
もう「データ分析」は聞き飽きた~仮説ドリブンの"真"の課題発見~

■ はじめに
こんにちは!Repro Growth Marketerの稲田宙人(@HirotoInada)です!
昨今「データ分析」という言葉がより頻繁に聞かれるようになりましたが、汎用的に使われすぎて本当の「データ分析」のプロセス・価値が形骸化しているように感じられます
今回はECアプリを例にとってデータ分析の各ステップをなぞっていき本物の「データ分析」を学んでいきましょう
1.それ本当に「データ分析」ですか?
冒頭から挑発的な見出しで恐縮ですが、あなたがやってるそれ本当に「データ分析」ですか?
そもそも「データ」・「分析」とはなにかと辞書を引いてみるとそれぞれ
データ:
①物事の推論の基礎となる事実。また、参考となる資料・情報
②コンピューターで、プログラムを使った処理の対象となる記号化・数字化された資料。
分析:
複雑な事柄を一つ一つの要素や成分に分けその構成などを明らかにすること
とあります
上記から考えると、データ分析というのは、事象を要因に分け、その要因仮説の検証を行い、事象との関係性・事象の発生原因を明らかにしていくプロセスを指すと言えます
ここで、よくあるなんちゃって分析を例に挙げましょう
あるECアプリにおいて前週比で売り上げが大きく低下した。
分析の結果、水曜日の売り上げがが突出して低下していることが週全体としての売り上げが低下した原因であることが判明した。
これは大分極端な例ではありますが、どんな要素・視点が欠落しているでしょうか?
ここで先ほどのデータ分析の定義に立ち返ってみると、「複雑な事柄を一つ一つの要素や成分に分けその構成などを明らかにすること」の要素に分けるプロセスが不十分であることがよくわかります
水曜日に売り上げが低下しているというのは原因ではなく、これもまた事象でしかないのです
本質的な課題が見えない故に、具体的な次のアクションに繋がりません
では、具体的にどのようなステップを踏めば本物の「データ分析」ができるのでしょうか?
2.データ分析のステップ
一口にデータ分析と言ってもその種類は多岐に渡りますが、そのどれもに共通するステップは大きく5つに分かれ、以下のように図示することができます
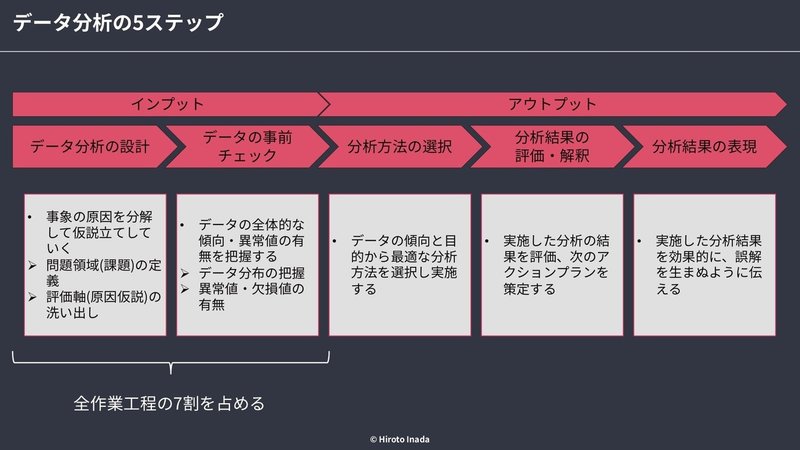
上図のようにデータ分析は大きく分けて計5ステップに分かれており、その中にはデータ分析の設計はもちろん、分析を元にしたアクションプランの策定まで入っている点に注目してください
実際の次の行動に繋がるような考察が得られないのであればそれは分析ができているとは言えません
また、もう一点注目して欲しいのが、データ分析作業の中でも準備段階に全体の7割の時間がかかっていることです
驚かれる方もいるかもしませんが、考えてみればこれは至極当然のことで、最初のインプットがゴミならば出てくるアウトプットもゴミにしかなりません。最初の段階で質の良い分析設計を行うことで最終的な考察とアクションプランも正当性のある真に価値のあるものになるのです。
それでは順番に各ステップを見ていきましょう。
3.データ分析の設計
まずは最初のステップ「データ分析の設計」です
前述の通り、ここのステップが一番時間がかかり、且つアウトプットの質に大きく依存する部分になります
よくあるミスとして、とりあえず闇雲に手当たり次第に数値を見ていくというのがありますが、このやり方では時間がかかる一方で質の高いアウトプットには繋がりにくいです
データ分析の設計は以下のような流れで実施していきます
データ分析設計の流れ
■ 問題領域(課題)の定義
・分析の対象となる事象は何かを明確に言語化する
↓
■ 評価軸(要因仮説)の洗い出し
・課題を要素に分解していき分解できない粒度まで落とし込む
・この段階ではあり得ない要因でも書き出していくのが重要
↓
■ 評価軸(要因仮説)のグルーピング
・洗い出した評価軸を外部要因・内部要因などの共通項でグルーピングする
↓
■ 分析優先度の決定
・グルーピングした評価軸をデータの入手の難易度(工数)と分析実施によるインパクトの2軸で優先度を決定する
上記を実施する上で有効的な手法をご紹介します
KPIツリー
一つ目の手法はKPIツリーです
先ほどのECアプリの例を例にとり、売上を構成する要素に分解していくと以下のように図示できます

上図のように分解できる粒度まで要素に落とし込んでいくことでボトルネックになっている部分はどこなのか、数値を見ていくべき部分はどこなのかというアテをつけられるだけでなく、課題に関係している要素を可視化することができるようになります
KPIツリー作成のポイント
■ 測定可能・定量化できる指標をおく
・ツールの制約上測定できない指標や、定性的指標はボトルネック発見に繋がらないのでツリー上には設定しない
■ 四則演算で計算できるようにする
・難解な計算ではなく四則演算(+-÷×)で計算できるようにする
・四則演算で計算できない場合は分解が不十分
■ 分岐はできる限り2つまでにする
・前述の四則演算と同じように3以上の要素での計算ではなく2つの要素まで計算を落とし込むのが重要
なぜなぜ分析
もう一つの手法が「なぜなぜ分析」です
なぜなぜ分析とは事象に対して問いを繰り返していき最終的な課題を発見する手法です
先ほどのECアプリの例では以下のように問いを立てていくことが可能です

簡易的な問い立てではありますが、仮説と分析がセットになっており、一つ一つの仮説検証を順番に行い粒度を小さくしていっているのが分かるかと思います
なぜなぜ分析のポイント
■ 問いと分析がセットになるようにする
・問いに対しての実施する分析がセットになるようにします
・問いに対しての分析が不可能なのであればその後の問い自体が連続性を失うため問いとしては不適切
■ 問いの粒度は大から小へ
・問いは課題の上流(粒度大)から下流(粒度小)に一貫して流れるようにする
・そうすることで思考の飛躍や仮説の抜け漏れを防ぐことができる
4.データの事前チェック
続いて「データの事前チェック」のステップです
事前チェックなしにすぐにデータを触ると異常値や欠損値の影響で誤った結論にたどり着きかねません
まずは以下のポイントを抑えて事前のチェックを行い分析前の最終準備をしましょう
データの事前チェックのポイント
■ データのサイズ
・対象のサンプルサイズは十分なものか
・取得したデータの集計期間は課題に即したものになっているか
■ 欠損値・異常値はないか
・欠落している値はないか
・突出した値はないか
■ データの分布
・代表値はどこに分布しているか
・最頻値はどこに分布しているか
・データはどのように分布しているか
データの分布・傾向を把握する上ではヒストグラムや箱ひげ図での可視化や、代表値の算出が有効です
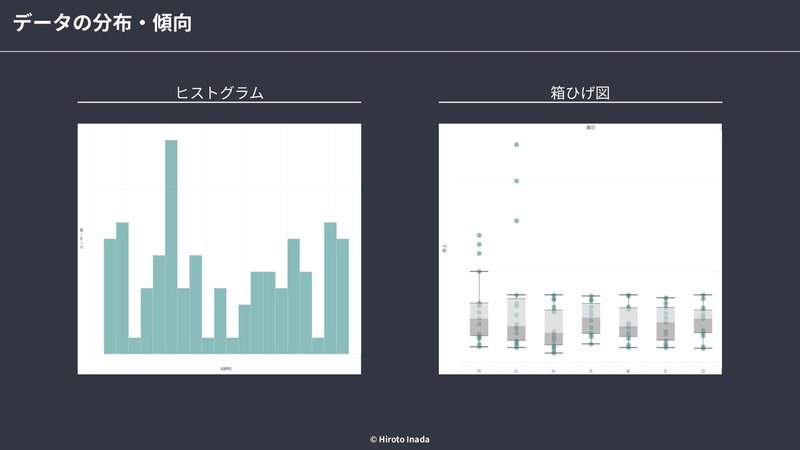
また、異常値や欠損値の影響でデータの偏りがある状態では結論も誤ったものになり得るので、データクレンジングの作業を行いデータ分析に適した形に整形する場合もあります
5.分析方法の選択
ここまでデータ分析の準備をしてきましたが、いよいよ実際の分析のステップに入ります
本noteでは個別具体的な分析手法ではなく、どのように分析作業を実施していくかの汎用的なプロセスにフォーカスしたいと思います
分析をする上では横の軸と縦の軸を意識するのが有効です
ECアプリにおけるCV(購入)までのユーザーフローを例にとります

ここでいう横の軸は時系列やフローなどの連続性のあるものを指します
縦の軸はユーザーを特定の要素でセグメントしていく条件を指します
基本的には上記の横×縦の2軸、もしくは横×縦×縦の3軸、場合によっては縦×縦の軸での分析を行うことが有効です

上図のようにまずは基本的なクロス集計を使いこなすだけでも、事象を構成する要素同士の関係性が明確になり、より詳細に課題の根本原因を見つけることが可能になります(個別具体的なシチュエーション別の分析方法に関してはまた別の機会に…)
6.分析結果の評価・解釈
分析作業が終わったら結果の評価とアクションプランを策定します
結果の読み取り方に関しては分析手法によって変わるため、本noteではアクションプラン作成方法にのみ言及します
本ステップでは次の行動が大きく2つに分岐します
1つ目は新たな分析が必要になるパターンです
この場合は単純にまた最初のステップである「データ分析の設計」から分析を実施していくプロセスになります
2つ目は実際の改善提案に落とし込むパターンです
改善提案の実施優先度は以下の軸を複数考慮していくことで策定が可能ですが、部分最適に陥らないように気をつけましょう
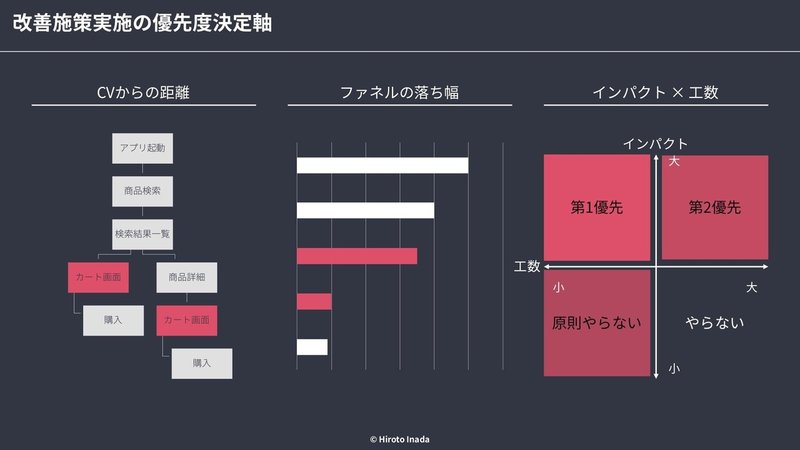
改善施策実施の優先度決定軸
■ CVからの距離の遠近
・ユーザーフローとしてCVに近い距離の課題からアプローチしていく
・概して部分最適になりがちなのでファネルの落ち幅も考慮する
■ CVファネルの落ち幅の大小
・CVまでのファネルを組んだ際の落ち幅が最も大きい部分からアプローチしていく
■ 想定インパクトと工数
・施策を実施する上での工数とインパクトのマトリクスで優先度を決定する
・第一優先:工数小×インパクト大
・第二優先:工数大×インパクト大(不可欠度は吟味する必要あり)
※工数小×インパクト小は原則優先度は下げる
7.分析結果の表現
いよいよ分析における最後のステップまできました
このステップでは分析結果を他の人に伝える前の最終確認を行います
確認するべき点は主に以下の3つの観点です
・データ解釈の観点
・ビジュアライズの観点
・言葉の伝え方の観点
データ解釈
分析したデータと結果に本当に正当性があるかを改めて確認します
以下の確認事項の中でも仮説検証バイアスと擬似相関は特に注意すべき点になります
データ解釈
■ サンプル数
・分析する上で十分なサンプル数は確保できているか
・サンプル数が小さすぎる場合同じ傾向が全体にも適用できるとはいえない場合もある
■ 分析・比較の条件
・分析・比較の対象データは比較したい要素以外は統一された条件であるか
・複数の変数を用いるとどの要素が影響を与えているのかが不明瞭になる
■ 仮説検証バイアス
・自らの仮説を立証するデータのみ集めていないか、仮説を棄却するデータを無視していないか
■ 因果関係
・原因と要因に真に連続性・因果関係はあるか
・原因と要因の間に別の変数は潜んでいないか
ビジュアライズ
ビジュアライズにおいては、結果を受け取る人に誤った印象や判断を下させてしまわないように気をつける必要性があります
ビジュアライズ
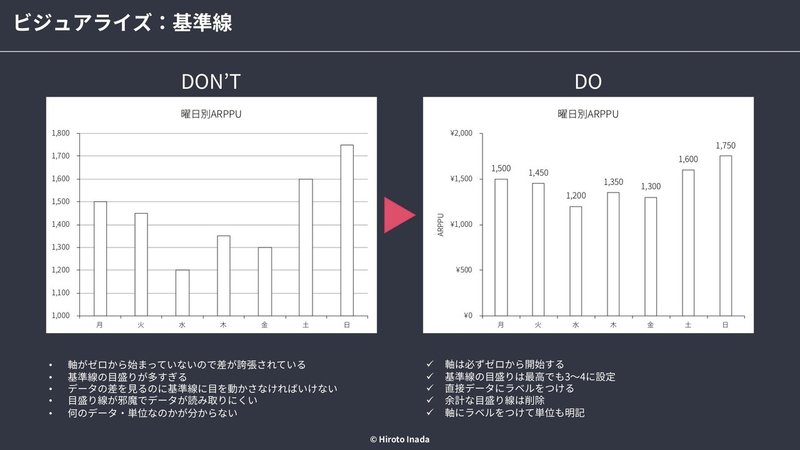
■ 基準線
・グラフの基準線は常にゼロにするべき
・差が誇張して表現されるため印象操作と受け取られかねない
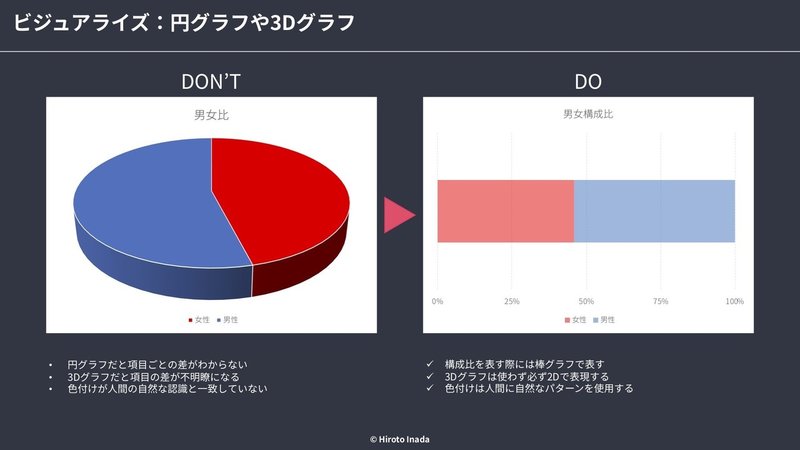
■ 円グラフや3Dグラフ
・人間の目で容易に比較ができないグラフは使用しない
・構成比を表したい場合は積み上げ棒グラフや並列棒グラフで十分
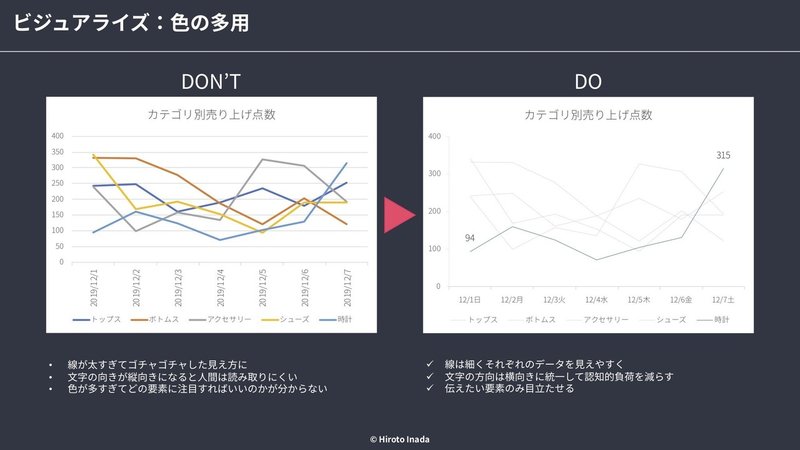
■ 色の多用
・重要なポイント、伝えるべき要素のみに色付け
・基本はモノクロで十分
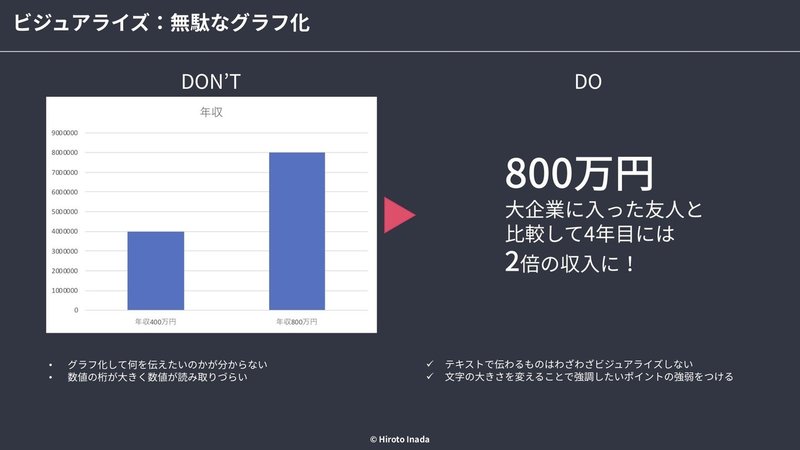
■ 無駄なグラフ化
・本当にグラフ化する必要性があるかを意識する
・単純なテキスト記述で十分な場合がある
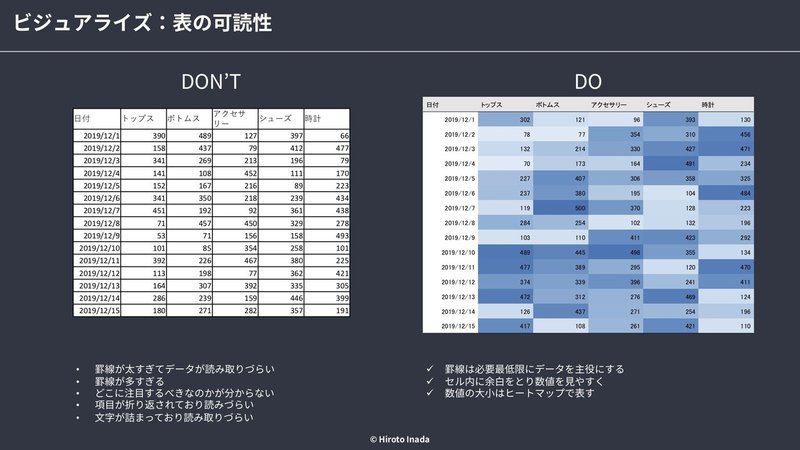
■ 表の可読性
・罫線は脇役、データが主役である
→必要最低限の罫線のみ記載する
・重要なポイントは目立っているか
→表は読ませるものであることを意識する
→数値の大小の表現はヒートマップがおすすめ
上記のデータビジュアリゼーションの注意点はほんの一部にすぎませんが、もっと詳しく知りたい方は以下の本がオススメです
言葉の伝え方
結果を伝える際に、必要な情報が不足していたり、伝える順番や言葉を間違えると受取手が誤った解釈をする可能性もあります
言葉の伝え方
■ 出典の表記
・データの集計元を必ず明記すること
■ クレンジングの基準
・クレンジング有無と基準を明記すること
・恣意的なデータ操作と誤解を与える可能性がある
■ アンカリング
・余分な情報が追加されていないか
・意図的に差があるような印象操作をしていないか
■ プライミング
・先にポジティブな内容を提示して後半のネガティブな内容が霞んでいないか
・伝える順番を逆にして伝わる印象が変わらないか
■ フレーミング
・ネガティブな事象をポジティブな表現に無理やり置き換えていないか
・同じ事象をポジティブ・ネガティブで置き換えて印象は変わらないか
■ 最後に
以上がデータ分析の全ステップでした
かなり概念的な内容が多くはなりましたが、個別具体的な分析手法を実践する際にも必須な工程になりますので是非マスターして貰えれば嬉しいです
次回以降はより具体的なシチュエーション・課題ベースでの分析方法にフォーカスしてお伝えしていければと思います
みなさんのサービス改善の少しでも力になれれば!
最後までご覧いただきありがとうございました
この記事が気に入ったらサポートをしてみませんか?