
【AI】BERTの応用モデルでクレジットカードの不正利用検知をおこなう① ~論文紹介~

はじめに
こんにちは、エンジニアのすずきです。
自然言語処理で利用されるBERTを多変量表データの学習に応用した、Hierarchical Tabular BERT(TabBERT)というモデルの紹介論文を簡単にまとめた記事となります。
論文では、時系列表データの生成モデルであるTabGPTやTabBERTによる大気汚染濃度の回帰分析についても紹介されていますが、今回は自分のやりたいことと近い、TabBERTによるクレジットカードの不正利用検知(分類)の部分のみをまとめました。
前提知識
BERTどころか自然言語処理の知識もゼロのところから論文を読み始めたらAbstractの部分でいきなり詰んだので、読み進めていく上で必要となった知識についてもまとめました。
このあたりの知識がある方は、スクロールして「論文紹介」のところからご覧ください。
自然言語処理とは
日常生活で使用する言語に関する問題(タスク)をコンピュータで解くことを自然言語処理といいます。
身近なところでいうと、Amazon Echoのようなスマートスピーカーや最近のWebサイトでよくみるチャットボットなどで使われる技術です。
他のタスク例としては、以下のようなものがあります。
形態素解析:文章を単語に分割して品詞や活用形を判定
言語モデル:文章の自然さを確率によって表現
固有表現抽出:文章から人名などの固有名詞、日付、数値表現を抽出
文章の類似度比較:文章感の内容の類似度を定量的に評価
文章分類:文章を与えられたカテゴリーに分類(例:ネガポジ判定)
文章生成:与えられた文章や条件に続く文章を生成
文章校正:文中の表記ミスを修正
Transformerとは
自然言語処理で使用するDeep Learning(DL)モデルとして、2017年にGoogleが論文「Attention Is All You Need」で提案したのがTransformerというものです。
Transformer誕生以前の自然言語処理の手法としては以下のものがありました。
SVM、解析木(NN以前):可変長データ入力不可、並び順未考慮
Word2Vec(NN):Skip-Gramによる低コスト学習
Seq2Seq(RNN):可変長データ入力可、入力履歴に基づく文脈の取扱い
ただ、Seq2SeqのようなRNNを用いた手法でさえ、最初の方に出現した情報がほとんど消えてしまったり、取り込む情報量に制限があったり、といったモデルの性質上のボトルネックがありました。
より応用的なAIを構築するには、このような言語理解や背景知識の欠如が足をひっぱりました。
そんな中で生まれたのがTransformerです。
TransformerはEncoderとDecoderに大きく分かれており、その中でさらに複数の層があります。
例えば、Attention層(Multi-Head Attention)では、文章内の単語を並列に入力することで学習時間を短縮でき、計算の高速化に寄与します。さらに単語間の照応関係を反映する役割も担います。
また、Potential Encoding層では、単語へ文章内での位置情報を埋めこみ、文脈に依存したベクトルへ変換します。
Transformerの特長を簡単にまとめると、従来の手法と比べて並列入力による計算の高速化で学習時間が短く、文脈情報を保持することで精度も高いということになります。

BERTとは
BERTは、Bidirectional Encoder Representations from Transformers の略で、Transformerを最初に採用した双方向型の事前学習モデルです。
2018年10月にGoogleの論文「BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding」で発表され、翻訳、文書分類、質問応答などのさまざまなタスクで当時の最高スコアを叩き出しました。
前述の通り、BERTは予測モデルではなく、事前学習モデルとなります。
そのため、出力層を追加するだけで分類や回帰といったタスクに対応することができます。
また、大量の教師なしデータから言語特性を双方向学習することで文脈把握を行い(事前学習)、その後に少量の教師ありデータからモデルのパラメータを微調整することで個々のタスクに最適化します(Fine-Tuning)。
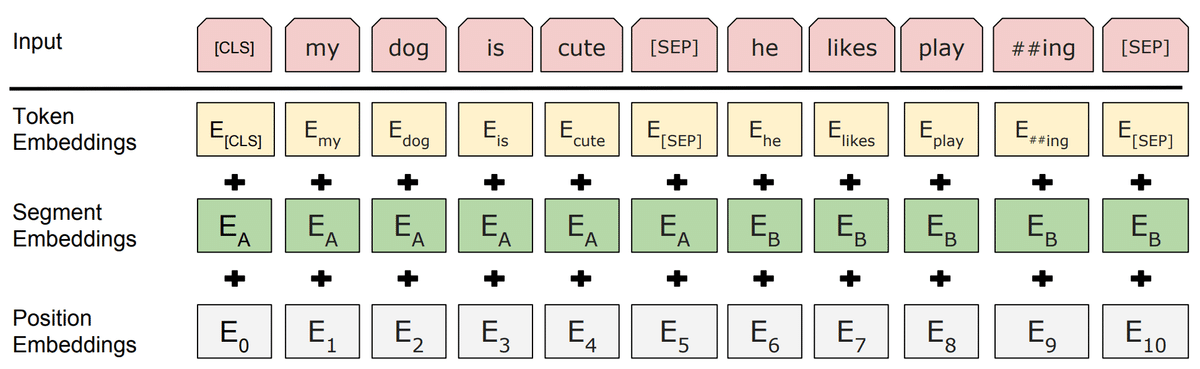
入力形式
BERTへ文章を入力するためには、2段階の変換を加える必要があります。
まずは単一の文章や文章ペアをトークン列にするトークン化を行います。
トークン化を行う際、文頭を示す[CLS]や文末を示す[SEP]といった特殊トークンも追加します。

トークン化を行った後、トークン、文章タイプ、文章中の位置に応じたベクトルに変換し、これらを足し合わせます。
これをベクトル化といい、ベクトル化されたトークンを単語ベクトルと呼びます。
事前学習
前述しましたが、BERTではまず、大量の教師なし(ラベルなし)データから汎用的な言語パターンを学習させます。
これを事前学習(Pre-Training)と呼び、以下の2種類の手法があります。
◯ Masked Language Model(MLM)
入力トークンのうち、[CLS]や[SEP]を除いた15 %を以下のように置き換え、元のトークンが何であったかを予測します。
80 %:特殊トークン[MASK]に置換
10 %:ランダムな語彙に置換
10 %:そのまま(Fine-Tuning時は[MASK]が発生しないため、その差異を緩和)
◯ Next Sentence Prediction
2文が与えられるタスクでそれぞれの関連性を学習させます。
[CLS]に対応するBERTの出力を分類器に入力し、出力から連続性(連続/不連続)を予測します。
Fine-Tuning
Fine-Tuningでは、少量の教師あり(ラベル付き)データからタスクに特化した学習を実施します。
事前学習済のBERTモデルをタスク内容に応じた分類器に接続し、ラベル付きデータを入力することでBERTと分類器の両方のパラメータを学習させます(BERTパラメータを固定して学習させるfeature basedという手法もあります)。
事前学習で得たパラメータをBERTの初期値とするため、少量のデータによるパラメータの微調整のみで高性能なモデルを得ることができます。
論文紹介
以上の前提知識を踏まえた上で、論文紹介に入ります。
目的と背景
時系列表データに適用できる新しいDeep Learning(DL)手法を提案するのが、この論文の目的です。
医療や金融などの産業で膨大な表データが存在しているにもかかわらず、個人情報や機密情報の保護といった理由でデータ分析に制限かかっているなどの問題がありました。
また、静的表データと比べて、時系列表データに関するMachine LearningやDeep Learningの研究が盛んに行われてこなかったことなどもあり、それらのデータを有効に活用するための手法を研究するに至りました。
概要
論文では以下を紹介しているのですが、今回はTabBERTによるクレジットカードの不正利用検知のみを紹介します。
現実に近い時系列表データの生成モデルであるTabGPTの紹介
時系列表データの学習モデルであるTabBERTの紹介
TabBERTの学習法の紹介(例:クレジットカード、大気汚染データ)
学習済TabBERTの活用法と結果の紹介(不正検知、汚染予測)
TabBERT(Hierarchical Tabular BERT)
TabBERTは多変量表データの学習にBERTを応用したモデルです。
以下の図のように2段階でEncodeを行う(Hierarchical)ことで、表データのフィールド(カラム)間と行間の照応関係を反映させます。

データ前処理
TabBERTに表データを読み込ませるにあたり、学習に必要なカラム(フィールド)を抽出したり、連続値をカテゴリ化する必要があります。
不正利用の有無を判別するIs Fraud?フィールドのデータが今回のラベルとなるのですが、入力フィールドは予測結果に影響しそうなものを選びます。
また、Year, Month, Day, Timeはフィールド単体のデータが予測結果には影響しないと考えられるため、Timestampとしてまとめています。
フィールド数が多い方が予測精度はあがるのですが、このように、結果に影響しなさそうなフィールドを増やしてもあまり意味がありません。

事前学習
事前学習には、2400万トランザクション(2万ユーザ)のデータを使用し、1ユーザ(User)につきトランザクションを5行ずつ(Stride)ずらしながら、10行ずつまとめたデータをサンプルとして使用します(スライディングウィンドウ)。
インデックスに対して、連結(平坦化)しないデータを使用します。
このとき、不正利用検知タスクへの影響を防ぐため、ラベルのフィールドIs Fraud?を除去します。
以上の条件でMLMを行います(CrossEntropyLossで精度評価)。
※Next Sentence Predictionは行いません。

Fine-Tuning
Fine-Tuning用の入力データとしては、1ユーザのデータを10行ずつ連結(マージ)したものを用い、それに対して不正ラベルを付与(アノテーション)します。
このようにすることで、1ユーザの行動履歴(今回のケースでは10回のトランザクション)を元にパラメータを調整することができます。
また、不正ラベルIs Fraud? = 1のデータが約3万/240万と少ないのですが、不正利用検知のようなケースでは、不正データは正データに比べると極端に数が少なくなります。
このような不均衡データでそのまま予測モデルをつくると、すべて正と判定するモデルができあがってしまいます。
そのため、少ないデータを増やすために、アップサンプリングを行います。
アップサンプリングの詳細について論文に記載はありませんでしたが、調べたところ、不正ラベルのデータを単純に数倍して増やすなどの方法があるようでした。
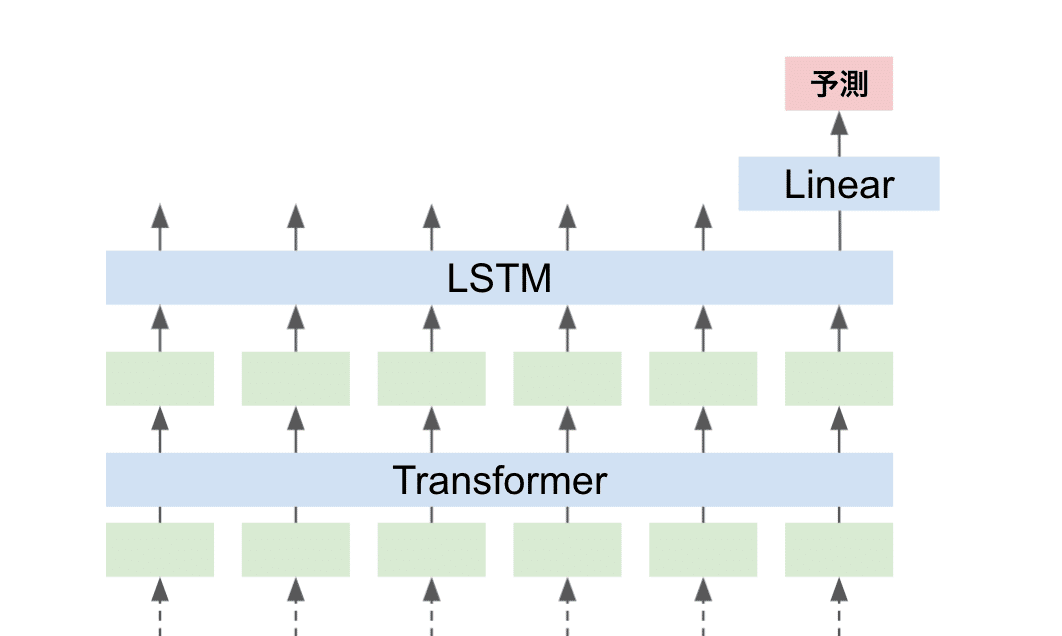
また、検知(分類)タスクに対応するために、TabBERTのあとにLinear層を接続するのですが、精度比較のためにTabBERTとLinear層の間にMLP層やLSTM層を挟んだパターン、TabBERTを除いてMLP層やLSTM層だけのパターンでそれぞれパラメータを微調整します(計4パターン)。
以下がTabBERT-LSTM-Linearのパターンの参考図となります。
不正検知(分類)タスク
タスクは48万テストデータで実施します。
このとき、F1スコア(適合率と再現率の調和平均)で4パターンの精度を評価します。
MLP/LSTM単体とTabBERTありのスコアを比較すると、どちらもTabBERTありの方が高いことがわかります。

さいごに
論文に事前学習までのコードが付属していたので、現在触ってみています。
Fine-Tuningと分類タスクのコードも書いているので、結果がでたらこちらについても記事を書きます。
また、ジェイタマズではエンジニアを募集しています。
会社やサービスに興味がある!という方がいらっしゃいましたら、ぜひ気軽にカジュアル面談しましょう!
この記事が気に入ったらサポートをしてみませんか?