
Second-order Optimization for Large-scale Deep Learning

邦訳:大規模深層学習のための二次最適化
大沢和樹
(スイス連邦工科大学チューリッヒ校(ETH Zürich)ポスドク研究員)
------------------ keyword ------------------
深層学習
スパコン
二次最適化
----------------------------------------------
【背景】大規模データ・ニューラルネットワークを用いた深層学習の需要の高まり
【問題】膨大な学習時間の削減
【貢献】スパコンと二次最適化手法を用いた学習の高速化
深層ニューラルネットワーク(DNN)を用いた機械学習手法である深層学習の研究が近年盛んに行われている.DNNが画像認識や自然言語処理の認識ベンチマークにおいて古典的な機械学習手法を凌駕したことを皮切りに,自動運転・機械翻訳・医療などの実社会における問題から,新しい天体の発見・天気予報・タンパク質の構造解析などの科学技術計算に至るまで,幅広い分野に渡って急速に応用が進められている.
DNNの応用および研究を支える1つの重要な柱として,高性能ハードウェア(例:GPU,TPU)やスーパコンピュータ(以下,スパコン)を駆使した高性能計算技術がある.高性能計算技術による学習の高速化が学習データ・ニューラルネットワークの大規模化を実現し,近年の深層学習の発展に大きく貢献した.その延長として,膨大なデータ数(数百万〜数千万)と膨大なパラメータ数(数千万〜数億)のDNNを要する「大規模深層学習」がより高い性能を発揮することが経験的に知られており,DNNによる予測性能の最高記録を今なお更新し続けている.しかし,こうした優れた性能を発揮する DNNの発見のためには,DNNの構造と学習方法についての膨大な試行錯誤が必要不可欠であり,大規模深層学習においてはその膨大な学習時間の削減が重要な課題となっている.
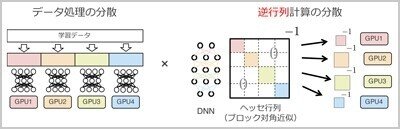
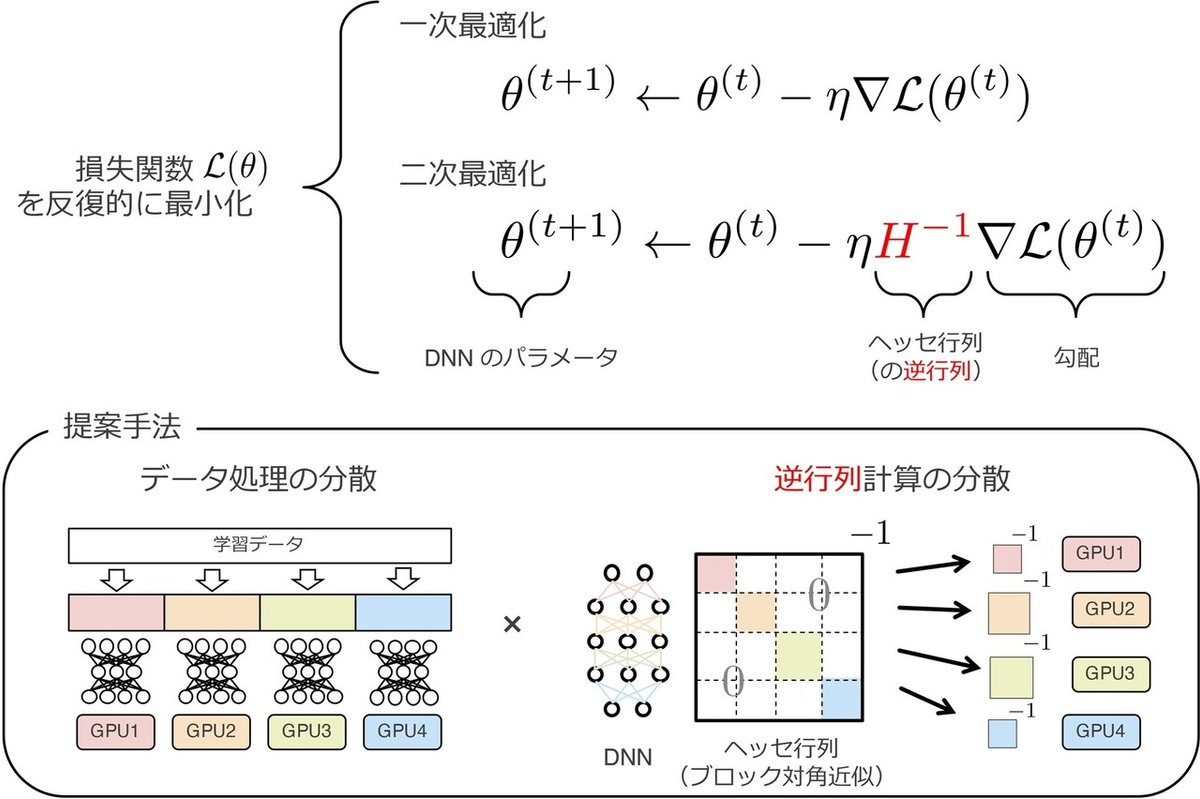
深層学習においては,DNNによる予測とデータとの誤差を定量化する損失関数を定義し,この損失関数をその勾配(一階微分の集まり)を用いて反復的に最小化する「一次最適化手法」が一般的である.これに対し,関数のヘッセ行列(二階微分の集まり)を用いた「二次最適化手法」は,関数の形状をより正確に捉えるため,より少ない反復数で損失関数を最小化することが期待される.一方で,膨大なパラメータ数(N)を持つDNNについて巨大なヘッセ行列(N×N行列)を計算することは計算時間・メモリの制約上現実的ではない.その上,ヘッセ行列の逆行列計算に伴う膨大な計算時間を必要とするため,深層学習における二次最適化手法の応用は限られていた.
本研究では,近年発達した効率的な二次最適化近似手法とスパコンを駆使した分散並列計算を組み合わせることで,大規模深層学習におけるDNN学習の高速化の実現を目指した.本研究では,(近似された)ヘッセ行列及びその逆行列の計算をスパコン上の複数の計算機(数百〜数千GPU)に分担させる大規模分散並列計算手法を提案し,大規模画像データセット(1000クラス・128万画像)の分類タスクにおける大規模DNN(2千万パラメータ)の学習の高速化を実現した.同タスクの学習を同じく大規模計算機で実現している既存研究ではいずれも単純な一次最適化手法が用いられてきたのに対し,本研究では二次最適化手法を採用し高速な学習時間を達成できることを初めて実験的に示した.この研究成果は,今後の深層学習における学習手法の研究に向けて大きなインパクトを持つものと考えている.
(2021年5月31日受付)
(2021年8月15日note公開)
ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー
取得年月日:2021年3月
学位種別:博士(工学)
大学:東京工業大学
ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー ー
推薦文:(ハイパフォーマンスコンピューティング研究会)
深層学習を分散並列化する場合,二次最適化に伴う行列計算のオーバーヘッドが並列処理によって大幅に低減できる.本論文では,これを活かして2次最適化や変分推論に用いられるフィッシャー情報行列のクロネッカー因子分解の分散並列処理を数千GPU規模で行い,大幅な性能向上を実現した.
大沢和樹
研究生活:私は高性能計算を専門とする東工大・横田理央研究室に第一期生として入研し,修士・博士課程の合計5年間所属しました.当時から大変注目が集まっていた深層学習を研究テーマとして選び,「高性能計算で深層学習を高速化する」という漠然とした目標を掲げて研究を始めました.研究室の先輩もいなければ,研究の知見もないゼロからのスタートだったため,修士の2年間は何をしてよいのかも分からず,満足のいく研究成果も出せない苦しい状況が続いていました.それでも論文サーベイを続けることで,高性能計算が深層学習において二次最適化のメリットを引き出す可能性があることを発見しました.博士課程で取り組んだ「大規模深層学習のための二次最適化」の研究は,共同研究者・研究室メンバの助けもあり,機械学習分野トップの国際会議・ジャーナル(CVPR ,NeurIPS,KDD,TPAMI)に採択されました.国際的にインパクトのある研究ができたこと,そしてその方針を自ら見出せたことは大変大きな自信となりました.
5年間のご指導と国内外の数多くのチャレンジの機会を与えていただいた横田理央准教授に心よりお礼申し上げます.