
12章 CelebAデータセットを取得できない!!

はじめに
シリーズ「Python機械学習プログラミング」の紹介
本シリーズは書籍「Python機械学習プログラミング PyTorch & scikit-learn編」(初版第1刷)に関する記事を取り扱います。
この書籍のよいところは、Pythonのコードを動かしたり、アルゴリズムの説明を読み、ときに数式を確認して、包括的に機械学習を学ぶことができることです。
Pythonで機械学習を学びたい方におすすめです!
この記事では、この書籍のことを「テキスト」と呼びます。
記事の内容
この記事は「第12章 ニューラルネットワークの訓練をPyTorchで並列化する」で利用するCelebAデータセットがダウンロードできない問題の対処方法を取り上げています。
具体的には、以下の点を紹介します。
CelebAデータセットの概要
CelebAデータセット取得エラーの内容
エラー対処方法
CelebAデータセットの読み込み処理の変更
12章のダイジェスト
12章からPyTorchにチャレンジします。
PyTorchはディープラーニングツールです。いよいよ機械学習の核心に近づいてまいりました!
まずはPyTorchをインストールして、PyTorch特有のデータ型であるテンソル(torch.Tensor)の簡単な操作を行います。
次に、torchvision.datasetsライブラリの画像データセットを操作する練習を行います。
さらには、ニューラルネットワークモジュール「torch.nn」を用いてディープラーニングアーキテクチャに触れたり、活性化関数の選択に関する話題を検討します。
CelebAデータセットをダウンロードして使えるようにする
CelebAデータセットの概要
「CelebA」データセットは、torchvision.datasets ライブラリから取得できる画像データと属性データから構成されるデータ一式です。
何の画像データかというと...。
これです。
20 万を超える有名人の画像を含む大規模な顔属性データセットで、それぞれに40の属性の注釈情報が付いています。
有名人の顔の画像データなのです。
20万を超える大量の画像データを torchvision.datasets.CelebA クラスを用いてダウンロードして、所定のフォルダに格納するのが、テキストの以下のコードです。
# テキストからの引用
# torchvisionをインポートして、CelebAデータセットをダウンロードし
# torch.utils.data.Datasetオブジェクトに読み込む
import torchvision
image_path = './'
celeba_dataset = torchvision.datasets.CelebA(image_path, split='train',
target_type='attr', download=True)しかし、運が悪いことに、このコードを実行後、すぐにエラーが発生しました。。。
CelebAデータセット取得エラーの内容
エラーメッセージは以下のとおりです。

RuntimeError: The daily quota of the file img_align_celeba.zip is exceeded and it can't be downloaded. This is a limitation of Google Drive and can only be overcome by trying again later.
ファイルimg_align_celeba.zipの1日のクォータを超えているため、ダウンロードすることができません。これはGoogleドライブの制限であり、後で再試行することによってのみ克服することができます。
1日のダウンロード上限を超えたためにダウンロードできない、ということのようです。つまり、Pythonコードの変更では対処できないエラー。
実は、テキストもこのエラー発生を予測しており、対処方法を記載しています。
Google Driveには1日あたりのクォータの上限があり、このエラーはその上限を超えてしまったという意味である。このような問題が起こった場合は、CelebAデータセットの公式Webサイトから直接ファイルをダウンロードするか、Google Driveのダウンロードリンクを使うことができる。
(ただしURLの記載は省略)
この記載に続いて、テキストにはファイルのダウンロードの方法と、ローカルディスクのダウンロードデータの配置の方法が記載されているのですが、解釈が難しくて、「ん?」と思考が止まりました。
どうすればよいのか、わかりにくい・・・。
ネットを調べて、かなり苦戦して試行錯誤を繰り返しながら、ようやく対処完了にたどり着くことができました。
エラー対処方法を詳しく見ていきましょう。
エラー対処方法
大まかに次のステップを踏みます。
ローカルディスクにデータをダウンロードする。
画像ファイルを解凍する。
ローカルディスクの適切なフォルダに配置する。
細かく見ていきましょう。
1.ローカルディスクにデータをダウンロードする。
CelebA公式Webサイトから必要データをダウンロードします。
公式サイトはこちら
サイト中段の「Downloads」のアイコンをクリックして、ファイルが格納されているGoogle Driveを開きます。
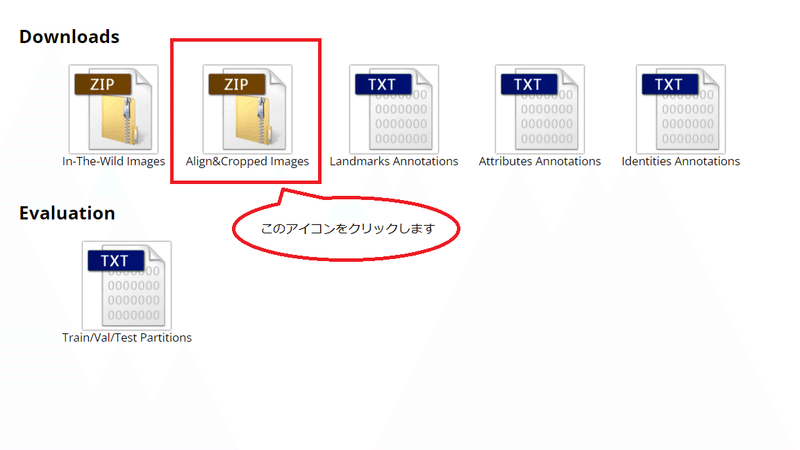
Google DriveのCelebAフォルダが開きます。

このフォルダから以下のファイルをダウンロードします。
なお、「img_align_celeba.zip」はファイルサイズが 1.34GB と大容量であり、ダウンロードに時間がかかるのでご注意下さい。
■ Annoフォルダ
- identity_CelebA.txt
- list_attr_celeba.txt
- list_bbox_celeba.txt
- list_landmarks_align_celeba.txt
- list_landmarks_celeba.txt
■ Evalフォルダ
- list_eval_partition.txt
■ Imgフォルダ
- img_align_celeba.zip
ダウンロードファイルを格納するフォルダは、以下をおすすめします。
フォルダの様子は「3.ローカルディスクの適切なフォルダに配置する。」を参考にしてください。
■ Annoフォルダのファイル
→ 作業フォルダの直下の「celeba」フォルダ
■ Evalフォルダのファイル
→ 作業フォルダの直下の「celeba」フォルダ
■ Imgフォルダのファイル
→ 作業フォルダ
Google Driveのファイルをダウンロードする方法を「img_align_celeba.zip」を例にして図示します。
Imgフォルダをダブルクリックします。

img_align_celeba.zipを右クリックします。
メニューの「ダウンロード」をクリックします。
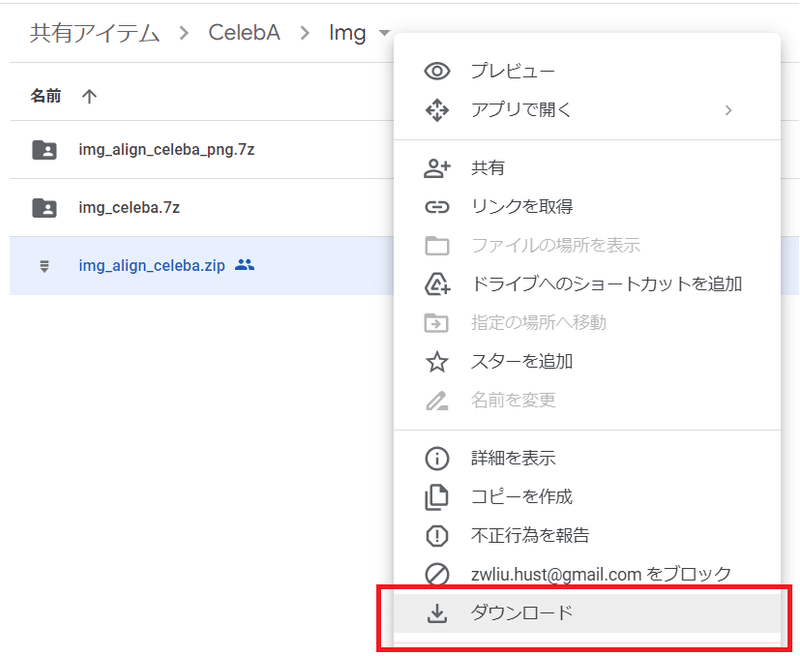
「エラーを無視してダウンロード」をクリックします。
※ウィルスの心配な方は、ここで作業を中断してダウンロードを断念してください。

ダウンロード先のフォルダを指定して「保存」ボタンをクリックします。
※ファイル名を変更しないように注意しましょう。

2.画像ファイルを解凍する。
「img_align_celeba.zip」を解凍します。
20万以上の画像ファイルを展開しますので、処理にかなりの時間がかかります。
解凍先のフォルダは、作業フォルダの直下の「celeba」フォルダです。
フォルダ付きで解凍してください。
「img_align_celeba」フォルダの配下に画像ファイルが解凍されることになります。
解凍後のフォルダの様子は「3.ローカルディスクの適切なフォルダに配置する。」を参考にしてください。
3.ローカルディスクの適切なフォルダに配置する。
「celeba」フォルダの配下に、以下のとおりファイルが格納されるようにしてください。

「celeba」フォルダの直下の「img_align_celeba」フォルダに、画像ファイルが格納されるようにしてください。

さあ、これでCelebAデータセットを読み込む準備が整いました!
CelebAデータセットの読み込み処理の変更
データが整いましたので、エラーで止まってしまった処理を続行しましょう。
2点の注意事項があります。
1つ目は、image_path の設定です。
「celeba」フォルダの1つ上のフォルダを指定して下さい。
サンプルコードでは、作業フォルダの下に「celeba」フォルダを配置したことを前提にして、
> image_path = './'
としております。
2つ目は、download パラメータの設定です。
ダウンロードは不要ですので、Falseを指定します。
> download=False
コード例を添えておきます。
内容は、ほぼテキストの引用となっています。
# 変更後のコード
# image_pathにはcelebaフォルダの1つ上のフォルダを指定します
# downloadにはFalseを指定します
import torchvision
image_path = './' # ''の中のフォルダ名を適宜変更してください
celeba_dataset = torchvision.datasets.CelebA(image_path, split='train',
target_type='attr', download=False)CelebAデータセットの読み込み処理の完了後、テキストを進めていきますと、サンプル画像と笑顔かどうかのラベルを表示するコードにたどり着きます。
「図12-4 18個のサンプル画像と 'Smiling' ラベルの値」の部分です。
テキストでは最初の18個の画像を表示しています。
では、100000番目から18枚の画像ではどうでしょう?
試してみました。

@inproceedings{liu2015faceattributes,
title = {Deep Learning Face Attributes in the Wild},
author = {Liu, Ziwei and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou},
booktitle = {Proceedings of International Conference on Computer Vision (ICCV)},
month = {December},
year = {2015}
}
サンプルコードを添えておきます。
テキストのコードを改造しました。
start で表示開始番号を指定します。
100000番目から開始するのは、処理にそこそこ時間がかかりました。。。
# 100000番目から18枚の画像と笑顔かどうかのクラスラベルの表示
# import matplotlib.pyplot as plt
from itertools import islice
start = 100000 # 何番目の画像から開始するかを指定
fig = plt.figure(figsize=(12, 8))
for i, (image, attributes) in islice(enumerate(celeba_dataset), start, start+18):
ax = fig.add_subplot(3, 6, i+1-start)
ax.set_xticks([])
ax.set_yticks([])
ax.imshow(image)
smile = 'Smile!' if attributes[31] == 1 else ''
ax.set_title(f'{smile}', size=15)
plt.show()まとめ
今回は、PyTorchが取り扱うデータセットの取得で発生したエラーの解消に取り組みました。
実はWebサイトで発見したCelebAクラスのソースコードを読み、(ほとんど意味がわからなかったですが)CelebAデータダウンロード処理の流れをソースコードから把握するよう努めて、対策の発見につなげることができました。
コードを眺めることにより、少しでも機械学習の気持ちに近づけたら。
# 今日の一句
print('機械学習はコードの通りに動く(はず)')楽しくPython機械学習プログラミングを学びましょう!
おまけ数式
noteでは数式記法を利用できます。
今回はニューラルネットワークの活性化関数として用いられるsoftmax関数の式を紹介します。
$$
p(z) = \sigma (z) = \cfrac {e^{z_i}} {\sum^M_{i=1} e^{z_i} }
$$
$${z}$$は総入力、$${M}$$はクラス数です。
次のグラフは、クラス数$${M=3}$$、$${z_1}$$を-5から10まで変化させ、$${z_2=5}$$、$${z_3=4}$$に固定した場合のsoftmax$${(z_i)}$$のグラフです。

グラフ作成のサンプルコードを添えておきます。
# softmax関数でクラス所属確率を計算してプロットする
import matplotlib.pyplot as plt
import numpy as np
z1 = np.arange(-5., 10., 0.1)
zs = (z1, 5.0, 4.0)
for i, z in enumerate(zs):
plt.plot(z1, np.exp(z) / sum(map(lambda x: np.exp(x), zs)),
label=f'softmax(z{i+1})')
plt.title(f'softmax(z_i) : M=3, z1=(-5~10), z2={zs[1]}, z3={zs[2]}')
plt.xlabel('z1')
plt.ylabel('p(z_i)')
plt.legend(loc='best')
plt.show()おわりに
AI・機械学習の学習でおすすめの書籍を紹介いたします。
「統計検定2級対応 統計学基礎」
データサイエンスの基礎を補強する上で、確率・統計の知識は欠かせないものになっています。
統計分野の資格の代表格が「統計検定」。
大学基礎課程レベルである「2級」から学んでみませんか?
2級を足がかりにして、上位の準1級、1級に次々とチャレンジしていくのもいいと思います。
私はこの公式テキストと公式問題集を利用して、2級を(ぎりぎり)取得しました。
試験の詳しい内容は、統計検定のホームページでご確認下さい。
なお、最近、公式問題集が刷新されました。CBT方式に対応したとのこと。
最後まで読んでくださり、ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?