
「Pythonによる異常検知」を寄り道写経 ~ 第1章1.4節「教師なし学習-特徴抽出・クラスタリング・次元削減」

第1章「機械学習と統計解析の基本モデル」
書籍の著者 曽我部東馬 先生、監修 曽我部完 先生
この記事は、テキスト「Pythonによる異常検知」第1章「機械学習と統計解析の基本モデル」1.4節「教師なし学習-特徴抽出・クラスタリング・次元削減」の通称「寄り道写経」を取り扱います。
今回は機械学習の一分野「教師なし学習」を寄り道写経します!
テキストは「異常検知と機械学習の誤差関数の関係」を重視して、異常検知に入る前に機械学習・統計解析そのものと誤差関数を学びます。
ではテキストを開いて教師なし学習の旅に出発です🚀

はじめに
テキスト「Pythonによる異常検知」のご紹介
このシリーズは書籍「Pythonによる異常検知」(オーム社、「テキスト」と呼びます)の寄り道写経です。
テキストは、2021年2月に発売され、機械学習等の誤差関数から異常検知を解明して、異常検知に関する実践的なPythonコードを提供する素晴らしい書籍です。
とにかく「誤差関数」と「異常度」の強い結びつきを堪能できる1冊です。
引用表記
この記事は、出典に記載の書籍に掲載された文章及びコードを引用し、適宜、掲載文章とコードを改変して書いています。
【出典】
「Pythonによる異常検知」第1版第6刷、著者 曽我部東馬、監修者 曽我部完、オーム社
記事中のイラストは、「かわいいフリー素材集いらすとや」さんのイラストをお借りしています。
ありがとうございます!
1.4 教師なし学習-特徴抽出・クラスタリング・次元削減
主に Jupyter Notebook 形式(拡張子 .ipynb)でPythonコードを書きます。
今回の寄り道ポイントは次の2点です。
基本的に、あやめデータセットを用いて教師なし学習に取り組みます。
主成分分析、t-SNE、SOM、K-means、EM法を scikit-learn などの既存ライブラリを用いて実践します。

この記事で用いるライブラリをインポートします。
### インポート
# 数値計算
import numpy as np
import pandas as pd
# アヤメデータセット
from sklearn import datasets
# 機械学習
from sklearn.decomposition import PCA # PCA
from sklearn.manifold import TSNE # TSNE
import somoclu # SOM
from sklearn.cluster import KMeans # KMeans
from sklearn.mixture import GaussianMixture # EM法
# 描画
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.family'] = 'Meiryo'
# ワーニング表示の抑制
import warnings
warnings.simplefilter('ignore')
あやめデータセットの読み込み
scikit-learn のデータセットより、あやめデータセットを取得します。
4つの説明変数でデータフレーム df を作成します。
目的変数は target、あやめの名前は target_names に格納します。
### データの読み込み
# scikit-learnのdatasetsよりアヤメデータを取得
# データセットの読み込み
iris = datasets.load_iris()
# あやめの種類(正解値)と名前を取得
target = iris.target
target_names = iris.target_names.tolist()
# 説明変数:がく片の長さ・幅、花びらの長さ・幅をデータフレーム化
columns = [s.replace(' ', '_').replace('_(cm)', '') for s in iris.feature_names]
df = pd.DataFrame(iris.data, columns=columns)
print('df.shape:', df.shape)
display(df.head())【実行結果】

テキストオリジナルコードは、中心化や最大値で除するなどのデータ加工をしますが、この記事はあやめデータセットのオリジナルのまま使用することにします。
散布図を見てみましょう。
がく片の長さと幅です。
### データの可視化1 がく片の長さと幅
# 描画領域の設定
fig, ax = plt.subplots(figsize=(6, 4))
# アヤメ種類別の散布図の描画
sns.scatterplot(data=df, x='sepal_length', y='sepal_width',
hue=target, palette=['tab:blue', 'orange', 'tab:green'],
edgecolor='powderblue', alpha=0.7,
size=target, sizes=[80, 80, 70],
style=target, markers=['^', 's', 'o'], ax=ax)
# 凡例
handles, _ = ax.get_legend_handles_labels()
plt.legend(handles=handles, labels=target_names, title='アヤメの種類')
# 修飾
plt.grid(lw=0.5);【実行結果】
setosaはくっきり分かれています。
versicolorとvirginiaはすこし混ざっています。

次は花びらの長さと大きさです。
### データの可視化2 花びらの長さと幅 ★テキストのコードを改変
# 描画領域の設定
fig, ax = plt.subplots(figsize=(6, 4))
# アヤメ種類別の散布図の描画
sns.scatterplot(data=df, x='petal_length', y='petal_width',
hue=target, palette=['tab:blue', 'orange', 'tab:green'],
edgecolor='powderblue', alpha=0.7,
size=target, sizes=[80, 80, 70],
style=target, markers=['^', 's', 'o'], ax=ax)
# 凡例
handles, _ = ax.get_legend_handles_labels()
plt.legend(handles=handles, labels=target_names, title='アヤメの種類')
# 修飾
plt.grid(lw=0.5);【実行結果】
かなり綺麗に分かれている感じがします。


主成分分析による次元削減
1.4.2節からの派生です。
scikit-learn の PCA を用いて主成分分析を実行し、次元削減後の可視化に取り組みます。
主成分分析を実行します。
ひとまず主成分数は4つ全部で実行します。
### PCAの実行 scikit-learnのPCA ★寄り道写経コード
# PCAの実行, 主成分得点の算出
pca = PCA()
score = pca.fit_transform(df)
# loading行列の取得
loadings = pca.components_
# 固有値の取得
eig_val = pca.explained_variance_
# 寄与率の取得
exp_ratio = pca.explained_variance_ratio_
# 結果表示
print('loadings行列(固有ベクトル):')
print(loadings)
print('\n固有値:')
print(eig_val)
print('\n寄与率:')
print(exp_ratio)
print('\n主成分得点:')
print(score[:5, :], '…')【実行結果】

累積寄与率を確認して、次元削減の状況を見てみましょう。
### 累積寄与率の描画
# x軸の値の設定
xticks = range(len(exp_ratio) + 1)
# 描画領域の設定
fig, ax = plt.subplots(figsize=(6, 3))
# 寄与率をcumsumで累積にして折れ線グラフを描画
ax.plot(xticks, np.hstack([0, exp_ratio]).cumsum(), '-o')
# 80%ラインの赤い水平線の描画
ax.axhline(0.8, color='tomato', ls='--')
# 修飾
ax.set(xlabel='主成分', ylabel='累積寄与率', ylim=(-0.1, 1.1), xticks=xticks)
plt.grid(lw=0.5);【実行結果】
第1主成分で寄与率が90%を超えています。
いい感じに次元削減できたと思います!

次元削減の良し悪しを可視化で確認します。
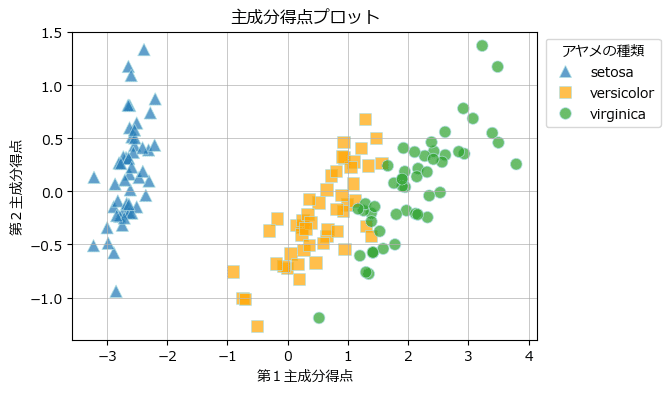
第1主成分と第2主成分の主成分得点の散布図を描画します。
### 主成分得点の描画
# 描画領域の設定
fig, ax = plt.subplots(figsize=(6, 4))
# アヤメ種類別の散布図の描画
sns.scatterplot(x=score[:, 0], y=score[:, 1],
hue=target, palette=['tab:blue', 'orange', 'tab:green'],
edgecolor='powderblue', alpha=0.7,
size=target, sizes=[80, 80, 70],
style=target, markers=['^', 's', 'o'], ax=ax)
# 凡例
handles, _ = ax.get_legend_handles_labels()
ax.legend(title='アヤメの種類', handles=handles, labels=target_names,
bbox_to_anchor=(1.28, 1))
# 修飾
ax.set(xlabel='第1主成分得点', ylabel='第2主成分得点', title='主成分得点プロット')
plt.grid(lw=0.5);【実行結果】
3種類のあやめをいい感じに区別できるような次元削減になったと思います。
PCAで得られるLoading行列(たぶん固有ベクトル)を描画します。
### Loading行列の描画
# Loading行列のデータフレーム化
loadings_df = pd.DataFrame(loadings.T, index=df.columns,
columns=[f'PC{i+1}'for i in range(len(loadings))])
# 描画領域の設定
fig, ax = plt.subplots(figsize=(6, 4))
# 散布図の描画 by pandas plot
loadings_df.plot.scatter(x='PC1', y='PC2', s=80, ax=ax)
# データ点に変数名を付記
for i, v in enumerate(loadings_df.index):
ax.annotate(text=v, xy=loadings_df.iloc[i, :2] + 0.05)
# 修飾
plt.axhline(0, color='black', lw=0.5, ls='--')
plt.axvline(0, color='black', lw=0.5, ls='--')
ax.set(xlim=(-1.5, 1.5), ylim=(-1.5, 1.5), title='Loadings行列: 主成分と変数');【実行結果】
がく片(sepal)のペア同士、花びら(petal)のペア同士がそれぞれ近いです。
直感に合っていると思います。


t-SNEによる次元削減
1.4.4節からの派生です。
scikit-learn の TSNE を用いて次元削減を実行し、次元削減後の可視化に取り組みます。
4次元のあやめデータセットを t-SNEで2次元に次元削減します。
### scikit-learnのt-SNE
# TSNEインスタンスの生成 2次元に次元削減する
tsne = TSNE(n_components=2, perplexity=7, random_state=0)
# TSNEの学習
tsne_res = tsne.fit_transform(df)
# 次元削減結果の一部を表示
tsne_res[:10, :]【実行結果】

次元削減後の2次元データを可視化します。
### t-SNEのresultを描画
# resultの散布図の描画
fig, ax = plt.subplots(figsize=(6, 4))
sns.scatterplot(x=tsne_res[:, 0], y=tsne_res[:, 1],
hue=target, palette=['tab:blue', 'orange', 'tab:green'],
size=target, sizes=[80, 70, 60],
style=target, markers=['^', 's', 'o'], ax=ax)
# 修飾
handles, _ = ax.get_legend_handles_labels()
ax.legend(title='アヤメの種類', handles=handles, labels=target_names,
bbox_to_anchor=(1.28, 1))
ax.grid(lw=0.5);【実行結果】
setosaの識別力は抜群ですね!
versicolorとvirginicaは若干入り混じっていますが、概ね識別できている感じもします。

ここまでの次元削減では、t-SNEのperplexity引数に7を設定しています。
perplexity引数にさまざまな値を設定して、次元削減後のデータの識別力を確認してみましょう。
perplexity引数を指定してt-SNEを実行し、散布図を描画する関数を定義します。
### t-SNEのパラメータperplexityを変える
def plot_tsne(perplexity):
# t-SNEの実行
tsne = TSNE(n_components=2, perplexity=perplexity, random_state=0)
tsne_res = tsne.fit_transform(df)
# resultの散布図の描画
fig, ax = plt.subplots(figsize=(6, 4))
sns.scatterplot(x=tsne_res[:, 0], y=tsne_res[:, 1],
hue=target, palette=['tab:blue', 'orange', 'tab:green'],
size=target, sizes=[80, 70, 60],
style=target, markers=['^', 's', 'o'], ax=ax)
# 修飾
handles, _ = ax.get_legend_handles_labels()
ax.legend(title='アヤメの種類', handles=handles, labels=target_names,
bbox_to_anchor=(1.28, 1))
ax.set_title(f'perplexity={perplexity}')
ax.grid(lw=0.5)
plt.show()perplexity引数を2から2ずつ増やしてみましょう。
# TSNEの実行・可視化 perplexity=2
perplexity = 2
plot_tsne(perplexity)【実行結果】
S字くねくねしています。
まだ識別途中な感じです。

# TSNEの実行・可視化 perplexity=4
perplexity = 4
plot_tsne(perplexity)【実行結果】
かなり識別できてきました。

# TSNEの実行・可視化 perplexity=6
perplexity = 6
plot_tsne(perplexity)【実行結果】
setosa VS versicolor・virginica連合の対決になっています。

# TSNEの実行・可視化 perplexity=8
perplexity = 8
plot_tsne(perplexity)【実行結果】
世界地図のような位置取りですね!

# TSNEの実行・可視化 perplexity=10
perplexity = 10
plot_tsne(perplexity)【実行結果】
ほぼ似た構図が続きます。

# TSNEの実行・可視化 perplexity=12
perplexity = 14
plot_tsne(perplexity)【実行結果】
ほぼ似た構図が続きます。

終わりです。

この先はクラスタリング手法に移ります。
テキストは「次元削減とクラスタリングは等価である」との考えのもと、以降のクラスタリング手法によるクラスタリングを次元削減と呼びます。
「データ点の1つ1つが特徴数=次元数」であり「クラスタリングでクラスタを識別することでクラスタ数=特徴数=次元数」となるから、クラスタリングは次元削減と等価である、ということです。
詳細はテキストの60~62ページでご確認ください。

自己組織化マップ(SOM)による次元削減
1.4.5節②からの派生です。
WEB検索で見つけた somoclu ライブラリを使います。
が・・・、使い方があまり分かっておりません。
ひとまずSOMによる可視化に向かいます。
SOMの学習です。
initialization='pca' (主成分分析で初期化)を設定したのは、処理結果がランダムに変わらないようにしたいからです。
initializationのデフォルト値は「ランダム」です。
### somocluでSOM ※実のところ良く分かっていない・・・
# 参考サイト https://k-kuro.hatenadiary.jp/entry/20220225/1645762786
# https://qiita.com/kimisyo/items/97d3e7b8938984ac5bd4
# https://hayataka2049.hatenablog.jp/entry/2018/04/07/161249
# https://somoclu.readthedocs.io/en/stable/index.html
# SOMの学習
n_rows, n_columns = 75, 75
som = somoclu.Somoclu(n_rows=n_rows, n_columns=n_columns, compactsupport=False,
initialization='pca')
%time som.train(df.values)【実行結果】
行数75, 列数75では処理時間がかなり短いです。
行数・列数を増やすと処理時間増となります。

自己組織化コードブック内のコンポーネント面の可視化をします。
(somoclu 公式の英語をgoogle翻訳した文章です)
### 自己組織化コードブック内のコンポーネント面の可視化
som.view_component_planes(figsize=(3, 3))【実行結果】
徐々に色面の区別がはっきりして、境界が生み出されている感じです。




最後の図の色面分割を頭の片隅に置いておきましょう。
続いて学習済みMAPのU行列の可視化です。
(google翻訳以下同文)
点の色はあやめの種類の正解値です。
### 学習済みMAPのU行列の可視化
# データ点の色の設定 青:setosa, 赤:versicolor、緑:virginica
colors = ['royalblue'] * 50 + ['orangered'] * 50 + ['seagreen'] * 50
# 可視化
som.view_umatrix(bestmatches=True, bestmatchcolors=colors, colormap='Oranges',
figsize=(5, 5))【実行結果】
3種類のあやめを上・中・下の各領域に分類できている感じがします。

以上です。
(続きをどうしていいのか分からない・・・)

K-meansによる次元削減
1.4.5節③からの派生です。
scikit-learn の KMeans を用いてクラスタリング(次元削減と等価)を実行し、クラスタリングの可視化に取り組みます。
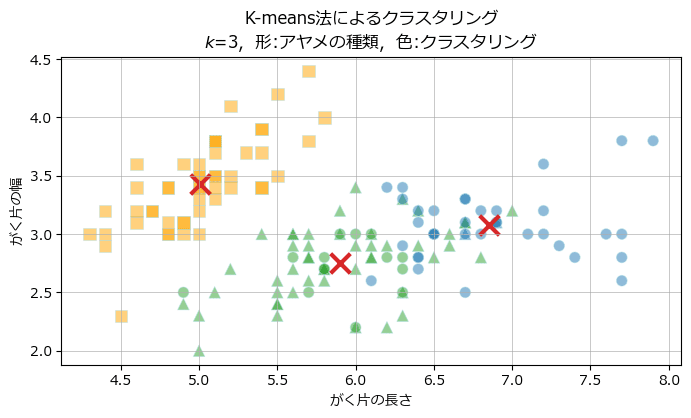
データ点150個のあやめデータセットをクラスタ数$${k=3}$$と$${k=2}$$にしてクラスタリングを行ってみます。
まずは$${k=3}$$です。
### scikit-learnのK-means法
# K-means法の実行
kmeans = KMeans(n_clusters=3, max_iter=1000, random_state=123).fit(df)
# クラスタ中心点の取得
centroids = kmeans.cluster_centers_
# データのクラスタラベルの取得
label_kmeans = kmeans.labels_クラスタリング結果を可視化します。
### クラスタリングの描画
# 描画用の設定
colors = ['tab:blue', 'orange', 'tab:green']
markers = ['s', '^', 'o']
# 描画領域の設定
fig, ax = plt.subplots(figsize=(8, 4))
# データ点の散布図の描画 形:正解ラベル、色:K-meansのクラスタリング
sns.scatterplot(x=df['sepal_length'], y=df['sepal_width'],
# K-meansのクラスタリングラベルで色分け
hue=label_kmeans, palette=colors,
edgecolor='powderblue', alpha=0.5,
# アヤメの種類(正解ラベル)で形付け
style=target, markers=markers,
size=target, sizes=[80, 70, 60], ax=ax, legend=False)
# クラスタ中心点の描画
sns.scatterplot(x=centroids[:, 0], y=centroids[:, 1], marker='x', s=200, lw=3,
color='tab:red', ax=ax, legend=False)
# 修飾
ax.set(xlabel='がく片の長さ', ylabel='がく片の幅',
title='K-means法によるクラスタリング\n'
f'$k$={kmeans.n_clusters}, 形:アヤメの種類, 色:クラスタリング')
plt.grid(lw=0.5);【実行結果】
×印はクラスタ中心点です。
setosa(四角)はオレン色のクラスタリングがうまく行っている感じです。
versicolor(三角)・virginia(丸)はクラスタリングの色が少々入り混じる様相です。
続いて$${k=2}$$です。
### scikit-learnのK-means法
# K-means法の実行
kmeans = KMeans(n_clusters=2, max_iter=1000, random_state=123).fit(df)
# クラスタ中心点の取得
centroids = kmeans.cluster_centers_
# データのクラスタラベルの取得
label_kmeans = kmeans.labels_可視化します。
### クラスタリングの描画 ★寄り道写経コード
# 描画用の設定
colors = ['tab:blue', 'orange', 'tab:green']
markers = ['s', '^', 'o']
# 描画領域の設定
fig, ax = plt.subplots(figsize=(8, 4))
# データ点の散布図の描画 形:正解ラベル、色:K-meansのクラスタリング
sns.scatterplot(x=df['sepal_length'], y=df['sepal_width'],
# K-meansのクラスタリングラベルで色分け
hue=label_kmeans, palette=colors,
edgecolor='powderblue', alpha=0.5,
# アヤメの種類(正解ラベル)で形付け
style=target, markers=markers,
size=target, sizes=[80, 70, 60], ax=ax, legend=False)
# クラスタ中心点の描画
sns.scatterplot(x=centroids[:, 0], y=centroids[:, 1], marker='x', s=200, lw=3,
color='tab:red', ax=ax, legend=False)
# 修飾
ax.set(xlabel='がく片の長さ', ylabel='がく片の幅',
title='K-means法によるクラスタリング\n'
f'$k$={kmeans.n_clusters}, 形:アヤメの種類, 色:クラスタリング')
plt.grid(lw=0.5);【実行結果】
ほぼversicolor(三角)・virginia(丸)が1つのクラスタを形成した模様です。


EM法による次元削減
EM法は Expectation-maximization algorithm のことです。
テキストによると「最大のポイントは重み$${w_i}$$が正規分布をもつ確率分布であると仮定すること」です。
scikit-learn の GaussianMixture を用いてクラスタリング(次元削減と等価)を実行し、クラスタリングの可視化に取り組みます。
最初にテキストとほぼ同じ方法で生成した乱数のクラスタリングに取り組みます。
次にあやめデータセットのクラスタリングに取り組みます。
1.テキストと同様のデータセット
データを作成します。
### データの作成 ★テキストのコードを引用
rng = np.random.default_rng(seed=1234)
x1 = rng.standard_normal(size=(100, 2)) + np.array([-5, 5])
x2 = rng.standard_normal(size=(100, 2)) + np.array([5, -5])
x3 = rng.standard_normal(size=(100, 2))
inputs = np.vstack((x1, x2, x3))クラスタリングを実行します。
クラスタ数は3です。
### scikit-learnのGaussianMixture
## 設定:クラスタの数
n_components = 3
## GaussianMixtureの実行
# モデルのインスタンス生成と学習の実行
gmm = GaussianMixture(n_components=n_components, random_state=1234).fit(inputs)
# クラスタ中心点(平均値)の取得
gmm_mean = gmm.means_
# 学習データのクラスタリングラベルの取得
label_gmm = gmm.predict(inputs)可視化します。
### クラスタリングの描画
## 等高線図用データの作成
# x,y軸の値の設定
x = y = np.linspace(-10, 10, 101)
X, Y = np.meshgrid(x, y)
XY = np.array([X.ravel(), Y.ravel()]).T
# z軸:対数尤度xマイナスの算出
Z = gmm.score_samples(XY) * -1
Z = Z.reshape(X.shape)
## 描画処理
# 描画領域の設定
fig, ax = plt.subplots(figsize=(6, 4))
# データ点の散布図の描画 クラスタリングラベルで色・形付け
sns.scatterplot(x=inputs[:, 0], y=inputs[:, 1],
hue=label_gmm, palette='tab10', edgecolor='white', alpha=0.5,
style=label_gmm, size=label_gmm, sizes=[80] * (n_components),
ax=ax, legend=False)
# 等高線図の描画
ax.contour(X, Y, Z, vmin=-3, vmax=10, levels=np.linspace(0, 10, 10),
cmap='Reds_r', linewidths=0.9)
# クラスタ中心点の描画
sns.scatterplot(x=gmm_mean[:, 0], y=gmm_mean[:, 1], marker='x', s=100, lw=3,
color='tab:red', ax=ax, legend=False)
ax.set(title='GaussianMixtureによるクラスタリング', xlim=(-10, 10), ylim=(-10, 10))
plt.grid(lw=0.5);【実行結果】
正規分布に従う3つの集団に的中するようにクラスタ中心点の×印がツイています。
等高線もデータの分布をうまく捉えているように感じます。

2.あやめデータセット
花びらの長さと幅を用いてクラスタリングに取り組みます。
クラスタリングを実行します。
クラスタ数は3です。
### scikit-learnのGaussianMixture
## 設定:クラスタの数
n_components = 3
## 説明変数を2個に絞る
data = df[['petal_length', 'petal_width']]
## GaussianMixtureの実行
# モデルのインスタンス生成と学習の実行
gmm = GaussianMixture(n_components=n_components, random_state=1234).fit(data)
# クラスタ中心点(平均値)の取得
gmm_mean = gmm.means_
# 学習データのクラスタリングラベルの取得
label_gmm = gmm.predict(data)可視化します。
### クラスタリングの描画
## 等高線図用データの作成
# x,y軸の値の設定
x = y = np.linspace(-10, 10, 101)
X, Y = np.meshgrid(x, y)
XY = np.array([X.ravel(), Y.ravel()]).T
# z軸:対数尤度xマイナスの算出
Z = gmm.score_samples(XY) * -1
Z = Z.reshape(X.shape)
## 描画処理
# 描画領域の設定
fig, ax = plt.subplots(figsize=(6, 4))
# データ点の散布図の描画 クラスタリングラベルで色・形付け
sns.scatterplot(x=data['petal_length'], y=data['petal_width'],
hue=label_gmm, palette='tab10', edgecolor='white', alpha=0.5,
style=label_gmm, size=label_gmm, sizes=[80] * (n_components),
ax=ax, legend=False)
# 等高線図の描画
ax.contour(X, Y, Z, vmin=-3, vmax=10, levels=np.linspace(0, 10, 10),
cmap='Reds_r', linewidths=0.9)
# クラスタ中心点の描画
sns.scatterplot(x=gmm_mean[:, 0], y=gmm_mean[:, 1], marker='x', s=100, lw=3,
color='tab:red', ax=ax, legend=False)
ax.set(title='GaussianMixtureによるクラスタリング',
xlim=(0.2, 8), ylim=(-0.5, 3.5))
plt.grid(lw=0.5);【実行結果】
なんと!3つの種類をうまく捉えているように感じます!

今回の寄り道写経は以上です。

シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?