
研修資料でテキスト読み上げ音声を使った話(Amazon Pollyを使ってみた)

忘年会で飲むのは楽しいのに翌朝になるとお酒辞めたいって思う「ぎだじゅん」です。
ライフイズテックという会社でサービス開発部 インフラ/SREグループに所属しています。
忘年会や新年会のシーズンで、カラオケなどで盛り上がることも多いかと思います。
自分の声って、頭蓋骨を通して聞こえる声と、カラオケのスピーカーを通して聞く声とで結構違って聞こえるってありますよね。
スピーカーを通して聞く声は、自分としてはとても違和感があって受け入れがたい声なので、カラオケでは絶叫系で声をごまかして歌います。

選曲にも困りますよね。
自分の青春時代の歌を歌ったら、みんなが知らない曲にがんばって手拍子あわるような気を遣わせるシーンが多くなってきたので、毎年、忘年会シーズンにあわせて、どこかで聞いたことがあるような、その年にヒットした曲のMVをYoutubeで聴いて覚える努力家の自分です。

しかし、最近のヒット曲は歌の構成が難しく、高音から低音までの差が激しかったり、突然転調したり、変拍子になったり、早口だったりで、だいたい曲の前半を歌って疲労で終了し、結局、歌うよりも飲む量が増えて翌日お酒辞めたいって思うルーティンを繰り返している今日この頃です。

本題です。
文字を見せるだけでは思いは伝わらない
みなさん、社内向けの研修資料って、PowerPointやGoogleスライド、Keynoteなどで作ってます?
私はお仕事の一環で社内の情報セキュリティ研修の資料を、Googleスライドで作成しています。
情報セキュリティ研修は新入社員向けに入社時(毎月)と全従業員向けに年1回行っています。
ただ、最近社員がどんどん増えてきており、全従業員向けの研修では特定の時間に全員を集めて1時間ほどかけて説明するのが若干難しくなってきているので、なるべく各自が時間のある時に読んで勉強できるような内容で資料を作成しています。
そのため、情報セキュリティ研修のGoogleスライドでは、プレゼンなどの資料とは異なり、説明文章などの文字が多めとなっており、読むだけでどれだけ伝わっているかが悩ましい状況でした。
昨年の研修後のアンケートでも「文字が多すぎて必要なことが頭に入ってこない」などの意見もあり、このままではセキュリティ意識の向上は厳しいと反省しました・・・。

そこで、今年の新入社員向けの情報セキュリティ研修から、Googleスライドに音声で説明も流れるようにして、なるべく重要な箇所だけスライドに記載するように変更しました。
Googleスライドのスピーカーノートに説明する原稿を書き、その原稿を読んだ音声をPCにマイク付きイヤホンで1ページ分ずつ録音して音声ファイルを作成し、スライドの各ページに音声ファイルを挿入していきました。
しかし、出来上がったスライドをスライドショーで聞いてみると・・・・
自分の声があまりに暗くて低音で単調なので、下手すると眠くなりそうなスライドになってしまいました。

さらに、原稿を少し噛んでしまっていたり、全体を通して聞くとページごとに声のテンションやボリュームが異なっていて、学習に集中ができない感じでもありました。
これだけ苦労して録音して教材作っても、自分の声で台無しにしてしまっている感じがして、とても切ない気持ちでした。
日本初?のテキスト読み上げ機能を使ったLT
そんなときに、とあるセキュリティイベントでのこのLTを見て衝撃を受けました。
イベントの数日前から喉を傷めてしまってLTの発表の日が迫ってきた中で、Macのテキストを音声に読み上げる機能を使って乗り切ったというお話。
自分も実際にこのイベントを現地で拝見し、「これは使える!」と感動した勢いでXにポストしてしまいました。
そして何よりセキュリティ研修の資料を自分の声で説明する動画を作るよりも、Macの音声読み上げ機能で音声作って、音声付きGoogleスライドにしようと思った。
— ぎだじゅん (@gdjn2023) September 7, 2023
ありがとう、情報セキュリティのお姉さん!!#CSecMeetup
機械での読み上げでも多少は単調に感じるものの、自分が喋って聞き取りにくくなる箇所も丁寧に読み上げてくれるので、聞き取りやすさは断然良くなる想定です。
ついては、今年の全社員向けの情報セキュリティ研修では、テキストの読み上げ音声によるGoogleスライドを実際に作りました!!
(社内資料のため公開はできませんが)
Amazon Polly で音声を作成
私は普段は自社プロダクトでAWS環境を使ってのお仕事をしているため、今回、Amazon Pollyを使ってテキストから音声に変換を試みました。
ちなみに今回の例ではAmazon Pollyを使いましたが、Googleスライドでの音声の挿入は、.mp3形式の音声であれば他のテキスト読み上げサービスで生成された音声でも利用できると思います。
仕組み
Amazon Polly は深層学習技術を使用し、人間の声のような音声を合成します。そのため、記事を音声に変換することができます。幅広い言語に対応したリアルな音声を多数搭載しており、Amazon Polly を使用して音声起動型アプリケーションを構築することができます。
自然な声で顧客を惹き付ける
Amazon Polly の音声出力を保存および再生し、インタラクティブまたは自動化された音声応答システムを通じて発信者にプロンプトを表示します。
先にお詫びしておきますが、Apps ScriptなどでAmazon Pollyと連携してスピーカーノートにあるテキストから音声にリアルタイム変換して出力させれたの?ってな感じで期待された方、ごめんなさい。
(社内からもそんな期待の声があったのですが、がっかりさせてしまいました・・・)

今回、そこまで作り込む時間がなかった(実際には連携できる方法があるのか知らない)ので、Googleスライドのスピーカーノートに説明用として用意してあったテキスト原稿を使い、以下の力技で音声が流れるスライドを作成をしました。
各ページのスピーカーノートのテキストを1ページ分ずつAmazon Pollyで音声変換して、.mp3形式の音声ファイルを生成
Googleスライドの各ページ毎に作成した該当の音声ファイルを挿入
Amazon Pollyでは次のようにAWSのAmazon Pollyコンソールから音声ファイルを生成しました。
AWSでのAmazon Pollyの始め方
Amazon Polly を始めるには、AWS アカウント にサインアップ(すでにアカウントお持ちの方はサインイン)する必要があります。
まだAWSアカウントを作成したことがない方はこちらを参考にするとわかりやすいです。
なお、AWSアカウント上で初めてAmazon Pollyを利用される場合は、最初の12か月間は、毎月指定の文字数分のリクエストまで無料で利用できる「無料利用枠」があります!!。
(スタンダート音声の場合は500 万文字/月まで、ニューラルの場合は100 万文字/月まで最初のリクエストから 12か月間無料)
無料利用枠
毎月数百万文字
Amazon Polly の標準音声の場合、無料利用枠では、音声の最初のリクエストから 12 か月間は 1 か月あたり 500 万文字まで、音声または Speech Marks リクエストを利用できます。Amazon Polly のニューラル音声の場合、無料利用枠では、音声の最初のリクエストから 12 か月間は 1 か月あたり 100 万文字まで、音声または Speech Marks リクエストを利用できます。
AWSアカウントを複数のユーザで利用している場合、そのAWSアカウント上で他のユーザが一度Amazon Pollyを利用して12か月経過していたら、おそらく費用が発生します。
AWSアカウント作成やアカウント上でのサービス利用時に発生する料金については、各自の責任でお願いします。
Amazon Pollyのテキスト読み上げ機能の使い方
AWSアカウントのコンソールよりサインアップ(サインイン)できたら、Amazon Polly コンソールを開き、左上のメニューアイコンから[テキスト読み上げ機能(Text-to-Speech )] を選択します。
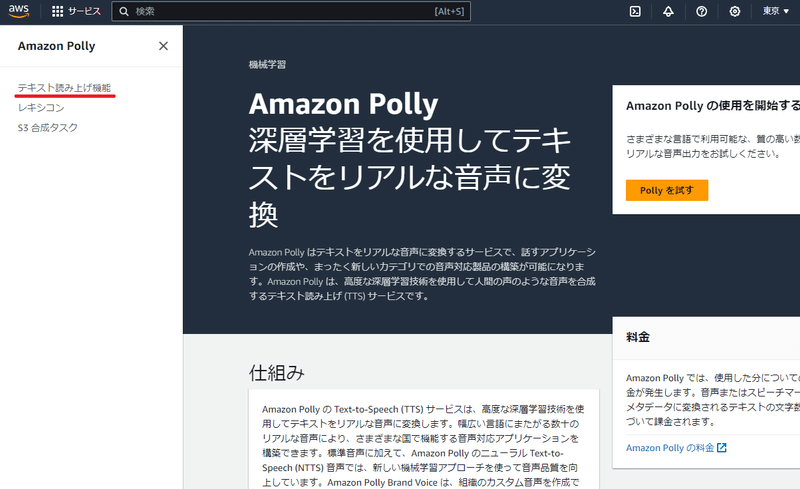
Amazon Pollyの「テキスト読み上げ機能」のコンソール画面は、以下のような感じでとてもシンプル。
ここの画面だけでテキストから音声ファイルの生成ができます。
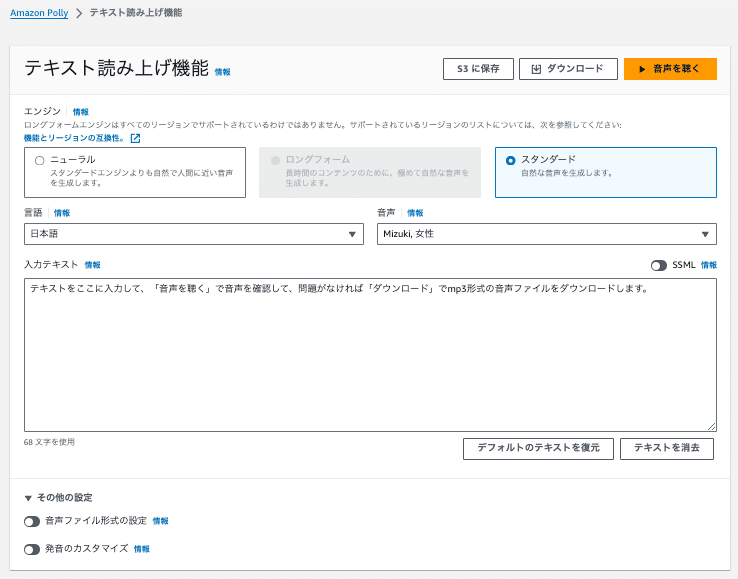
この画面から「エンジン 」(ニューラル、スタンダード) 、「言語」、「音声」を選択して、「入力テキスト」に読み上げしたいテキストを入力します。
エンジンの選択
スタンダード
サービス開始当初からの標準的な読み上げ
100 万文字あたり 4.00 USD
ニューラル
ニューラルテキスト読み上げ (NTTS)
スタンダードよりもより自然に人間らしい音声を生成。
詳しくはこちらを参照。100 万文字あたり 16.00 USD
ロングフォーム
長時間のコンテンツのために、さらに極めて自然な音声を生成
ただし、現状では東京リージョンでは使えない模様
言語の選択
いろいろな国の言語から選択ができます
音声の選択
言語が「日本語」の場合、以下の音声から選択できます
エンジンがスタンダードの場合
Takumi (男性)
Mizuki (女性)
エンジンがニューラルの場合
Takumi (男性)
Tomoko (女性)
Kazuha (女性)
入力テキストの入力
テキストは最大 3,000 文字まで入力可能。
「入力テキスト」の入力欄の左下に入力した文字数が表示されます。「入力テキスト」の右上の「SSML」スイッチを有効にすると、「音声合成マークアップ言語 (SSML)」を使って、テキストをSSMLタグで囲んだりすることで、生成される音声に対して、指定したフレーズを強調したり、一時停止を追加したりすることができます(後述で説明)。
テキストを入力できたら、一度右上の「音声を聴く」で音声を確認。
音声に問題なければ「ダウンロード」より音声ファイルをダウンロードできます。
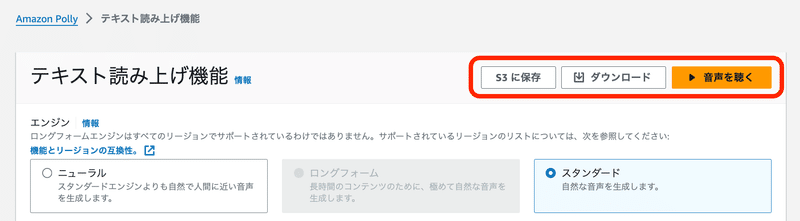
ダウンロードでは、デフォルトでは.mp3形式による音声ファイルが生成されます。
Googleスライドでの音声挿入は.mp3または.wav形式のみなので、今回はデフォルトの形式で問題ないです。
(後述の設定でOGGやPCMのファイル形式変更やサンプルレートも変更できます)
音声ファイル出力に関しては、「S3 に保存」で指定のS3バケットへ直接保存することもできます。
設定画面下にある「その他の設定」では「音声ファイル形式の設定」と「発音のカスタマイズ」が設定できます。
以下のキャプチャでは内容を確認するため一時的にそれぞれオンの状態にしていますが、今回はこの辺りの設定はオフのままで利用しました。
「その他の設定」の各設定の詳細はこちらの引用とリンク先のドキュメントで確認ください。
音声ファイル形式の設定
ディスクに保存するファイルの種類を指定します。SynthesizeSpeech と StartSpeechSynthesisTask のサンプルレートとファイル形式、スピーチマークとコンソールでのスピーチマークのリクエストの詳細については、ドキュメントを参照してください。
発音のカスタマイズ
レキシコンをアップロードして適用することで、音声を変更できます。これにより、単語、記述された表現、音声合成での使用に適した発音をマッピングします。詳しくは、コンソールを使用したレキシコンの適用に関するドキュメントをご覧ください。
エンジンでの音声の違い
音声の生成エンジンは現在は「スタンダード」と「ニューラル」の2種類を使えます。
ニューラルのエンジンではスタンダードよりもより自然に人間らしい音声を生成できるようですが、どれくらい違うのか、実際に音声を作成してみて比較してみました。
以下のテキストでそれぞれのエンジンで「Takumi (男性)」の音声で生成したファイルがこちらです。
テキストをここに入力して、「音声を聴く」で音声を確認して、問題がなければ「ダウンロード」でmpスリー形式の音声ファイルをダウンロードします。
▼エンジン「スタンダート」で「Takumi (男性)」の音声で生成
▼エンジン「ニューラル」で「Takumi (男性)」の音声で生成
スタンダードだと少し音声にブレがあり違和感を感じる部分がありますが、ニューラルではかなり自然に近い話し方で生成されていることがわかります。
これならいける!!!
と思ったのですが・・・
細かいテキスト調整が必要
今回用意した原稿のテキストをPollyで読み上げていくと、文章によっては漢字などで思ったような読まれ方をしなかったり、文章の区切り方やイントネーションがおかしかったりすることがありました。
実際に使った文章ではありませんが、参考までに今回読み方がおかしかった単語をあわせてサンプルの文章にして読み上げしてみました。
(文章自体が少しおかしいですが、ご了承ください)
セキュリティ対策をしていますか?
SaaSでも利用する企業の方がセキュリティに注意して、一人一人が意識して利用する様にしましょう。
個人情報保護法についても勉強します。
これをPollyで読み上げた音声ファイルが以下になります。
ちょっと想定していない読み方をしています。
「セキュリティ」の最後の長音符がなくて違和感
「SaaS」を「サーズ」と読んでしまう
「企業の方(かた)」を「企業のほう」と読んでしまう
「一人一人」を「ひとりかずと」と読んでしまう
(本来は「一人ひとり」が正しい書き方ではある)「利用する様にしましょう」を「利用するさまにしましょう」と読んでしまう
(助動詞は原則ひらがなをつかって「ように」と書くのがただしい)個人情報保護法のイントネーションがおかしい
これらを踏まえてテキストを以下のように修正して、音声ファイルを生成してみました。
セキュリティー対策をしていますか?
サースでも、利用する企業のかたがセキュリティーに注意して、一人ひとりが意識して利用するようにしましょう。
個人情報の保護についても勉強します。
今度は自然な感じで読んでくれました。
「サースでも利用する企業のかたが〜」の箇所では文章の区切り方が若干おかしかったので「サースでも」の後に読点「、」を入れました。
長めの文章になる場合は、通常書く文章よりも読点「、」を多めに入れて、区切り方を調整するのがコツかもしれません。
「個人情報保護法」は「個人情報の保護法」に一度変更しましたが、「保護法」のイントネーションがまだおかしかったので、「法」は外しました。
このように、テキスト入力して一度聞いてテキストを修正しての調整を繰り返し、自然な感じになったら音声ファイルを生成する作業を、スライド57ページ分も行いました。
ちょっとしんどかった・・・。
この修正してテキストを読み上げる工程が多いと、音声ファイル生成だけでなく調整で「音声を聴く」で読み上げたときも課金されていると思うので、ここに書いた注意点を踏まえてテキストを用意し、調整でのコスト削減できることを願っています(ってそこまで料金は高くはないけどね)。
SSMLでいろいろ調整もできる
Amazon Pollyでは、音声合成マークアップ言語 (SSML) という
HTMLタグみたいなものを使用して、指定したフレーズを強調したり、文章の途中で一時停止を追加したりすることができるようです。
サポートされているタグは以下で確認できますが、ニューラルのエンジンの音声では対応できないタグが多いみたい。
ためしに入力テキストの「SSML」を有効にして、一時停止の<break time=~/>やピッチを修正する<prosody rate=〜>~</prosody>のタグを使って、先ほどの音声に変化をつけてみました。
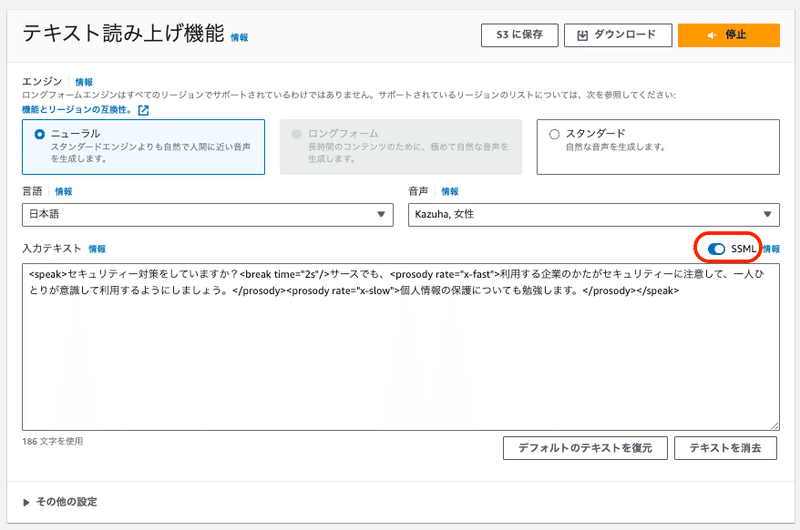
実際に作成したSSMLのテキストは以下のようになります。
SSMLではテキスト全体を<speak>〜</speak>のタグで囲む必要があります。
<speak>
セキュリティー対策をしていますか?<break time="2s"/>
サースでも、<prosody rate="x-fast">利用する企業のかたがセキュリティーに注意して、一人ひとりが意識して利用するようにしましょう。</prosody>
<prosody rate="x-slow">個人情報の保護についても勉強します。</prosody>
</speak>
生成された音声ファイルがこちらです。
SSMLタグに従って一時停止したり、音声のピッチが魔球のように変化することがわかります。
これらのタグを細かく入れていくと、いろいろ面白い(?)読ませ方ができそうですが、今回の研修では使いませんでした・・・。
今回のAmazon Pollyの費用
今回、Googleスライドのスピーカーノート57ページ分のテキストの文字数を計算したところ、合計で約16,659文字でした。
ニューラルエンジンでは100 万文字で16.00 USDなので、単純計算では1文字=0.000016 USDで 16,659文字 × 0.000016 USD = 0.267 USD なのですが、実際には音声を聞いてイントネーションがおかしいところを修正したりを繰り返したので、最終的に 72,992文字の音声変換をしたようで 1.17 USDとなりました。
とはいえ、思ったほど料金はかかりませんでした。
Googleスライドに音声ファイルを挿入
音声ファイルが作成できたら、Googleスライドの各ページに挿入していきます。
①作成した音声ファイルをGoogleドライブにアップロード
Googleスライドで挿入する音声ファイルは、Googleスライドが置かれているGoogleドライブにある音声ファイルから選択する形になります。
ついては、作成した音声ファイルをGoogleドライブの任意の場所にアップロードしておいてください。
音声ファイルは各スライドのページごとに1つずつ音声ファイルを挿入していきますので、音声ファイル名は挿入するスライドのページがわかるようにしておくとよいです。
ただページ番号で名前を付けると、あとでスライドのページ追加があった時に面倒なことになるので、うまく工夫してね。
②Googleスライドで音声ファイルを挿入
次に音声を挿入するGoogleスライドを開き、音声ファイルを指定のページごとに追加していきます。
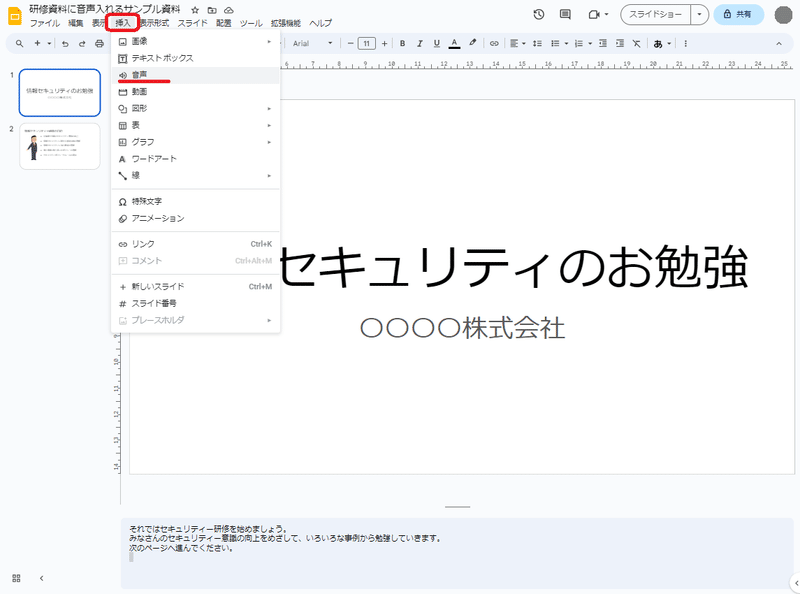
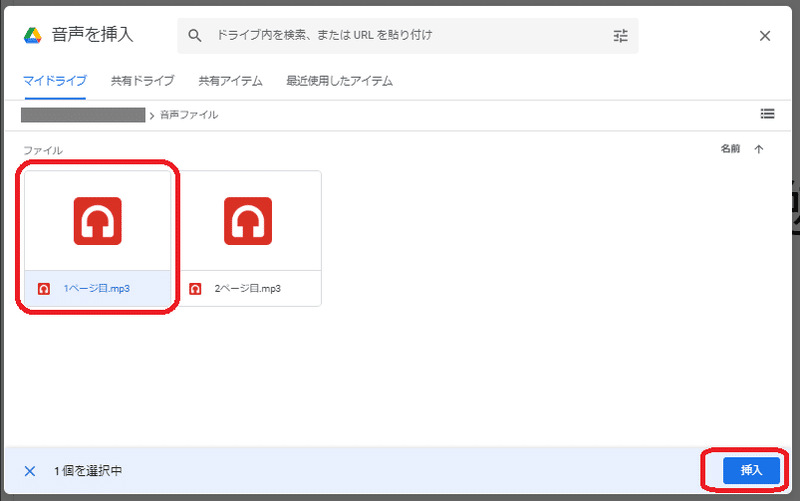
挿入するとスピーカーのアイコンがスライド上に表示されます。
そのアイコンは画面の邪魔にならない位置に移動したりサイズを変更しておき、そのアイコンの書式設定オプションで以下のように設定しておきます。
「再生の開始」は「自動」を選択
「プレゼンテーション中はアイコンを隠す」を選択
「スライド変更時に停止する」を選択
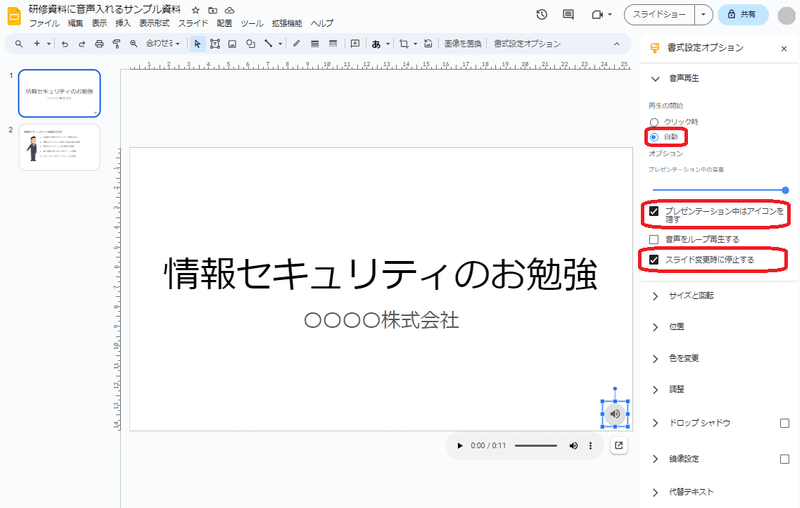
これによりスライドショーでページを表示したときに、それぞれのページで挿入した音声が自動で流れるようになります。
この作業をスライドの各ページごとにおこなってください。
③Googleスライドの共有設定をする
研修資料として社員に提供するには、Googleスライドと音声ファイルを研修対象者が参照できるように共有設定する必要があります。
Googleスライドでは右上の「共有」から設定を行います。
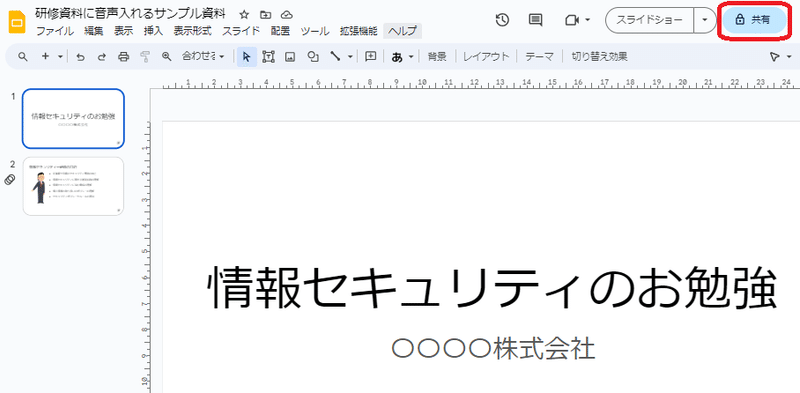
右上の[共有] をクリック
「ユーザーやグループを追加」から共有するメンバーを指定
Google Workspaceを組織で利用して、組織全員に共有する場合は「一般的なアクセス」から所属組織を選択
「リンクを知っている全員」での共有はやめましょう
付与する権限として[編集者]、[閲覧者(コメント可)]、[閲覧者] のいずれかを選択
研修資料として共有するなら[閲覧者]で問題ありません
[編集者]権限を与えると、研修資料を改ざんされる危険性があります
[共有] をクリック
音声ファイルについても同様に共有設定をしてください。
Googleドライブの音声ファイルを右クリックして「共有」メニューから「共有」を選択
「ユーザーやグループを追加」から共有するメンバーを指定
Google Workspaceを組織で利用して、組織全員に共有する場合は「一般的なアクセス」から所属組織を選択
「リンクを知っている全員」での共有はやめましょう
付与する権限として[編集者]、[閲覧者(コメント可)]、[閲覧者] のいずれかを選択
研修資料として共有するなら[閲覧者]で問題ありません
[編集者]権限を与えると、音声ファイルを改ざんされる危険性があります
[共有] をクリック
サンプルでスライドショーを録画してみた
サンプルで作成した研修資料をスライドショーで表示して録画してみました。
2ページ目のスライドでは画像やテキストをモーション機能でスライドインなどさせてみています。
音声で読み上げる原稿やモーションでの動かし方のセンスも問われますが、こんな感じで動画に音声を加えたり動きを加えることで、わかりやすい資料ができそうな予感がします。
もっとリッチな研修資料を作りたい
今回、Googleスプレッドシートのモーション機能も使って、画像をアニメーション表示(文章や画像をスライドインさせたり)しましたが、実際には音声とアニメーションの同期はできず、スライドイン速度などを0.1秒単位で調整して頑張って調整はしてみたものの、PC環境での音声の読み込み速度などの影響で少しずれたりするので、まだまだ改善の余地があります。
もしかするとYouTuberばりに動画編集ソフトで画像とテキストと音声で動画作成したほうがよりリッチにできるかもしれませんが、動画編集の知識があまりないのでなかなか敷居が高い・・・
(TikTokとかで勉強するところから始めます)
そんな中、スライド作成の感覚で、よりリッチな動画とテキストの読み上げを実現してくれそうなサービスがあるようです。
こちらのサービス、説明したいテキストをサービスに入力するだけでAIアバターが表情や口の動きなど自然にしゃべっているように説明してくれる動画を簡単に作成ができます。
また、Googleスライドのように文字や画像を使ったスライドなども作成できて、それらをアニメーションで動かしながら、AIアバターがワイプで説明するようなものも簡単につくれるようです。
日本国内の企業でも導入事例があるようで、HENNGEさんの決算説明動画でも使っているようです。
アバターも実際に社長本人がしゃべった3分ほどの動画から、社長アバターを作成させたようです。
(音声は別のサービスで生成したものっぽいですが)
SynthesiaでサンプルAI動画を作ってみた
実際にどんな感じでAIアバターがしゃべる動画ができるのか、お試しで作成できるみたいなので作成してみました。
「Synthesia」のトップページから、以下の手順でサンプル動画を作成してみました。
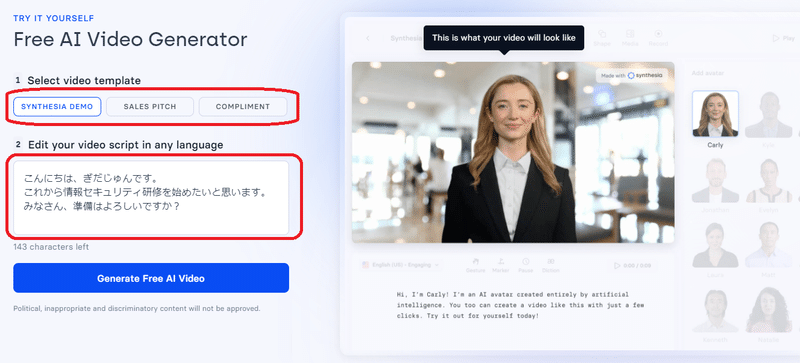
③「Edit your video script in any language」で読み上げるテキストを入力
⓸「Generate Free AI Video」ボタンを押す
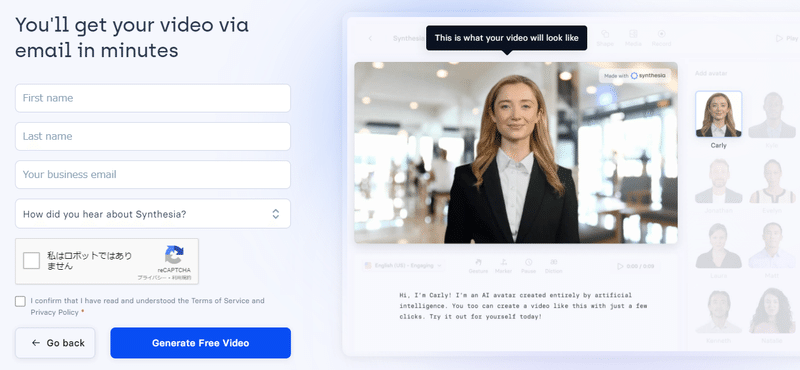
(gmailなどのフリーのメールアドレスはNGっぽい)
⑥そのほか任意の選択やチェックボックスをチェックする
⑦「Generate Free Video」ボタンを押す
「Generate Free Video」ボタンを押すと、登録したメールアドレス宛に「Your AI video? We’re on it.」のタイトルでメールが届きます。
メール本文には「Once your video is approved, you'll receive it within 5-10 minutes.(動画が承認されると、5 ~ 10 分以内に動画が届きます)」と書かれているので、少し待ちます。
サービス側で動画が承認され作成が完了すると、新たに「Your AI video is now ready」のタイトルでメールが届きます。
メール本文にある「Watch your AI Video」をクリックすると、Webブラウザ上で作成された動画をみることができます。
作成したサンプルAI動画はこちら
以下は私が作成してみたAI動画です。
「ぎだじゅん」のイントネーションが若干気にはなるのと、少し口の動きに違和感はありますが、なかなかいい感じじゃないですか!!
気になるプライスはこちら。
使えるアバター数(Starterが70、Creatorが360)やビデオにコメントできるゲスト数(Starterが3guests、Creatorが5guests)、1年間で作成できる動画の分数制限(Starterが120分/年、Creatorが360分/年)によって違うようです。
最後に
今回、音声を追加したスライドで研修資料を作ったお話でした。
自分がYouTuberばりに動画編集ができれば、もっと楽しい研修資料(動画)を作れるのですが、その前にもっと本業(プロダクトのセキュリティ運用)を頑張らないといけないので、今はここまでが限界です。
Googleさんがスライドのスピーカーノートを自動で読み上げる機能ができることを願っています。
そして、忘年会や新年会シーズンなので、皆さんもインシュ(飲酒)デントには気を付けましょう!
最後まで見ていただきありがとうございます。
よいお年をお迎えください!

来年もがんばって投稿ノルマを達成します!
こんなネタ投稿も許してくれる今の会社はとてもいい会社なので、興味のある方はこちらも是非見てみてください。
あと、気軽にご参加いただけるカジュアルなイベントもたまに実施しています。開催予定のイベントは以下のconnpass のグループで発信していますので、興味のあるイベントがあれば、ぜひ参加してみてください。
この記事が気に入ったらサポートをしてみませんか?