
[書評] リーダブルコード ~より良いコードを書くためのシンプルで実践的なテクニック

Theory in practice
「リーダブルコード」は、良いコードを書くためのシンプルで実践的なテクニックを提供している一冊です。この本では、コードを再構成し、読みやすくするための方法が解説されています。
変数の選択からループとロジック、制御フローや論理式の構築、そしてテストの書き方に関するアドバイスが豊富に盛り込まれています。「優れたコードとは読みやすいコードである」という考えを基本に、コードの読みやすさを追求する実践的な技法が説明されています。
理論を実践に結びつける「Theory in practice」のアプローチにより、読み手の理解を助けるコーディング能力が身につきます。読みやすいコードを書くための必読書だと言えます。2112円の価値は十分にある良書です。
購入先: O'Reilly Japan - リーダブルコード
原書: The Art of Readable Code
著者名: Dustin Boswell、Trevor Foucher 著、角 征典 訳
出版日: 2012年06月
価格: Ebook 2,112円

1章 理解しやすいコード
ソースコードの読みやすさの重要性と、読みやすいコードを書くための基本概念について解説しています。

1.1 「優れた」コードって何?
コードの読みやすさが最も重要な基準である。
読みやすいコードは、他の人が短時間で理解できるコードである。
読みやすさは、優れた設計やパフォーマンスなどと競合しない。むしろ、読みやすさを向上させることで、それらも改善される。
1.2 読みやすさの基本定理
コードは、他の人が最短時間で理解できるように記述する必要がある。
「他の人」には、コードを理解して変更・追加・バグ修正ができるレベルのことを指す。
# 読みにくい例
values = []
for x in range(10):
values.append(x*2)
# 読みやすい例
values = [x*2 for x in range(10)]2つの例は同じ処理を行っていますが、リスト内包表記を使った2つ目の例の方が1つ目に比べて短く、簡潔で理解しやすいコードになっています。
1.3 小さなことは絶対にいいこと?
コード量が少ないことは必ずしも読みやすさにつながるとは限らない。
読み手の理解に要する時間をできるだけ短くすることが目標である。
# 読みにくい例
x = (a-b) if a > b else (b-a)
# 読みやすい例
if a > b:
x = a - b
else:
x = b - a1つ目は1行で表現されていますが、条件式が長くなり読みにくくなっています。2つ目は若干長くなりますが、条件分岐を明示的に記述することで読みやすさが向上しています。
読みやすいコードの重要性と基本概念が説明されています。他の人が短時間で理解できるようなコードを心がけることが大切です。簡潔さだけを追求するのではなく、読み手の理解の容易さを考慮する必要があります。
2章 名前に情報を詰め込む
変数や関数などの名前付けについて、読み手にとって情報量が多く理解しやすい名前の付け方を解説しています。

2.1 明確な単語を選ぶ
名前にはできるだけ具体的で情報量の多い単語を使う。
抽象的な単語では情報が十分に伝わらない。
# 抽象的な名前
def get_data():
# データ取得処理
# 具体的な名前
def fetch_user_profile_from_database():
# ユーザープロファイル取得処理2つ目の例の方が関数の目的が明確に伝わります。
2.2 tmpやretvalなどの汎用的な名前を避ける
tmpやretvalといった汎用的な名前は情報量が少ない。
変数の目的を表現した名前をつける。
# 汎用的な名前
retval = compute()
# 目的を表した名前
total_size = compute_file_size()2つ目の例の方が、変数の目的が明確になり読みやすくなります。
名前付けの考え方と名前から多くの情報を読み取れるようにするテクニックが解説されています。適切な名前はコードの理解を助ける重要な要素です。
# 古典的な例
if (right < left):
tmp = right
right = left
left = tmp
# 良い例
if (lower_bound < upper_bound):
lower = upper_bound
upper_bound = lower_bound
lower_bound = lowerこの古典的な変数入れ替えの例でも、tmpという汎用的な名前を避け、lower_boundやupper_boundのような具体的な名前を使うことで、コードの意味が明確になります。
汎用的な名前を避けることは、初学者にとって大切な Clean Code の概念です。
# 悪い例
for i in range(clubs):
for j in range(clubs[i].members):
for k in range(users):
if clubs[i].members[k] == users[j]:
print(f"user[{j}] is in club[{i}]")
# 良い例
for club_index in range(clubs):
for member_index in range(clubs[club_index].members):
for user_index in range(users):
if clubs[club_index].members[member_index] == users[user_index]:
print(f"user[{user_index}] is in club[{club_index}]")このように、ループ内のイテレータにも意味のある名前を付けることで、コードが読みやすくなります。
汎用的な名前は避け、具体的な名前を付けることが大切です。これはClean Codeの基本中の基本です。
2.3 抽象的な名前よりも具体的な名前を使う
抽象的な名前ではなく、具体的で詳細な名前を使う。
名前からその変数や関数が何をするのかがイメージできることが重要。
# 抽象的な名前
def process_data():
# データ処理
# 具体的な名前
def sanitize_user_input():
# ユーザ入力のサニタイズ2つ目の例の方が具体的で、関数の目的が明確に伝わります。
2.4 名前に情報を追加する
変数名などに、その値の単位や属性など重要な情報を追加する。
# 時間の単位を明示
timeout_secs = 10
# 安全でない変数に属性を追加
unsafe_user_input = input
safe_user_input = sanitize(unsafe_user_input)単位や属性を追加することで、変数の意味が明確になります。
名前からできるだけ多くの情報が読み取れるよう、具体的な名前を使い、追加情報を含めることが大切です。
2.5 名前の長さを決める
変数のスコープが小さい場合は短い名前でも良い。
変数のスコープが大きい場合は、長い説明的な名前をつける。
# スコープが小さい変数
for i in range(10):
print(i)
# スコープが大きい変数
maximum_file_upload_size_in_bytes = 1024 * 1024 * 100スコープに応じて名前の長さを調整することが大切です。
2.6 名前のフォーマットで情報を伝える
アンダースコアや大文字小文字を使って、名前からも情報を伝える。
# クラス名は大文字始まり
class User:
pass
# 変数名は小文字始まり
user_id = 1名前のフォーマットを統一することで、追加の情報を伝えることができます。
名前付けの様々なテクニックが解説されています。適切な名前付けはコード理解に大きく影響します。名前の情報量を増やす工夫が必要です。
2.7 まとめ
明確な単語を選ぶ
汎用的な名前は避ける
具体的な名前を使う
追加情報を含める
スコープに応じた名前長を選択する
一貫したフォーマットを利用する
名前付けの様々なテクニックが紹介されました。
情報量の多い具体的な名前を選ぶ
名前から変数の特徴がわかるように、単位や属性を追加する
スコープに応じて名前長を調整する
一貫したフォーマットを利用する
などが、読みやすい名前付けのポイントです。
適切な名前付けはコードの理解に大きな影響を与えます。名前に込める情報量を増やす工夫が重要です。
3章 誤解されない名前
名前が誤解を招かないようにするテクニックについて解説しています。

3.1 例:filter()
filter という名前は「選択する」か「除外する」かあいまい。
目的に応じて select() や exclude() などの明確な名前を使う。
# あいまいな名前
filtered_data = filter(data, condition)
# 明確な名前
selected_data = select(data, condition)
excluded_data = exclude(data, condition)filter では目的が不明確なので、select や exclude のような明確な名前を使ったほうが良いです。
3.2 例:Clip(text, length)
Clip は「切り取る」か「切り詰める」か不明確。
明確にするために Truncate という名前を使う。
# あいまいな名前
clipped_text = Clip(text, length)
# 明確な名前
truncated_text = Truncate(text, max_length)Clip はあいまいだが、Truncate なら目的が明確です。
名前が誤解を招きやすいケースと明確な名前の付け方が解説されています。名前が誤解を招かないことが大切です。
3.3 限界値を含めるときはminとmaxを使う
限界値を表す場合はmax_やmin_といった接頭辞を使う。
# あいまいな名前
limit = 100
# 明確な名前
max_limit = 100max_という接頭辞を付けることで、限界値であることを明示できます。
3.4 範囲を指定するときはfirstとlastを使う
包含的な範囲を表す場合はfirstとlastを使う。
# あいまいな名前
start = 0
end = 10
# 明確な名前
first = 0
last = 10firstとlastを使うことで、範囲に値が含まれることが明確になります。
数値の限界値や範囲を表す場合の明確な名前の付け方が紹介されています。誤解のない名前付けが大切です。
3.5 包含/排他的範囲にはbeginとendを使う
包含/排他的な範囲の場合はbeginとendを使う。
# あいまいな名前
start = 0
finish = 10
# 明確な名前
begin = 0
end = 10beginとendを使うことで、範囲の端が含まれないことが明確になります。
3.6 ブール値の名前
ブール値の変数はis_やhas_といった接頭辞を付ける。
# あいまいな名前
activated = True
# 明確な名前
is_activated = Trueis_を付けることでブール値であることが明示されます。
ブール値や範囲を表す名前の明確な付け方が紹介されています。名前から意味を誤解されにくくすることが大切です。
3.7 ユーザの期待に合わせる
ユーザにとって既に意味がある名前は、その意味合いに沿って使う。
# ユーザの期待に反する名前
def get_size():
# 実際には項目数を返す
# ユーザの期待に合わせた名前
def get_count():
# 項目数を返すget_size() はユーザにとって物理的なサイズを期待させるので、countを返すならget_count()とする。
3.8 例:複数の名前を検討する
名前の候補を列挙し、誤解の可能性を考えて判断する。
# template は「テンプレートを使う」ではなく「テンプレートとする」の意味合いが強いため不適切
# reuse は再利用する数を期待させる可能性がある。reuse_id とする。
# copy はコピーする回数を期待させる可能性がある。copy_experiment とする。
# inherit はプログラマにとってなじみ深く、継承する意味が明確。候補を列挙して誤解の可能性を考えることで、最適な名前を選択できます。
名前が誤解されるケースとその防止策が紹介されています。名前から意図した意味が明確に伝わることが大切です。
3.9 まとめ
名前が誤解されないようにする
限界値はmin/maxを使う
範囲はfirst/lastやbegin/endを使う
ブール値はis/hasを使う
ユーザの期待に合わせる
候補を列挙して判断する
名前が誤解を招きにくくするための様々なテクニックが紹介されました。
限界値や範囲を表す場合は慣例の名前を使う
ブール値はis/hasなどを prefix に付ける
ユーザの先入観に合わせた名前を使う
候補を列挙して誤解の可能性を検討する
などがポイントです。名前から正しい意味が明確に伝わるようにすることが大切です。
4章 美しさ
コードの見た目の美しさを改善するテクニックについて解説しています。

4.1 なぜ美しさが大切なのか?
見た目の良いコードは読みやすく、保守もしやすい。
コードレイアウトは大切な要素である。
# 読みにくい例
class StatsKeeper:
def __init__(self):
self.count=0
self.minimum=0
self.maximum=0
def Add(self,d):
...
def Average(self):
...
# 読みやすい例
class StatsKeeper:
def __init__(self):
self.count = 0
self.minimum = 0
self.maximum = 0
def Add(self, d):
...
def Average(self):
...インデントとスペースの配置を整えるだけで読みやすさが大きく向上しています。
4.2 一貫性のある簡潔な改行位置
改行位置を画一的にする。
似たようなコードは見た目も似せる。
# 一貫性なし
foo = ClassA(arg1, arg2, arg3)
bar = ClassB(arg1, arg2,
arg3)
# 一貫性あり
foo = ClassA(arg1, arg2, arg3)
bar = ClassB(arg1, arg2,
arg3)改行位置を揃えることで一貫性が生まれ、読みやすくなります。
コードの見た目の美しさを改善する様々なテクニックが紹介されています。きれいなコードは読みやすく、保守もしやすくなります。
4.3 メソッドを使った整列
メソッドチェーンなどを使って整列する。
# 整列なし
assert(ExpandFullName(database_connection, "Doug Adams", &error)
== "Mr. Douglas Adams")
# メソッドで整列
CheckFullName("Doug Adams",
"Mr. Douglas Adams",
"")メソッドを使うことでパラメータを整列でき、見た目がすっきりします。
4.4 縦の線をまっすぐにする
縦方向の整列線が読みやすさに影響する。
# 整列なし
cmds = {
"timeout": cmd_timeout,
"timestamping": cmd_timestamping,
"tries": cmd_tries,
"useproxy": cmd_useproxy,
}
# 整列あり
cmds = {
"timeout": cmd_timeout,
"timestamping": cmd_timestamping,
"tries": cmd_tries,
"useproxy": cmd_useproxy,
}縦の整列線をそろえることで、全体の流れが目で追いやすくなります。
コードの見た目のレイアウトが読みやすさに与える影響が説明されています。揃った配置とインデントは効果が大きいです。
4.5 一貫性と意味のある並び
順序に一貫性を持たせる
意味のある順序づけをする
# 順不同
details = request.POST.get('details')
phone = request.POST.get('phone')
email = request.POST.get('email')
url = request.POST.get('url')
location = request.POST.get('location')
# 意味のある順序
url = request.POST.get('url')
email = request.POST.get('email')
location = request.POST.get('location')
details = request.POST.get('details')
phone = request.POST.get('phone')定義の順序に一貫性と意味のある順づけをすることで、読みやすさが向上します。
4.6 宣言をブロックにまとめる
関連する宣言をまとめてブロックにする。
# グループ化なし
def view_profile(request):
...
def save_profile(request):
...
# グループ化あり
def view_profile(request):
...
def save_profile(request):
...
# ユーティリティ
def util1():
...
def util2():
...関連する宣言をブロックにまとめることで、全体の構造が把握しやすくなります。
コードの配置を改善する具体的なテクニックが紹介されています。美しいコードは読みやすく保守もしやすいので大切です。
4.7 コードを「段落」に分割する
空行を使ってコードを段落分けする。
# 段落なし
for customer_id in all_customers:
for sale in all_sales[customer_id].sales:
if sale.recipient == customer_id:
...
# 段落あり
for customer_id in all_customers:
for sale in all_sales[customer_id].sales:
if sale.recipient == customer_id:
...空行による段落分けが、コードブロックの切れ目を明示してくれます。
4.8 個人的な好みと一貫性
個人的なコーディングスタイルはあるが、チーム内では一貫性が必要。
# チームのスタイル
class Foo:
def __init__(self):
...
# 個人のスタイル
class Foo:
def __init__(self):
...個人的なスタイルはあるものの、チーム内では一貫したスタイルに従うことが大切です。
コードの見た目を整えるための様々なテクニックが解説されています。コードの配置は読みやすさに大きな影響を与えるので、見た目の美しさに注力することが重要です。
4.9 まとめ
コードの見た目は読みやすさに影響する
一貫性のある配置とインデント
メソッドチェーンなどで整列する
縦の整列線を揃える
意味のある順序づけをする
関連するコードをブロックにまとめる
段落分けで構造を明示する
個人的なスタイルはあるが、チームの一貫性が重要
コードのレイアウトを改善する様々なテクニックが紹介されました。
一貫した配置とインデントを心がける
メソッドチェーンなどでアライメントを取る
縦方向の揃えを意識する
意味のある順序づけをする
関連するコードをグループ化する
段落分けで構造を明示する
などの点に注目することで、コードの見た目の美しさを向上させることができます。これによりコードの可読性が格段に向上します。
5章 コメントすべきことを知る
ソースコードにコメントを付ける際に注意すべきポイントについて解説しています。コメントはコードの意図を読み手に伝えるためにあることを理解し、適切なコメントの書き方を学ぶことができます。

5.1 コメントするべきでは「ない」こと
コードからすぐにわかることはコメントに書かない
ひどい名前の関数にコメントを付けず、名前を変える
例えば、以下のようなコメントは不要です。コードから意味がすぐに理解できるので、コメントはむしろ邪魔になります。
# 変数xに1を代入する
x = 1ひどい名前の変数や関数にコメントで補うより、名前自体を変更したほうがよいでしょう。
# xという変数はユーザの年齢(整数値)を表す
x = 20
# 上のコードより:
user_age = 205.2 自分の考えを記録する
なぜそのようにコーディングしたかの理由を書く
欠点があることをTODOで記載する
例えば、非効率的なアルゴリズムを使っている場合は以下のように書きます。
# TODO: この線形探索は非効率なので、ハッシュテーブルを使ったほうが良い5.3 読み手の立場になって考える
読者が疑問に思う点を予想して記載する
処理の概要を簡単に説明する
例えば、複雑な処理の概要を以下のように書きます。
# この関数は、ユーザの設定情報をデータベースから取得し、
# 電子メールで送信する。
def send_config_via_email(user_id):
# データベースからユーザ情報を取得
# ...
# メール本文を作成
# ...
# メールを送信する
# ...このように、コメントを適切に使うことで、コードの意図が伝わりやすくなります。
5.4 ライターズブロックを乗り越える
ライターズブロックを克服するためには、最初に評価を気にせず思いつくままにコメントを書くと良い
コメントの読み返しと改善は後から行う
コメントの作成を最後に一度に行うのではなく、早めに書く
# 初期のコードとコメント
def calculate_average(numbers):
# 合計を計算
total = sum(numbers)
# 平均を計算
average = total / len(numbers)
return average
numbers = [2, 4, 6, 8, 10]
# 平均を計算
print(calculate_average(numbers))上記のコードには、コメントが含まれていますが、これらはあまり有用ではありません。なぜなら、コメントが何を言っているかはコード自体から明らかだからです。これを改善するためには、コメントが何をするかではなく、なぜそれをするのかを説明するべきです。
# 改善したコードとコメント
def calculate_average(numbers):
# 数値リストの合計を計算します。これは後で平均を計算するために必要です。
total = sum(numbers)
# 合計をリストの長さで割ります。これにより数値リストの平均を得ます。
average = total / len(numbers)
return average
numbers = [2, 4, 6, 8, 10]
# 数値リストの平均を計算して出力します。
print(calculate_average(numbers))
ここでは、コメントはコードの目的とその行が何を達成するために存在するかを説明します。これにより、他の開発者がコードを理解しやすくなります。
「リーダブルコード」は、ソースコードを理解しやすく、読みやすくする改善に向けて書かれた一冊です。3200円で、あなたのプログラミングスキルを向上させます。
5.5 まとめ
コードについて頭の中でぼんやり考えていたことをはっきりとコメントとして書き出すことの重要性を説明しました。
コメントすべきではないこと
コードからすぐにわかること
コードの欠点を補うためのコメント(ひどい名前の関数など)
記録すべき自分の考え
なぜその実装を選んだのか(コードの欠陥への対処法も)
定数の値選択の理由
読者の立場になって
読者が疑問に思いそうなことへの説明
関数やクラスの全体像説明
コードブロックの要約
コメントの目的はコードの意図を読み手に伝えることです。コードについての考えをはっきり文章化することが大切です。
# 定数の値にコメントを付ける
MAX_DEPTH = 20 # 十分に大きい値
# 欠陥があるコードにTODOコメントを付ける
def process(data):
# TODO: この実装は遅いので改善が必要
# 関数の概要を説明するコメント
def print_report():
# ユーザデータをDBから取得
# レポートをファイルに出力
# メールでユーザに送信上記のPythonコードでは、定数の値選択理由、コードの欠陥、関数の概要についてコメントを付ける例を示しています。このようにコメントを活用することで、コードの意図を読み手に伝えやすくなります。
はい、わかりました。6章の内容を続けて出力します。
6章 コメントは正確で簡潔に
コメントを正確かつ簡潔に記述する方法について説明しています。コメントには限られたスペースしかないので、情報量をできるだけ高くする必要があります。

6.1 コメントを簡潔にしておく
同じことの説明を複数行にわたって書くのではなく、1行で説明できるようにする。
# 末尾の空白文字を取り除く
text = text.rstrip()上の1行のコメントのほうが、以下のように複数行で説明するよりも簡潔です。
# この文字列の末尾にある空白文字を取り除きます。
# 空白文字とは、スペース、タブ、改行文字のことです。
text = text.rstrip()代名詞の使用は避け、具体的な名詞を使う。
6.2 関数の動作を正確に記述する
関数の入出力の詳細な例を示すことで、動作を正確に説明できる。
# 文字列を反転する。例: reverse("abc")は"cba"を返す。
def reverse(text):
return text[::-1]6.3 情報の濃密な言葉を使う
プログラミングで頻出するパターンや概念を表す専門用語を使うことで、簡潔な説明が可能。
# このクラスはデータベースのキャッシュ層を実装するコメントは限られたスペースの中で正確かつ簡潔に情報を伝える必要があります。専門用語の活用や実例の提示などが有効です。
はい、「リーダブルコード」の6章の続きを出力します。
6.4 名前付き引数コメント
引数の意味が不明確な関数呼び出しに、インラインコメントを使って引数の名前を付けると良い。
# Connect(タイムアウト時間=10秒、暗号化を使う=False)
Connect(/* timeout_secs = */ 10, /* use_encryption = */ False)このようにコメントで名前付き引数を明示することで、関数呼び出しの意図が明確になります。
6.5 情報の濃密な言葉を使う
プログラミングで頻出するパターンや概念を表す専門用語を使うと、簡潔な説明が可能。
# このクラスはデータベースのキャッシュ層を実装する6.6 まとめ
代名詞の使用は避ける
関数の入出力例を示す
情報が濃密な専門用語を使う
名前付き引数コメントを使う
等の方法で、正確かつ簡潔なコメントを心がけましょう。
はい、「リーダブルコード」の7章の内容を出力します。
7章 制御フローを読みやすくする
条件文やループなどの制御フローを読みやすくする方法について説明しています。

7.1 条件式の引数の並び順
比較する値のうち、変化しやすい値を左に、安定した値を右に置く。
# 良い例
if score >= passing_score:
# 悪い例
if passing_score <= score:左側に変化する値を置くのが自然で読みやすいorderingです。
7.2 if/elseブロックの並び順
肯定的な条件、単純な条件、重要な条件を先に置く。
# 良い例
if file_exists:
# ファイルが存在する場合
else:
# ファイルが存在しない場合
# 悪い例
if not file_exists:
# ファイルが存在しない場合
else:
# ファイルが存在する場合肯定的な条件を先に置く方が自然です。
7.3 三項演算子
三項演算子は複雑な条件では避け、簡単な条件でのみ利用する。
# 良い例
value = 1 if x > 0 else 0
# 悪い例
value = a > b ? func1() : func2()複雑な条件の場合はif文を利用したほうが良いです。
制御フローを自然な順序で読みやすく配置することが大切です。
はい、「リーダブルコード」の7章の続きです。
7.4 do/whileループを避ける
do/whileループは条件判定がループの後にあるので読みにくい。whileループを使う。
# 良い例
while node is not None:
# 処理
# 悪い例
do:
# 処理
while node is not Nonewhileループのほうが自然な流れです。
7.5 関数から早く返す
エラーや特別な条件が発生したら早期リターンする。ネストを浅く保つ。
# 良い例
def process(data):
if data is None:
return
# 正常な処理
# 悪い例
def process(data):
if data is not None:
# 正常な処理
else:
# エラー処理早期リターンによりネストが浅くなります。
7.6 ネストを浅く保つ
ネストが深くなるとコードが読みにくくなる。continue文や早期リターンでネストを浅くする。
ネストの深い制御フローは読みにくいので、浅い方が好ましいです。
はい、「リーダブルコード」の7章の続きです。
7.7 実行の流れを追えるか
複雑な制御フローでは、コードの実行パスが追いにくくなる。
例:スレッド、シグナルハンドラ、例外処理、仮想関数等
これらはコード実行の流れを断続的にするので、利用を控えめにする。
# 例外処理の例
try:
# 正常処理
except Exception as e:
# 例外処理例外処理を複数ネストすると、実行パスが追いにくくなります。
7.8 まとめ
条件式やループの自然な順序を保つ
三項演算子は簡単な条件でのみ利用
ネストはできるだけ浅くする
実行パスが追えるようにする
以上の点に注意し、読みやすい制御フローを目指しましょう。
はい、「リーダブルコード」の8章の内容を出力します。
8章 巨大な式を分割する
長く複雑な式を分割して読みやすくする方法について解説しています。

8.1 説明変数
長い式の値を表す変数を導入する。式の意味が説明変数からわかる。
# 長い式
average = sum(data) / len(data)
# 説明変数
total = sum(data)
num_items = len(data)
average = total / num_items式の意味が明確になりました。
8.2 要約変数
長い式や複雑な処理を要約変数に代入する。
# 長い式
average = sum(data) / len(data)
# 要約変数
result = calculate_average(data)複雑な処理を要約変数に閉じ込められます。
8.3 ド・モルガンの法則
論理否定の分配律を利用して式を単純化する。
# 元の式
if not (value == 0 or value == 1):
# ド・モルガンの法則を適用
if value != 0 and value != 1:否定の分配により式が単純になりました。
長く複雑な式は分割して読みやすくすることが大切です。
はい、「リーダブルコード」の8章の続きです。
8.4 短絡評価の悪用
短絡評価は便利だが、悪用すると読みづらい式になる。分割したほうが良い。
# 悪用例
if (obj = get_obj()) and obj.is_valid():
# 処理
# 分割した例
obj = get_obj()
if obj and obj.is_valid():
# 処理短絡評価は慎重に利用しましょう。
8.5 例: 複雑なロジック
複雑な論理条件の場合、処理の「否定」から考えると単純化できる。
# 元の複雑な条件
if start1 <= end2 and start1 >= start2:
# 範囲が重なる
# 否定から考える
if end1 < start2 or end2 < start1:
# 範囲が重ならない否定の方が扱いやすい場合があります。
8.6 巨大な文を分割
長い文も小さく分割すると読みやすくなる。
巨大な式や文をコントロール可能なサイズに分割することがポイントです。
はい、「リーダブルコード」の8章の続きです。
8.7 式を簡潔にする創造的な方法
長い類似の式がある場合、マクロや関数等で簡潔にできる。
# 元の式
a = expr1(x)
b = expr2(x)
c = expr3(x)
# マクロで簡略化
#define PROCESS(v) expr##v(x)
a = PROCESS(1)
b = PROCESS(2)
c = PROCESS(3)マクロやラムダ式などで表現力を高め、簡潔な式を目指しましょう。
8.8 まとめ
説明変数、要約変数の利用
ド・モルガンの法則
短絡評価の適切な利用
否定から考える等のテクニック
を駆使して、巨大な式をコントロール可能なサイズに分割しましょう。
はい、「リーダブルコード」の9章の内容を出力します。

9章 変数と読みやすさ
変数の利用方法と読みやすさの関係について説明しています。

9.1 変数を削除する
不要な一時変数や中間結果の変数は削除可能。
# 一時変数
temp = x * 2
result = temp + y # tempは不要
# 中間結果変数
mid = func1()
final = func2(mid) # midは不要不要な変数がある場合は結果を直接利用する。
9.2 変数のスコープを縮める
変数のスコープ(生存範囲)を最小限にする。
# グローバル変数の代わりにローカル変数に
count = 0 # 悪い例
def func():
count = 0 # 良い例変数の存在範囲を絞ると理解が容易になる。
9.3 変数は一度だけ代入
変数の値が変化する箇所を少なく保つ。
# 悪い例
temp = 1
temp = 2
temp = 3
# 良い例
initial = 1
middle = 2
final = 3値が変化しにくい変数の方が扱いやすい。
はい、「リーダブルコード」の9章の続きです。
9.4 最後の例
不要な変数を削除し、スコープを絞り、一度だけ代入することで読みやすいコードに。
# 元のコード
found = False
i = 1
elem = document.getElementById('input'+i)
while elem:
# 複雑な処理
if found:
# 処理
# 改善コード
for i in range(1, MAX):
elem = document.getElementById('input'+i)
if 条件:
# 処理
break変数の利用を見直すことで改善できる場合があります。
9.5 まとめ
不要な変数は削除
変数のスコープは最小限に
値が固定化される変数を使う
以上の点に注意し、適切に変数を利用することで、読みやすいコードになります。
はい、「リーダブルコード」の10章の内容を出力します。
10章 無関係の下位問題を抽出する
プログラムの主要な目的と関係のない処理を関数に抽出する方法について解説しています。

10.1 入門的な例
主要な目的(最寄りの場所を探す)と関係ない処理(2点間の距離計算)を関数に抽出。
# 元のコード
for loc in locs:
# 複雑な距離計算
# 改善コード
def calc_distance(loc1, loc2):
# 距離計算
for loc in locs:
dist = calc_distance(loc1, loc)距離計算を関数に抽出することで、メインの目的が際立ちます。
10.2 純粋なユーティリティコード
一般的な処理は汎用的な関数/ユーティリとして実装する。
# 文字列をファイルに書き込む汎用関数
def write_string(s, filename):
# ファイル書き込み処理これを呼び出すことで、その処理を意識する必要がなくなります。
10.3 その他の汎用コード
主要な目的と関係の薄い処理は関数に集約する。
# 複雑なHTMLエスケープ処理
escaped_text = escape(text)
# メイン処理
print(escaped_text)関係の薄い処理を関数に隠蔽することで、メインの目的に集中できます。
はい、「リーダブルコード」の10章の続きです。
10.4 汎用コードをたくさん作る
汎用的な関数をたくさん作成し、コアな処理を小さく保つ。
# 汎用関数群
def read_config():
# 設定ファイルの読み込み
def connect_db():
# データベース接続
def send_mail():
# メール送信
# コアな処理
config = read_config()
db = connect_db()
send_mail(config, db)汎用コードとアプリ固有のコードを分離する。
10.5 プロジェクトに特化した機能
プロジェクト固有でも、関係の薄い処理は関数にする。
# 固有の処理
def escape_html(text):
# HTMLエスケープ
print(escape_html(input))プロジェクト固有でも、関係の薄い処理を隠蔽しましょう。
10.6 まとめ
主要な目的と関係の薄い処理を関数に隠蔽する。
汎用的な機能はなるべく独立した関数/ユーティリとして実装。
コアな処理を小さく保ち、読みやすくする。
以上の点が重要です。
はい、「リーダブルコード」の11章の内容を出力します。
11章 一度に1つのことを
一度に複数のことをするコードを分割して、一度に1つのことを行うコードにする方法について説明しています。

11.1 タスクは小さくできる
コードが行っているタスクをすべて列挙し、できる限り異なる関数に分割する。
# 元のコード
# タスク1
# タスク2
# タスク3
# 分割コード
def task1():
# タスク1
def task2():
# タスク2
def task3():
# タスク3
task1()
task2()
task3()タスクごとのコードに分割することで、一度に1つのことになりました。
11.2 オブジェクトから値を抽出
オブジェクトから値を抽出する処理を関数に分割。
# 元のコード
name = obj["name"]
id = obj["id"]
# 分割コード
def get_name(obj):
return obj["name"]
def get_id(obj):
return obj["id"]
name = get_name(obj)
id = get_id(obj)データの抽出処理を分割すると、オブジェクトの構造を隠蔽できます。
一度に複数のことをするコードは分割して、一度に1つのタスクを行うコードにしましょう。
はい、「リーダブルコード」の11章の続きです。
11.3 複数の値を設定
複数の変数に値を設定する処理を分割する。
# 元のコード
x = 1
y = 2
z = 3
# 分割コード
def set_x():
return 1
def set_y():
return 2
def set_z():
return 3
x = set_x()
y = set_y()
z = set_z()値の設定処理を分割することで、変数間の依存関係がなくなりました。
11.4 複数の副作用を分離
副作用のある処理をできるだけ分割して、副作用の範囲を限定する。
# 良い例
def query():
# DBからデータ取得
def update_cache(data):
# キャッシュ更新
data = query()
update_cache(data)副作用のある処理queryとupdate_cacheを分割することで、副作用がupdate_cacheに限定されました。
11.5 まとめ
タスクごとに分割
データ抽出を関数に
値設定を分割
副作用のある処理を分離
一度に1つのことに集中できるコードを目指しましょう。
「リーダブルコード」は、ソースコードを読みやすくすることを理解し、コードの改善に向けて参考になる一冊です。3,300円で、あなたのプログラミングスキルを向上させます。
購入先 : https://www.oreilly.co.jp/books/9784873118468/ ↗
原書: The Art of Readable Code
著者名: Dustin Boswell, Trevor Foucher
出版日: 2011年11月
価格: 3,300円
12章 コードに思いを込める
プログラムの動作を簡単な言葉で説明することで、コードをより明確にする技法について説明しています。

12.1 ロジックを明確に説明する
コードの動作を同僚にもわかるような簡単な言葉で説明することで、コードがより自然になることを紹介しています。
コードの動作を簡単な言葉で説明すると、コードがより自然になる
説明で使うキーワードやフレーズが、関数や変数の適切な名前になる
def shipping_cost(weight):
if weight < 5:
return 500
elif weight < 10:
return 800
else:
return 1200この関数の動作を簡単な言葉で説明すると以下のようになる。
「小さい荷物は500円、中くらいの荷物は800円、大きい荷物は1200円」
この説明から関数名や変数名を適切に変更できる。
def calculate_shipping_cost(package_weight):
if package_weight < 5:
return 500
elif package_weight < 10:
return 800
else:
return 120012.2 ライブラリを知る
標準ライブラリの機能を知ることで、簡潔なコードを書くのに役立つことを説明しています。
標準ライブラリの関数やクラスを知っておくと、余分なコードを書かずに済む
ライブラリを使えばコード量が減る上に、品質も向上する
ages = [23, 19, 54, 44, 29]
# 集計処理を自前で実装
count_under_30 = 0
for age in ages:
if age < 30:
count_under_30 += 1
print(count_under_30)これはPythonの標準ライブラリを使えば以下のように簡潔に書ける。
from collections import Counter
ages = [23, 19, 54, 44, 29]
under_30 = Counter(age for age in ages if age < 30)
print(under_30[True])標準ライブラリを知ることで、余分なコードを書かずに済み、コードの量と品質が向上した。
12.3 この手法を大きな問題に適用する
大きな問題にこの手法を適用する方法を説明しています。
大きな関数も、動作を簡単な言葉で説明することができる
説明から関数を小さな関数に分割できる
# 複数のデータソースを結合するロジックが長く複雑
def combine_data_sources():
for source1_row in source1:
# source1のデータ取得
for source2_row in source2:
# source2のデータ取得
if source1_time != source2_time:
# 時間が一致しない場合はスキップ
continue
# 時間が一致した行の処理
process_row(source1_row, source2_row)この関数の動作を簡単な言葉で説明する。
「ソース1とソース2からデータを取得する。時間が一致しない行はスキップする。一致した行を処理する。」
この説明から、時間の一致処理を関数に分割できる。
def skip_unmatched_rows(source1, source2):
# 時間が一致しない行をスキップする処理
def combine_data_sources():
for source1_row in source1:
# source1のデータ取得
for source2_row in source2:
# source2のデータ取得
skip_unmatched_rows(source1_row, source2_row)
# 一致した行の処理動作を簡単な言葉で説明することで、関数の分割が明確になった。
12.4 まとめ
プログラムの動作を簡単な言葉で説明すると、コードが自然に改善される
ライブラリを知ることで、簡潔なコードを書ける
大きな関数も、説明から適切に分割できる
簡単な言葉で説明することで、コードの改善に役立つ洞察が得られる強力な技法です。
13章 短いコードを書く
できるだけコード量を抑える方法について説明しています。

13.1 その機能の実装について悩まないで —きっと必要ないから
必要のない機能は実装しないことを提案しています。
過剰な機能を実装すると、コード量が増えて保守が困難に
必要のない機能は削除するのが賢明
# 複雑な統計処理があるけど、必要ない
def analyze_data(data):
mean = calculate_mean(data)
std_dev = calc_std_dev(data)
quartiles = find_quartiles(data)
# 計算結果を使っていない必要のない統計処理を削除し、簡素なコードにする。
def analyze_data(data):
mean = calculate_mean(data)
# std_devやquartilesは削除13.2 質問と要求の分割
要求を細分化することで、簡易な実装で問題を解決できることを説明しています。
要求をできるだけ小さな単位に分割する
分割した要求を順次実装していけば、全体が簡潔になる
# 複雑な統計処理があるけど、必要ない
def analyze_data(data):
mean = calculate_mean(data)
# 第1段階:平均値だけ計算
print(mean)
# 第2段階:標準偏差を計算
std_dev = calc_std_dev(data)
print(std_dev)
# 第3段階:四分位数を計算
quartiles = find_quartiles(data)
print(quartiles)要求を分割して段階的に実装することで、簡易なコードを書ける。
13.3 コードを小さく保つ
プロジェクトの規模が大きくならないよう、コード量を意識することを提案しています。

コードが増えると保守が困難になる
コード量をできるだけ抑える努力が必要
# データ処理用の汎用的なユーティリティを作成
data_utils.py
def clean_data(data):
# データクリーニング処理
def analyze_data(data):
# データ解析処理汎用的な処理は共通ライブラリとしてREUSEすることでコード量を抑えられる。
# ライブラリをインポートして使用
import data_utils
data_utils.clean_data(data)
data_utils.analyze_data(data)13.4 身近なライブラリに親しむ
標準ライブラリやサードパーティ製ライブラリの活用方法を紹介しています。
標準ライブラリを熟知することが重要
ライブラリを使うことでコード量が減る
ages = [12, 33, 6, 54, 8]
# データ集計処理を自前で実装
child_count = 0
for age in ages:
if age < 18:
child_count += 1
print(child_count)Pythonの標準ライブラリを使えば以下のようになる。
from collections import Counter
ages = [12, 33, 6, 54, 8]
child_count = Counter(age for age in ages if age < 18)
print(child_count[True])標準ライブラリを使うことでコード量が減り、可読性が向上した。
13.5 まとめ
過剰な機能を実装しない
要求を細分化する
コード量をできるだけ少なく保つ
標準ライブラリを活用する
というのが、コード量を抑える秘訣です。
14章 テストと読みやすさ
読みやすく効果的なテストコードの書き方について説明しています。


14.1 テストを読みやすくて保守しやすいものにする
テストコードも本番のコード同様、読みやすく保守しやすい必要があることを説明しています。
テストコードは本番のコード同様、読みやすくする必要がある
読みにくいテストコードは保守が困難
# 読みにくいテストコードの例
def test_calc_total():
cart = Cart()
cart.add("A", 100)
cart.add("B", 200)
assert cart.total() == 300テストコードも他のコード同様、読みやすく保守しやすくする。
# 読みやすいテストコード
def test_calc_total_empty():
cart = Cart()
assert cart.total() == 0
def test_calc_total_single_item():
cart = Cart()
cart.add("A", 100)
assert cart.total() == 100
def test_calc_total_multi_items():
cart = Cart()
cart.add("A", 100)
cart.add("B", 200)
assert cart.total() == 30014.2 このテストのどこがダメなの?
テストがなぜ失敗したのかがすぐにわからないテストは改善が必要だと説明しています。
テストの失敗理由が不明確であれば、テストが悪い
失敗の理由が明確になるようテストを改善する
# テスト結果が不明確な例
def test_encode_string():
encoded = encode("Hello World")
assert encoded == "fkpsodmncxzvo" # エンコード結果をハードコーディングテスト結果からエラー原因が明確にわかるようにする。
def test_encode_string():
encoded = encode("Hello World")
expected = "fkpsodmncxzvo"
assert encoded == expected, "Encode result is different"失敗時のメッセージを追加し、エラー原因を明確にした。
14.3 テストを読みやすくする
複雑なテストコードを読みやすくする方法を説明しています。
複雑なテストは読みにくい
小さなテストに分割したり、ヘルパーを使ったりする
# 複雑なテストコード例
def test_encode_string():
input = "Hello World"
encoder = Encoder(key=5)
encoded = encoder.encode(input)
expected = "fkpsodmncxzvo"
assert encoded == expected, "Encode result is different"テストを複数の小さなテストに分割する。
# テストを分割
def test_encode_simple_string():
encoder = Encoder(key=5)
encoded = encoder.encode("Hello")
expected = "fkpsodmncxzvo"
assert encoded == expected
def test_encode_string_with_spaces():
encoder = Encoder(key=5)
encoded = encoder.encode("Hello World")
expected = "ojewf rphuoxv"
assert encoded == expected
# 追加のテスト...テストヘルパーを使ってテストを共通化する。
# テストヘルパーの利用
def _assert_encoded(encoder, input, expected):
encoded = encoder.encode(input)
assert encoded == expected
def test_encode_simple_string():
encoder = Encoder(key=5)
_assert_encoded(encoder, "Hello", "fkpsodmncxzvo")
def test_encode_string_with_spaces():
encoder = Encoder(key=5)
_assert_encoded(encoder, "Hello World", "ojewf rphuoxv")
# 追加のテスト...14.4 エラーメッセージを読みやすくする
テストのエラーメッセージを読みやすくする方法を説明しています。
エラーメッセージが分かりにくいとデバッグが困難
エラーメッセージを読みやすくするべき
# エラーメッセージが分かりにくい例
def test_split_string():
result = split_string("Hello World")
assert result == ["Hello", "World"] # 一般的なassertエラーメッセージを具体的にする。
def test_split_string():
result = split_string("Hello World")
assert result == ["Hello", "World"], "Split result is incorrect"期待値と実際の値を表示する。
def test_split_string():
result = split_string("Hello World")
expected = ["Hello", "World"]
assert result == expected, f"Expected {expected}, but got {result}"14.5 テストの適切な入力値を選択する
テストに適切な入力データを使う重要性を説明しています。
テストデータを適切に選択することが大切
デフォルト値や簡略データを利用する
# 複雑なテストデータ
def test_paginate():
items = [_generate_item() for i in range(1000)]
# 1000件のデータでテストする(非効率)
paginate(items)簡略なテストデータを使う。
# 簡略なテストデータ
def test_paginate():
items = [_generate_item() for i in range(3)]
# 3件のデータでテスト
paginate(items)デフォルト値を使う。
# デフォルト値の利用
def test_paginate(items=None):
if items is None:
items = [_generate_item() for i in range(3)]
# 3件のデフォルトデータでテスト
paginate(items)14.6 テストの機能に名前をつける
テストケースに適切な名前を付ける重要性を説明しています。
テストケースに適切な名前を付ける
テスト内容が名前からわかるように
# テスト名が不明確
def test_encode():
# 文字列のエンコードをテスト
...
def test_decode():
# 文字列のデコードをテスト
...テスト名を具体的に。
def test_encode_english():
# 英語のエンコードをテスト
...
def test_decode_japanese():
# 日本語のデコードをテスト
...テスト対象の動作を名前に含める。
def test_encode_to_base64():
# base64エンコードをテスト
...
def test_decode_from_base64():
# base64デコードをテスト
...14.7 このテストのどこがダメだったのか?
テスト失敗の原因を特定しづらいケースを避ける方法を説明しています。
テスト失敗の原因が特定しづらい場合がある
そうしたパターンは避けるべき
# テスト失敗の原因が特定しづらい例
def test_encode_and_decode():
input = "foobar"
encoded = encode(input)
decoded = decode(encoded)
assert decoded == inputエンコードとデコードを分離する。
def test_encode():
input = "foobar"
encoded = encode(input)
assert encoded != input
def test_decode():
input = "foobar"
encoded = encode(input)
decoded = decode(encoded)
assert decoded == input失敗した場所をすぐに特定できるようにテストを分けた。
14.8 テストに優しい開発
テスト優先の開発手法を説明しています。
テストから開発を始める(テスト優先開発)
小さな単位でテストできるよう設計する
# テスト不可能な実装例
class UserService:
def __init__(self):
self.db = Database()
def register(self, user_id, name):
# ユーザ登録処理
...
# テストできない(DB接続が必要)
user_service = UserService()
user_service.register("user1", "Bob")インタフェースと実装を分離する。
# インタフェースと実装の分離
class UserService:
def __init__(self, user_repository):
self.user_repository = user_repository
def register(self, user_id, name):
# ユーザ登録処理
...
class UserRepository:
def register(self, user_id, name):
# 実際のDB登録処理
# テスト
mock_repo = MockUserRepository()
user_service = UserService(mock_repo)
user_service.register("user1", "Bob")DIを利用してテスト可能な設計にした。
14.9 まとめ
テストコードの品質も保つ
失敗時の原因が明確なテストを書く
適切な入力データ、名前、構成でテストを読みやすくする
テスト容易な設計をする
というのが、読みやすいテストコードの作り方の要点です。
以上で14章の要約でした。何か質問はありますか?
15章 「分/時間カウンタ」を設計・実装する
「分/時間カウンタ」を例に取り、読みやすい設計と実装方法を説明しています。
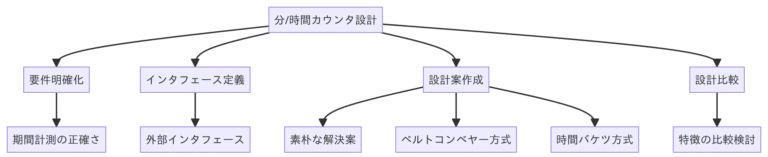
15.1 問題点
分/時間カウンタを実装する必要がある
過去の期間の分・時間数を正確に集計できること
データ構造が複雑になりがち
15.2 クラスのインタフェースを定義する
まず外部から利用するインタフェースを定義します。
class TimeCounter:
def add_interval(start, end):
# 指定期間の分・時間数を追加する
def total_minutes():
# 登録された総分数を返す
def total_hours():
# 登録された総時間数を返す15.3 試案1: 素朴な解決策
まずは単純な実装方法を試してみます。
class SimpleTimeCounter:
def __init__(self):
self.total_minutes = 0 # 総分数
def add_interval(self, start, end):
minutes = (end - start).total_minutes()
self.total_minutes += minutes
def total_minutes(self):
return self.total_minutes
def total_hours(self):
return self.total_minutes / 60間隔を追加するたびに総分数を更新するシンプルな実装です。
15.4 試案2: ベルトコンベヤー設計
SimpleTimeCounterは正確ではないので、ベルトコンベヤー方式の設計を試みます。
class ConveyorBeltCounter:
def __init__(self):
self.intervals = [] # 間隔のリストを保持
def add_interval(self, start, end):
self.intervals.append((start, end))
def total_minutes(self):
total = 0
for start, end in self.intervals:
total += (end - start).total_minutes()
return total
def total_hours(self):
return self.total_minutes() / 60すべての間隔を保持し、集計時に合計する設計です。
15.5 試案3: 時間バケツの設計
最後に「時間バケツ」の考え方を使った実装方法を試みます。
class BucketTimeCounter:
def __init__(self, bucket_size):
self.buckets = []
self.bucket_size = bucket_size # バケツの大きさ(分)
def add_interval(self, start, end):
start_bucket = start // self.bucket_size
end_bucket = end // self.bucket_size
for i in range(start_bucket, end_bucket+1):
self.buckets[i] += (end - start).total_minutes()
def total_minutes(self):
return sum(self.buckets)時間をバケツに分けて集計するので、正確かつ効率的です。
15.6 3つの解決策を比較する
3つの設計案を比較すると、以下のような特徴があります。
試案1は単純だが不正確
試案2は正確だが非効率
試案3は正確で効率的だが複雑
ニーズに合わせて適切な設計を選択することが重要です。
15.7 まとめ
問題の要件を明確化する
インタフェースと実装を分離する
複数の設計案を検討する
ニーズに合った設計を選択する
ことが、読みやすく実用的なコードを書く鍵となります。
おわりに

「リーダブルコード」は、ソースコードの読みやすさを向上させる実践的なテクニックを紹介した一冊です。
コードは他の人が理解できる必要があり、読みやすさが最も重要だと説いています。
表面的な改善から始まり、ロジックの単純化、コードの再構成といった段階を踏んで、読みやすさに注力する方法を解説しています。
読み手の理解を助ける名前付け、適切なコメント、格式の整備などの基本は欠かせません。
ロジックの複雑さを減らし、巨大な式を分割することも有効です。
さらに、コードをより小さい単位に再構成することで、一度に1つのことに集中できるようになります。
テストコードにも読みやすさは重要です。失敗の原因が明確なテスト、適切な入力データ、テストファースト開発などが役立ちます。
読みやすいコードを書くには練習が必要ですが、コツを心得て実践すれば、高品質のコードが書けるようになるでしょう。
プログラミングのスキルと思考力が確実に向上する一冊です。

参考文献
Dustin Boswell、Trevor Foucher 著、角 征典 訳 (2012) 「O'Reilly Japan - リーダブルコード」
この記事が気に入ったらサポートをしてみませんか?