
WebSphere の運用を (少しずつ) 自動化して楽をするための WebSphere Automation 入門 (1)

システム運用って運用そのものが目的になることはたぶんなくって、別に目的というか本来やりたいことがあっての運用なので、正直なところ「運用が大好き」という人にはあまりお目にかかったことがない気がします。
一方、「運用に関わる技術が大好き」な人というのは筆者の身の回りにもいて、監視愛の強めなお姉さんとか、運用スクリプトの美しさで右に出る者を見たことがないおじさんとか、それぞれ得意分野を持ったスペシャリストが日々、如何にしてシステムの安定稼働を維持しトラブルを未然に防ぐかに心血を注いでいます…。
監視運用が回りそうにない例
IBM の WebSphere Application Server (以下 WAS) は発表・販売開始から20年の時を超えて今なお進化し続け使われ続けている伝説の (言い過ぎ) Java ベース Web アプリケーション・サーバーです。
アプリケーション・サーバーの運用項目はいろいろありますが、その一つに「メモリーリーク (GC ログ) 監視」があります。
リソースの close() を書き忘れたり、サイズを想像せずに巨大オブジェクトを new していたりといったバグに類するもの、あるいは業務量やデータ量が開発時の想定をいつの間にか上回ってしまったりと、ガーベージ・コレクターを持つ処理系であってもメモリーリークと無縁ではいられません (そもそも GC 対象にならないオブジェクトは GC されないし)。
メモリーリークから Java ヒープ圧迫が引き起こされるとどうなるかというと、GC の頻発や所要時間の増大によってアプリケーションの応答が遅くなったり、ひいては応答がなくなったりします。つまり、運用担当者が問題に気づく前に、ユーザー部門やお客様が影響を受けてしまう可能性が高くなります。
このような事態を未然に防ぐためによくあるメモリーリーク監視運用として、当月 1ヶ月分の GC ログを HeapAnalyzer に食わせて最大や平均の Java ヒープ使用率やその推移をまとめて Excel シートで報告、といったケースをときおり目にします。この方法は WAS インスタンスが両手で数えられるくらいまでは何とか機能すると思いますが、Kubernetes や OpenShift といったコンテナ・オーケストレーション環境で WebSphere Liberty を使ってマイクロサービス実装するので 1サービス / 1インスタンス / 1コンテナ でよろしく、などとなった場合に、規模によってはこの運用が破綻するのは火を見るより明らかでしょう。もちろん、コンテナ環境でない場合であっても WAS インスタンス数の規模によって同様のことが起こりそうです。
WebSphere Automation とは
IBM WebSphere Automation for IBM Cloud Pak for Watson AIOps (長いので以下 WebSphere Automation) は WAS の運用を (少しずつ) 自動化し、できるだけ手をかけずに、つまり WAS の運用エンジニアに楽をしていただきつつ 安定運用を目指すしくみです。
執筆日現在の最新バージョンである 1.3 では、上で挙げたメモリーリークの検出・資料収集 / 分析と、WAS インスタンスごとの Fix レベル & 脆弱性管理の大きく2つの機能を持っています。
この記事では、1つめのメモリーリーク監視について紹介します。Fix レベル & 脆弱性監視については別の記事にしようと思います。
WebSphere Automation によるメモリーリーク検出・資料収集 / 分析
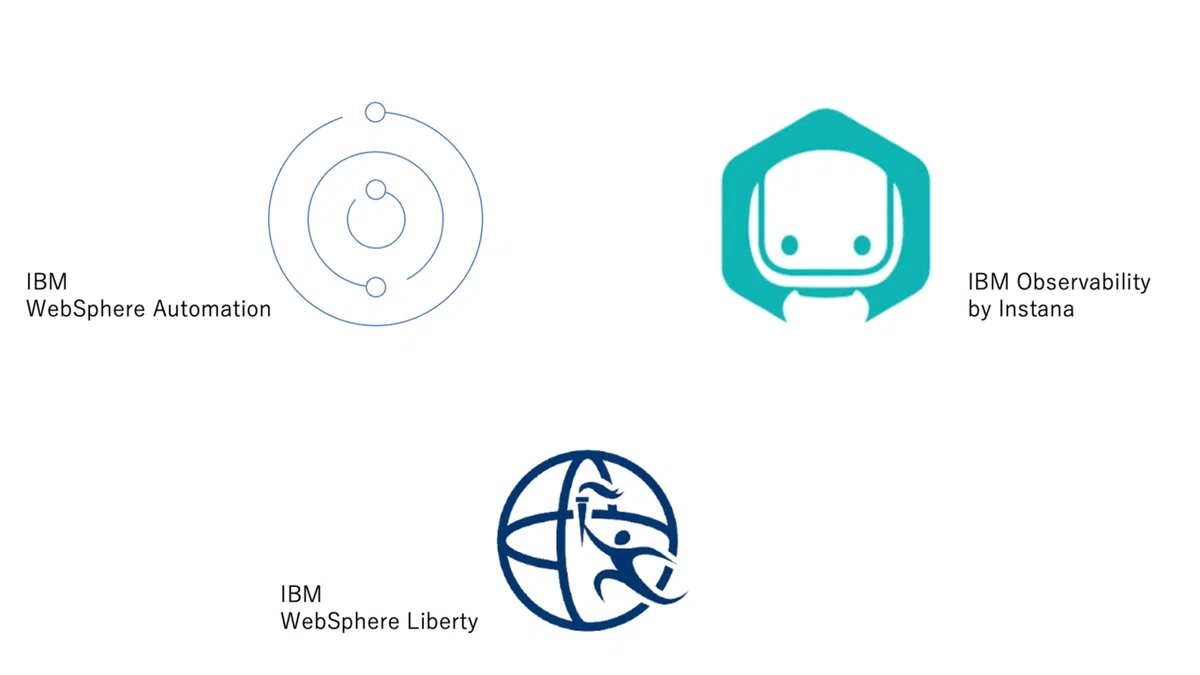
WebSphere Automation によるメモリーリーク検出・資料収集 / 分析は、IBM Observability by Instana (以下 Instana) との連携が必要になります。
WAS (図では WebSphere Liberty) を Instana の監視下に置き、メモリーリークを検出すると WebSphere Automation に通知するように構成します。
通知を受けた WebSphere Automation は対象の WAS インスタンスから資料 (ヒープダンプ) を収集し、解析を実施します。解析の結果として、Java ヒープを圧迫しているオブジェクトを探し出して教えてくれます。
この結果をアプリケーション開発者と共有して、アプリケーション改修の参考にしてもらうことができます。
ポイントは、 このようにしてメモリーリーク検出・資料収集 / 分析までを自動的に、しかも多くの場合は数分程度 (注: メモリーリーク発生時の JVM の状態によっては長時間を要したり、資料収集ができないことがあります) で完了できることです。
もし筆者が管理している WAS 環境でメモリーリークが発生したらどうなるかを考えてみます。
メモリーリーク自動検出の仕組みがない場合、多くの場合は運用担当者が気づくよりも先に、ユーザー部門やお客様からの「応答が遅い」または「応答がない」との報告が第一報になると思います。
報告を受けてからアプリケーションを特定し、当該のアプリケーションが動作している WAS インスタンス群 (クラスター) を特定します。一般に、アプリケーション・サーバーは性能と耐障害性を目的に Active-Active の冗長化構成としますので、クラスター・メンバーのどのインスタンスでメモリーリークが発生したか、ログなどを頼りに特定します。
その後、資料 (ヒープダンプ) を収集し、HeapAnalyzer などのツールを使って内容を分析します。
環境の規模にもよりますが、日常的に管理していて詳細を知っている (つまり、トラブってから呼び出しを食らって、構成や管理者パスワードの確認から始めないといけないような状況ではない) 場合でも、ざっくり半日作業、場合によってはもっとかかる気がします。
一方、WebSphere Automation によるメモリーリーク検出・資料収集 / 分析を使用していれば、「応答が遅い」または「応答がない」となる前に未然に予兆を捉えてリソースの増強で備えることができそうですし、もし突発的なメモリーリーク が発生してしまった場合でも、問題に気づいた時には既に資料収集と分析が完了している、といった具合にできそうです。
また、問題発生まで至らない場合でも、メモリーリーク自動検出が頻発するようになったことを契機として、計画的なリソース増強に役立てることができそうです。
数多くの WAS インスタンスを抱えて困難を感じている運用担当のみなさま、WebSphere Automation で「楽をするための」第一歩を踏み出してみませんか?
当記事に少しでもご興味お持ちいただき、さらに詳しい情報をお知りになりたい場合は、ぜひ下記アンケートよりお気軽にお問い合わせください。
ご記入いただいた方には、貴社の今後のDX変革にお役立てできるIBM の最新情報をお届けします!
どうぞよろしくお願い申し上げます。フォロー&記事のシェアをしていただけますと幸いです。
この記事が気に入ったらサポートをしてみませんか?