Code Interpreterという名前で、登場した時にはかなり話題になりました。今回は、以前noteに書いた人事データ分析例を元に、同じようなタスクをChatGPTにお願いしてみたので、その様子を記事にしました。私の分析例と比較してみるのも面白そうです。
結論からいうと、ChatGPTはデータ探索の用途にはかなり使えそうな印象をうけました。データ分析に不慣れな人に頼むよりも的確に分析してくれますし、コードでエラーがでても解決してくれます。
ただし、分析の指示をするにしても結果を確認するにしても、利用者の経験以上のことを頼むことは難しいこともわかりました。また、データセキュリティの観点からは注意が必要であることも理解しておくべきでしょう。
以下、ChatGPTとやり取りしながら分析していく様子をご覧ください。
人事データ分析のお題
私が作った人事データ(トイデータ)を使い、傾向分析をするというものです。具体的には、従業員エンゲージメント調査結果を含む人事データを用いて、組織の中のエンゲージメントの現状と問題点をざっくり把握するというタスクを想定しました。この分析例は以前にnote記事で取り上げたものです。
今回分析に用いたデータは以下からダウンロードことができます。

さて、このデータの特徴は私がいろいろ考えながら手作りで作ったもので、ざっと分析してもぼんやりとしか分からないようなものになっています。感覚的にいうと、データの列同士の関係をそのまま可視化したり相関係数を見たりしただけではよくわからないような仕掛けをいれています。また、手作業で作った関係でそれほど綺麗なデータにもなっていません。その一方で、欠測や異常値はないものになっています。これをChatGPTがどのように処理してくれるのか楽しみです。
Advanced Data Analysis とは?
改めて今回利用したAdvanced Data Analysisを紹介します。
Advanced Data AnalysisはChatGPTのプラグインの一つで、対話的なデータ分析を実現するものです。チャットで分析のお願いをするとザクザクっと分析してくれるというもので、まさにAIだなと思わせるサービスです。本プラグインを使うにはChatGPT Proが必要です。ChatGPTの設定で有効にしていれば、以下のように選択できるようになります。
チャットを開始された後、分析してほしいデータをアップロードして具体的な分析の依頼事項を教えることで、ある程度自動的に分析してくれます。
注意が必要な点として、アップロードしたデータのセキュリティに気を遣う必要があることがあげられます。Proのプランであってもアップロードしたデータはサービスのための学習に利用される可能性があるため、個人情報や機密情報をアップロードするのは控えた方がよさそうです。実務で利用する場合は、データ保護の観点でローカルで動くサービスやChatGPTのEnterprise版を検討すべきでしょう。
ChatGPTへの分析依頼内容
HRトイデータ_人事情報.csvをアップロードすると、ChatGPTがデータ項目を確認した上で、分析内容を問いかけてきました。

そこで、プロンプトに以下のような分析内容を投入しました。「分析に至った背景」と「データの概要」は元ネタのnote記事の内容をコピペしました。分析の狙いとしては、現在の状況を把握することが主たる目的で、可視化や相関分析までの想定したものとなっています。(一部略しています)
# 分析テーマの概要
あなたは人事部門に所属するデータ分析者です。 今回の分析では、従業員のエンゲージメントに関する調査を担当することになりました。 分析の目的は、現在の従業員のエンゲージメント状況を把握し、問題点を洗い出すことです。 具体的には、全社で相対的にエンゲージメントが低い属性やクラスターを見つけてください。
# 分析に至った背景
以上の分析を行う上で、なぜこのような調査が必要になったのか、以下に述べます。
- エンゲージメントを高くすることは重点人事施策となっている。
- エンゲージメントは従業員に対するアンケート調査により計測されており、最新(2021年)の調査結果を用いて調査することとなった。
(略)
# 分析アプローチ
現状把握のため、データのグラフによる可視化や回帰分析を中心に分かりやすい表現で整理してください。
# データの概要
## HRトイデータ_人事情報.csv 今回の分析における中心的なデータです。人事基本情報やエンゲージメントの情報もあります。各項目の詳細を以下に述べます。
従業員ID: 従業員を一意に識別するID。(カテゴリ変数)
年度: データを記録した年度。他の情報は年度末時点の情報。年度は4月から始まり3月までとする。会計年度も同様。
(略)
これに対し、ChatGPTは以下のようにアプローチをまとめたうえで、分析に取りかかりました。コミュニケーションのミスを防ぐ点で優秀ですね。ここで違うと思ったらチャットを止めて指示をし直すことも可能です。

分析開始(豆腐問題の発生と対処)
今回の分析目的であるエンゲージメントの分布を確認することから始めたようです。初手としては悪くありません。ランダムな挙動をするようで、初めて動かしたときはヒストグラムをつかっていましたが、今回は棒グラフのようです。

しかし、ご覧のように日本語表示が崩れしまっています。俗にいう豆腐問題ですね。これはPythonの環境で日本語フォントが正しく設定されていない場合に起きる現象です。(先日の記事)
これでは分析結果を見てもよくわからないので、チャットを止めて修正を依頼しました。

直接解決できなかったようですが、英語ラベルに変更して分析を進めてくれました。この回避能力にも素直に感心しました。
グラフを変えてもらう
分析が再開され、ChatGPTはエンゲージメントと他の変数の関係を可視化で分析していきました。しかし、エラーバー付きの棒グラフで平均を比較する形で分布が分からなかったので、箱ひげ図に変えてもらいました。急な割込みにも気分を害することなく、要望に応じてくれました。有難し。

ここで、ChatGPTのグラフ選択にはランダム性があるということに気づきました。というのも、同じ分析を3回ためしてそれぞれ違ったからです。1回目に分析したときは箱ひげ図を使っていて、2回目はグラフを使わず基本統計量だけで分析していました。プロンプトは同じ内容だったので、どの辺が影響するのか気になるところです。とはいえ、気に入らなければ止めて修正を依頼することもできるので便利ですね。
さらなる分析を促す
順調に進んでいたのですが、カテゴリ変数の分析だけで止まってしまいました。1回目に分析したときはもう少し深掘りしてくれていたので、分析を続けるようお願いしました。少し曖昧にお願いしてみると、散布図と相関係数で分析する方法を取ったようです。

エンゲージメントと年齢の分析結果が次のようになります。
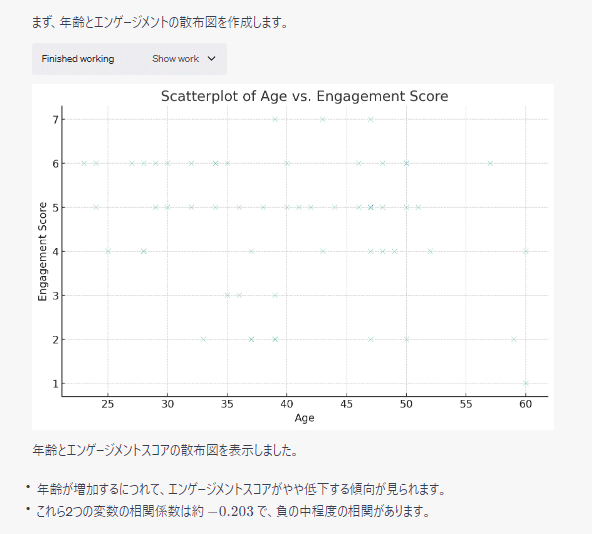
こちらも次々に分析が進み、最後の項目を分析した後に総括したうえで回帰分析のアプローチを示唆してくれました。初めの分析アプローチの指示内容にあったかもしれません。
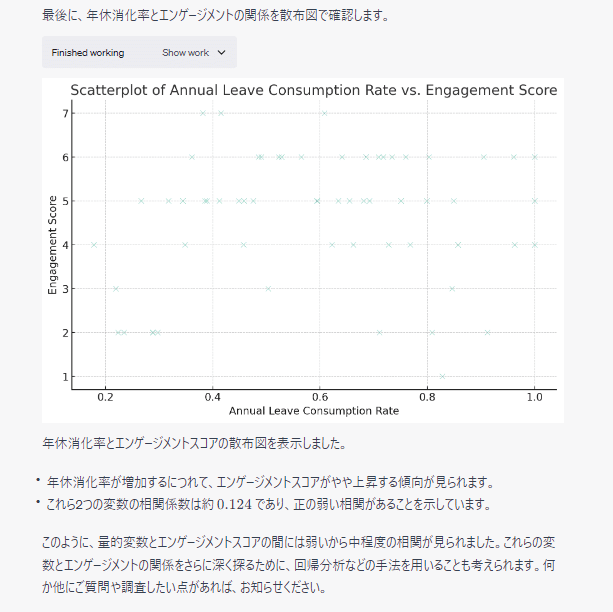
回帰分析をやってみる
ここまでスイスイ進んできて便利だなと思いましたが、よく考えてみると探索的データ分析をやってくれるydata_profiling(旧 pandas_profiling)でもやれそうです。ということで、さらに踏み込んで回帰分析を頼んでみることにしました。

チャット内容から見ると、何となく予測モデルを作っているのように感じました。コードを確認してみるとscikit-learnを使ってガリガリやりそうな雰囲気でした。

これでも良いのですが、今回は予測タスクでなく確率分布を仮定したシンプルなモデルで徐々に分析したかったので、変更をお願いしました。1回目にトライしたときははじめからstatsmodelsを使っていたので、やはり挙動にランダム性があるようです。
具体的なライブラリとして、statsmodelsを使ってみるように促しました。タイプミスがあっても察してくれる感じがいいですね。

statsmodelsを使った解析コードと結果は以下のようになっています。結果の良し悪しというよりも、こうした感じで動いていると思うとちょっと感動しました。

出力結果について長く説明していたので、要約と考察をお願いすると以下のようにまとめてくれました。モデル評価とともに多重共線性の問題を指摘してくれました。

多重共線性の問題解決を一緒に考える
ChatGPTが多重共線性の問題を指摘してくれたので一緒に考えることにしました。適当なアイデアを3つ出してみると、順に適用してくれました。

ここで、アイデア1の「相関の高い変数を削除する」というのは、今回のような傾向分析においてはよくよく考えてやらないと意味のない分析になってしまいます。業務上見るべき変数を落としてしまう可能性があるからです。この点についてChatGPTはどうするか気になったのですが、ChatGPTから先手を打って「ビジネス的な背景や変数の重要性」について言及してきたので驚きました。凄い。
しかし、情報を与えていないのでランダムに削除したようです。「今回はシンプルに」という言い回しにもニンマリしてしまいました。時々言いますよね、時間がないときとか。

次にアイデア2の主成分分析による例です。主成分分析は多重共線性の解消に有効な場合もありますが、傾向分析ではその解釈が難しくなる恐れもあります。今回はモデル自体が今一つということで踏み込んだ分析に至らず。
ある程度自動的に処理しつつ説明も流暢なのがすごいところです。しかし、1回目に頼んだときと累積寄与率のグラフが違うのが気になりました。このあたりの検証にはコードをよく見てみる必要がありそうです。

最後にアイデア3の正則化です。適当にリッジ回帰とElastic Netについて言及したらどちらもやってくれました。話はそれますが、こういう「~してみるといいかもよ」というレビュアーコメントで仕事が増えることってよくありますよね。

以上のように一緒に考えながらやってもらうというのは新鮮ではありました。しかし、冒頭にお伝えしたように、今回のデータは単純にデータ列同士の関連を調べてもよくわからないような仕掛けになっています。そのため、ここまでの分析結果はぼんやりしてしまっています。
重要なヒントを与えて分析再開
ここで、分析をする上で大きなヒントを与えることにしました。具体的には、管理職のコンピテンシーに注目するように示唆を与えました。実は今回のデータは所属やグループの管理職のコンピテンシーが組織人員へ影響を与えるように作りこんでいたのです。
つまり、データの関連が入れ子になっているため、単に行単位で分析しても結果がでないようになっていたのでした。また、それに加えて時間外や年齢なども若干関連を持たせていたので、より一層複雑になっています。少し作為的ですが、実際の人事データはもっと複雑なことになっているはずです。
今回は天下り的に情報を与えたのですが、人事データ分析ではしばしばミドルマネジメントに焦点を当てることがあるので、経験を積んだ分析チームなら思いつくかもしれません。
ということで、以下のような情報をプロントに入力しました。新しい情報だけでなく、分析アプローチも具体的に指示してみました。ただ詳細な処理手順は伝えていません。
ありがとうございます。現場ヒアリングの結果、新しい情報を得ることができました。以下の情報を参考に分析を再開してください。
# 新しく得られた情報
現場ヒアリングによると、エンゲージメントは各所属やグループの管理職のビヘイビアと関連があることが示唆された。端的には、管理職によってその組織内従業員のエンゲージメントが変わる可能性がある。ただし、管理職のビヘイビアはデータ化されていない。
# 分析アプローチ
グループ別に、管理職のコンピテンシーを分析したうえで、グループ単位の特徴量を作成する。その上で、グループ単位で見た場合に、管理職のコンピテンシーとエンゲージメントに関連があるかどうかを調査する。分析手法は適切な方法を選択してみてください。
集計時のエラーと対処
先ほどの指示により、ChatGPTはpandasのgroupbyを使ってグループ別に管理職の特徴量を作るような処理を開始しました。この手順は元ネタの記事と同様な方法になります。しかし、エラーがでて何度か修正していました。

このエラーはgroupbyの項目指定のミスによるものでした。このミス、実は当初のプロンプトで私がデータ項目の説明したときにミスしていたものでした。逆にいうと、初回のプロンプトで説明したデータ項目の内容を参照しながらgroupbyを行っていたということになります。これは本当に驚きました。どこまで意味的なものを理解しているのでしょうか。
この問題を解決してgroupbyを行った結果は以下のようになりました。

特徴量を見直したうえでの回帰分析
グループ毎に管理職のコンピテンシーとエンゲージメントの関係を回帰モデルで分析してくれました。先ほどの分析よりかはシャープな洞察が得られそうです。少し面白いなと思ったのは、p値が0.053と有意水準を超えた項目に対しても、「ほんの少し超えていますが・・」と人間臭いコメントをしているところです。良くも悪くもですが。

因果関係についての質問
ChatGPTが踏み込んだアクション提案までしてくれたので、こちらも踏み込んだ質問をしてみました。相関分析的な洞察だが因果関係と捉えていいの?という指摘です。アクションを促すということは因果と捉えているのではと疑問に思ったからです。
これについても、ChatGPTは素直に相関は因果でないと言い切っています。そのとおり。今回の得られた考察を仮説としてA/Bテストしてみればというアドバイスですね。少し安心しました。
実務でもこの問題は常につきまといます。クライアントから求められても、分析者は相関と因果を混同させてはいけません。

仮定をおいて階層モデルで分析してみる
ここまでで概ね分析は完了です。しかし、ChatGPTでどこまでできるか知りたくなって、階層モデルによる検証をお願いしてみました。データ数も少ないですし少々強引なのですが、以下のようなお願いをしました。未観測の個人差や組織の差を統制できないか?というアイデアです。
ありがとうございます。おっしゃる通りですね。
それでは、一つの試みとして観察データに対する因果モデルの適用を試みてみましょう。
# 背景
一般的な調査結果から、エンゲージメントは様々な要因から影響を受けるものの、それらは概ね「個人」に対する要因と、「所属・グループ」が持つ要因に分けられることが分かった。すなわち、個人や所属・グループ毎に隠れた変数が存在し、今回の分析において交絡的な要素がある恐れがある。
# 分析アプローチ
最後に実施した回帰分析のモデルをベースに、以下のモデルの適用を試みる。ただし、データが不足する恐れがあるため階層的なモデルを作るなど工夫すること。
## モデル1
グループ毎に回帰係数が変動するモデルを適用する。これによりグループが持つ因子の影響を排除する。
## モデル2 従業員毎に回帰係数が変動するモデルを適用する。これにより従業員が持つ因子の影響を排除する。
## モデル3
上記モデル1とモデル2を組み合わせたモデルを適用する。
これに対してもChatGPTは柔軟に対応してくれました。いやー素晴らしい。載せていませんが、サンプルサイズの問題なども指摘しています。

分析のまとめ
長いコミュニケーションとなりましたので、ここまでの分析結果をまとめてもらいました。分析の詳細はちゃんと確認しないといけませんが、人が書いたようなレポートで恐れ入りました。今回のお題は「管理職のコンピテンシー_チームワークとエンゲージメントの関係を発掘すること」が正解だったので、紆余曲折を経てChatGPTはたどり着いたことになりますね。

おまけ: ベイズ推定
最後に階層モデルにたどり着いたものの収束に問題があったようなので、ベイズ推定の結果を見たくなりました。そこでChatGPTに頼んでみたのですが、環境の制約でできなかったようです。ちなみに、1回目のときはpymc3でなくpystanを使おうとしてたようでしたので、動作にランダム性がありそうです。

まとめ
今回はChatGPTのAdvanced Data Analysisを使って人事データの分析を試してみました。自前のトイデータを用いた模擬的な分析でしたが、想定以上に踏み込んだ分析をしてくれて本当に驚きました。エラーの対処や回避も優秀でした。AIがここまで進歩するとは驚愕です。ピープルアナリティクスにおける起爆剤となるかもしれません。
その一方で、利用者はある程度の分析経験が必要ということもわかりました。ChatGPTに適切に指示を与え、その結果から軌道修正することができる必要があるからです。データ列の可視化程度なら問題も少ないのですが、そこまでならpandas_profilingでもできてしまいます。対話的な利用が鍵となりそうですが、そのためには利用者のスキルが必要とも言えます。また、データセキュリティの観点は必ずチェックすべきでしょう。
ところで、話は変わりますが、この記事のアイキャッチ画像は生成AIを使って作ったものです。Canva ProのText to Imageを使ってみたのですがなかなか便利でした。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?