
Cloud Composer の辛さと、それに負けない開発フローの構築 ~Composer はなぜ辛い?編~

※本稿はテックブログからの転載です。
TL;DR
もしあなたのチームがデータ基盤を構築するとして
・開発人数が少人数
・データパイプライン開発が非流動的
・(資金は潤沢)
でないのなら、cloud composer を使うと簡単にコストが下がるとは思わない方がいい。
自分達で直接 Airflow を立てて管理した方が、まだいいのかもしれない…
こんにちは。JDSCエンジニアリングメンバーの秋山です。
私は現在、データ基盤開発(MLOps含む)チームに在籍しており、 Cloud Composer を用いて、データパイプライン開発を行っております。
この Cloud Composer とは、 Apache Airflow という、 DAG を描画して ジョブを管理するワークフローエンジンをマネージドとして提供されているサービスで、GUI上でとても簡単に環境を構築し、運用も行えます!
果たして、そうでしょうか。

〈#DataEngineeringStudy ではこんな話題で持ちきりでした(自分は参加できなかったので、察するしかありませんが...)〉
辛いのです。全くもって。私も3ヶ月ほど使ってきましたがいつもcloud composer に泣かされっぱなしでした。
そこで今回は、この巷でよく聞く「なぜ cloud composer が辛いのか」を言語化し、「その辛さに負けない開発フロー」を提示いたします。
(マネージドサービスとしての)Cloud Composer の辛さ
先に弁明すると、私は Airflow が 辛いとは思っておりません。
同じ python のワークフローエンジン である luigi などと比べると
DAG の実装のしやすさ、可視化や実行の UX においてはかなり優れていると感じます。
ではなぜ Cloud Composer になると辛くなるのでしょうか?
以下の5つが私の中で挙げられました。
・コストが辛い
・起動が辛い
・リソース管理が辛い
・バージョン把握が辛い
・設定がブロックされていて辛い
(上記、「そんなんだったらマネージドサービスなんて使うなよ!」と言われそうなリストではありますね…)
1:コストが辛い
下図を見てもわかるように、Cloud Composer はかなり巨大なアーキテクチャで構成されています。
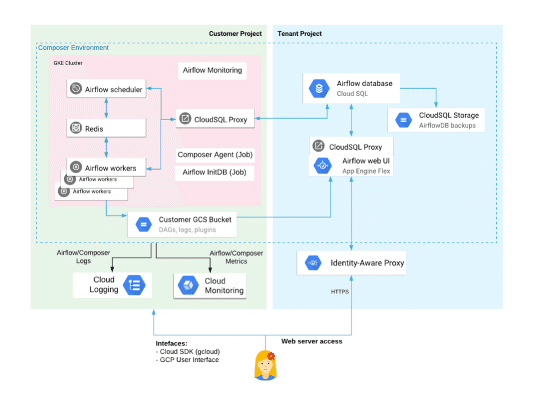
Cloud Composer をフル稼働させた場合、月数万〜10万弱の運用コストがかかるというのは、このアーキテクチャ内にある
・GKE(執筆時には料金が安くなるプリエンプティブルモードで構成することができませんでした)
・GAE
・CloudSQL
・CloudStorage
・Monitoring
といった様々なサービスのコストがかかるからなのです。
チームで開発するとなると、やはり個別の開発環境としての composer を人数分用意したくもありますが、それを実現するにはかなり資金が必要となるでしょう。
また、補足すると、我々のチームでは、
とあるように営業時間のみ稼働させてコスト低下を図っているのですが、実はこれ、下手したらバッドプラティクスになりかねないということがわかりました。(詳細は後述)
2: 起動が辛い
上記の巨大なアーキテクチャであるが故に、composer の起動には15〜40分ほど(PyPi パッケージやプラグインなど指定しない場合は15分程度、我々のチームで使用する構成では40分かかることもあります)かかってしまいます。
さらに、おそらく多くの方が最初につまづくかと思われますが、起動する際のログにはめぼしきものが全く吐かれません。

これは例えば、 途中で composer 内のどこかのサービスを立ち上げる際に権限不足エラーで落ちていたとしても、その旨が記載されたエラーは吐き出されず、ましてや即座に起動失敗として処理もされず、2〜3時間を経てようやく、 timeout エラーとして終了されます。辛すぎる。
3: リソース管理が辛い
この記事に載っていることが全てなのですが、worker となっている GKE のノードは auto scaling が有効になっておりません。
つまり composer 作成時に決めたノードで、適切にジョブの計算資源を管理し、他 Pod の兼ね合いも考慮するなら、kubernetes_pod_operator を用いてリミットを設定した上でジョブを実行させるようにしなければなりません。
上の記事では、composer を起動させたのち、 GKEノードを直接いじることによってスケールを果たしているのですが、そこまでして cloud composer を使う理由は一体なんなのだろうかと思いました。
対処法をあげるとするなら、総じて実際の加工処理はなるべくなら外だししましょうということです。
例えば、我々のチームではデータ加工の実体をなるべくBigQueryでまかなっており、それ以外で重そうな処理については Cloud Build で行なっていたりもします。
4:バージョンの把握が辛い
先述した、cloud composer を営業時間のみ稼働させ、1日ごとで再起動するのがバッドプラクティスにつながるという理由がこれにあたります。
cloud composer では以下のバージョンをサポートしており、およそ週1の早いペースでバージョンが更新されております。
ということは、今まで使っていたバージョンがサポート対象外となる頻度も高く、ある日突然、指定したバージョンでは起動しなくなった、といったケースにも遭遇しました。

〈GUI上では4つしかバージョンの選択ができないようになっている。辛い。〉
さらに、airflow のバージョン更新の頻度も高いため、最新のバージョンを常に起動させるというやり方を取ったとしても、DAGを実行できないかもしれないというリスクを消すことができません。
これに関しては、一度 composer を稼働したらあまり止めないようにする運用方法をとるしかないでしょう。(いざ、再起動させる機会があるとしたら、リリースノートは必ず確認しておいた方が良いですね。)
ちなみに、 GUI 上で PyPi パッケージの更新を行う際、裏側では Cloud Build が動いて更新をかけております。パッケージ間のバージョン不整合性エラーなどは頻発して起こりえますが、そのエラーがコンソール上で反映されるのはかなり時間がかかりますので、ここをチェックすると良いでしょう。

5: 設定がブロックされていて辛い
最後に細かな部分ですが Composer では 以下のように Airflow の設定がいくつかブロックされております。
上記では、worker が celery_executor を使うように固定されてたり、logの出力先が固定されていたりします。
例えば worker をデフォルトでタスク毎に pod を立てて実行するような kubernetes_executor にしたり(上述した kubernetes_pod_operator を逐一使うようにしましょう)、比較的ジョブキューの速度が速いとされる dask_executor を使用することができないので注意しましょう。
ちなみに個人的にハマったのは
core-enable_xcom_pickling
が False となっている点で、これが有効であれば DAG やタスク間での変数の受け渡しに用いる Xcom と呼ばれる変数が pickle 化されるため、 python の組み込み型のまま受けわたせるというメリットがありましたが、 RCE 脆弱性により Airflow2.0 以降は廃止される模様なのでやむなしです。
まとめ
以上を踏まえて、このサービスが本格的に稼働させたい場合、ワークする状況とはなんでしょうか。それは、
DAGの開発者が1〜2人といった極めて小規模で、ある程度開発も fix しており、運用担当者が非エンジニア等である場合に
効果を発揮するような気がします。
他開発者達は一体どうやってこの composer を運用しているのか調べてみたところ、こういった事例もありますが、
「ただ、一度できてしまうとAirflowなどに移行するモチベーションが保てなくなるので用法・用量を守って利用していきたいところです…」
と、書いてあるとおり、そもそもこのケースはAirflow抜きでもワークしてしまうような気がしますね...。
そして、貴方のチームが上で挙げたようなワークする条件に合致しない、けれどデータパイプラインを DAG として管理していきたい、といった場合には結局、
「一旦、cloud composer ではなく、Aiflow そのもので開発/運用していく」
のが一番いいのではないかな、と思います。
具体的には、
・ローカルで動く Airflow コンテナ(local_executor)を用いて個別開発
・各個人の DAG がマージされた検証環境には別途 GKE などの インスタンスを必要な分だけ用意し、上述の Airflow のコンテナをデプロイして結合検証
というパターンが自然なのではないかと。
次回はそんな、docker コンテナを使ってローカルで GCP へアクセスできる Airflow の導入の仕方を紹介します。
採用やってます!We’re Hiring!
JDSC社内には各ロールが揃っていますので、他のSIerや自社開発している企業とはレベルが違ったスピード開発が可能になっています。(もちろん、データエンジニアの方も積極的に募集しています)
そういう開発に興味があるエンジニアを絶賛募集中です!
この記事が気に入ったらサポートをしてみませんか?