
「数値シミュレーションで読み解く統計のしくみ」をPythonで写経 ~ 第5章5.3「エラー確率のシミュレーション」

第5章「統計的検定の論理とエラー確率のコントロール」
書籍の著者 小杉考司 先生、紀ノ定保礼 先生、清水裕士 先生
この記事は、テキスト「数値シミュレーションで読み解く統計のしくみ」第5章「統計的検定の論理とエラー確率のコントロール」の5.3節「エラー確率のシミュレーション」の Python写経活動 を取り扱います。
今回は統計的検定の第一種の過誤~タイプⅠエラー確率のシミュレーションです。
R の基本的なプログラム記法はざっくり Python の記法と近いです。
コードの文字の細部をなぞって、R と Python の両方に接近してみましょう!
ではテキストを開いてシミュレーションの旅に出発です🚀

はじめに
テキスト「数値シミュレーションで読み解く統計のしくみ」のご紹介
このシリーズは書籍「数値シミュレーションで読み解く統計のしくみ〜Rでためしてわかる心理統計」(技術評論社、「テキスト」と呼びます)の Python写経です。
テキストは、2023年9月に発売され、副題「Rでためしてわかる心理統計」のとおり、統計処理に定評のある R の具体的なコードを用いて、心理統計の理解に役立つ数値シミュレーションを実践する素晴らしい書籍です。
引用表記
この記事は、出典に記載の書籍に掲載された文章及びコードを引用し、適宜、掲載文章とコードを改変して書いています。
【出典】
「数値シミュレーションで読み解く統計のしくみ〜Rでためしてわかる心理統計」初版第1刷、著者 小杉考司・紀ノ定保礼・清水裕士、技術評論社
記事中のイラストは、「かわいいフリー素材集いらすとや」さんのイラストをお借りしています。
ありがとうございます!
5.3 エラー確率のシミュレーション
この記事は Jupyter Notebook 形式(拡張子 .ipynb)でPythonコードを書きます。
概ね確率分布の特性値算出には scipy.stats を用い、乱数生成には numpy.random.generator を用いるようにしています。
主に利用するライブラリをインポートします。
### インポート
# 数値計算
import numpy as np
# 確率・統計
import scipy.stats as stats
# 描画
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Meiryo'
5.3.1 タイプⅠエラー確率のシミュレーション
タイプⅠエラーは、帰無仮説が正しいときに$${p}$$値が有意水準$${\alpha}$$を下回って帰無仮説を棄却するエラーです。
$$
\begin{array}{l:l:l}
& 帰無仮説が正しい & 対立仮説が正しい \\
\hline
帰無仮説を棄却 & タイプⅠエラー\alpha & 正しい(検出力1-\beta) \\
帰無仮説を受容 & 正しい & タイプⅡエラー\beta \\\end{array}
$$
■ タイプⅠエラー確率が有意水準$${\alpha}$$未満になっているかシミュレーション
帰無仮説が正しい状況から生成したデータに対して「対応のない2標本のt検定」を行い、誤って帰無仮説を棄却した割合が有意水準$${\alpha=0.05}$$を下回ることをシミュレーションで確認します。
10000回の検定をシミュレーションします。
scipy.stats の ttest_ind() でt検定を行います。
### 197ページ タイプⅠエラー確率のシミュレーション
## 設定と準備
n = [20, 20] # サンプルサイズ
mu = [0, 0] # 母平均が等しい設定にする
sigma = 2 # 母標準偏差
iter = 10000 # シミュレーション回数
alpha = 0.05 # 有意水準
# 結果を格納するオブジェクト
pvalue = np.zeros(iter) # p値を格納する
## シミュレーション ※帰無仮説が正しい状況からデータ生成する
rng = np.random.default_rng(seed=123)
for i in range(iter):
Y1 = rng.normal(size=n[0], loc=mu[0], scale=sigma) # 群1のデータ生成
Y2 = rng.normal(size=n[1], loc=mu[1], scale=sigma) # 群2のデータ生成
pvalue[i] = stats.ttest_ind(Y1, Y2, equal_var=True).pvalue
## 結果
# 誤って帰無仮説を棄却した確率を計算
type1_error = np.where(pvalue < alpha, 1, 0).mean()
# 出力
type1_error【実行結果】
誤って帰無仮説を棄却した確率~タイプⅠエラー確率は有意水準$${\alpha=0.05}$$を下回りました。
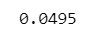

■ $${p}$$値の従う分布
テキストは「任意の連続確率分布に従う値を確率に変換した値は、一様分布に従う」と説明し、検定で算出した$${p}$$値も一様分布に従うとしています。
まずに標準正規分布に従う10000個の乱数について、標準正規分布の累積分布関数で確率値を算出してヒストグラムを描画し、一様分布に従うことを確認します。
### 198ページ 正規分布に従う乱数を生成し、その確率のヒストグラムを出力 図5.6
# 任意の確率分布に従う値を確率に変換した値は一様分布に従う
# 乱数生成器・乱数シードの設定
rng = np.random.default_rng(seed=123)
# 標準正規分布乱数を10000個生成
rnorm = rng.normal(size=10000, loc=0, scale=1)
# 乱数値=確率変数の実現値について標準正規分布の累積確率を算出
pnorm = stats.norm.cdf(x=rnorm, loc=0, scale=1)
# 確率のヒストグラムの描画
plt.hist(pnorm, ec='white', alpha=0.7)
plt.xlabel('pnrom (rnorm(10000, 0, 1), 0, 1)')
plt.ylabel('Frequency')
plt.title('Histogram of pnrom (rnorm(10000, 0, 1), 0, 1)');【実行結果】
一様分布に従う感じがします。

さきほどのシミュレーションで算出した$${p}$$値(確率値)の分布を確認します。
描画関数を定義します。
### p値のヒストグラム描画関数の定義
def plot_hist_pvalue(pvalue, bins=20):
# 描画領域の設定
plt.figure(figsize=(6, 3))
# ヒストグラムの描画
plt.hist(pvalue, bins=bins, ec='white', alpha=0.7)
# x軸ラベル、y軸ラベル、タイトルの設定
plt.xlabel('p value')
plt.ylabel('Frequency')
plt.title('Histogram of pvalue')
plt.show()描画します。
### 198ページ p値の分布 図5.7
plot_hist_pvalue(pvalue)【実行結果】
一様分布に従うように感じます。


5.3.2 t検定の等分散の仮定からの逸脱
t検定は2つの母集団の等分散を仮定しています。
テキストは、この仮定が成り立たない場合にタイプⅠエラー確率がどのように変化する(影響を受ける)かをシミュレーションで確認します。
■ 等分散の仮定が成立しない場合のt分布のタイプⅠエラー確率をシミュレーション
母標準偏差が$${2}$$と$${8}$$の正規分布乱数を$${20}$$個ずつ生成して、t検定の$${p}$$値を算定することを、10000回シミュレーションします。
最後にタイプⅠエラー:誤って帰無仮説を棄却する確率を表示します。
### 199ページ 2つの母集団の等分散の仮定が崩れたときのタイプⅠエラーの確率の変化
# 有意水準αを少し上回る確率になった
## 設定と準備
sigma = [2, 8] # 母標準偏差を2つの群で異なる設定にする
iter = 10000 # シミュレーション回数
alpha = 0.05 # 有意水準
n = [20, 20] # サンプルサイズ
mu = [0, 0] # 母平均が等しい設定にする
# 結果を格納するオブジェクト
pvalue = np.zeros(iter) # p値を格納する
## シミュレーション
rng = np.random.default_rng(seed=123)
for i in range(iter):
Y1 = rng.normal(size=n[0], loc=mu[0], scale=sigma[0]) # 群1のデータ生成
Y2 = rng.normal(size=n[1], loc=mu[1], scale=sigma[1]) # 群2のデータ生成
pvalue[i] = stats.ttest_ind(Y1, Y2, equal_var=True).pvalue
## 結果
# 誤って帰無仮説を棄却した確率を計算
type1_error = np.where(pvalue < alpha, 1, 0).mean()
# 出力
type1_error【実行結果】
有意水準$${\alpha=0.05}$$よりも上回りました。
等分散の仮定が成立しない場合、タイプⅠエラー確率に何らかの影響がありそうです。

■ サンプルサイズが異なる場合のタイプⅠエラー確率のシミュレーション
テキストのシミュレーションを続けます。
群1のサンプルサイズを40、群2のサンプルサイズを20にして、かつ、群2の母標準偏差を7段階に変化させるときに、タイプⅠエラー確率がどのように変化するかのシミュレーションです。
### 200ページ 2つの母集団の等分散の仮定が崩れたときのタイプⅠエラーの確率の変化2
# 母標準偏差の複数パターンをシミュレーション 201ページ図5.8
## 設定と準備
n = [40, 20] # サンプルサイズを変えた設定
sigma1 = 1 # 群1の母標準偏差
sigma2 = [0.2, 0.5, 0.75, 1, 1.5, 2, 5] # 群2の母標準偏差
p = len(sigma2)
iter = 10000 # シミュレーション回数
alpha = 0.05 # 有意水準
mu = [0, 0] # 母平均が等しい設定にする
# 結果を格納するオブジェクト
pvalue = np.zeros((p, iter)) # p値を格納する
## シミュレーション
rng = np.random.default_rng(seed=123)
for i in range(p):
for j in range(iter):
Y1 = rng.normal(size=n[0], loc=mu[0], scale=sigma1) # 群1のデータ生成
Y2 = rng.normal(size=n[1], loc=mu[1], scale=sigma2[i]) # 群2のデータ生成
pvalue[i, j] = stats.ttest_ind(Y1, Y2, equal_var=True).pvalue
## pvalue < alphaの割合の算出
type1_error_ttest = np.where(pvalue < alpha, 1, 0).mean(axis=1)
## 結果
fig, ax = plt.subplots(figsize=(6, 3))
ax.plot(range(len(sigma2)), type1_error_ttest, '-o')
ax.axhline(alpha, color='tab:red', ls='--', label='有意水準')
ax.set_xticks(ticks=range(len(sigma2)), labels=sigma2)
ax.set(xlabel='群2の母標準偏差', ylabel='タイプⅠエラー確率',
title='$t$ 検定のタイプⅠエラー確率の変化',
ylim=(-0.01, 0.21), yticks=np.arange(0, 0.21, 0.05));
ax.legend(loc='upper left');【実行結果】
群2の母標準偏差が1のときに等分散となります。
母標準偏差が大きくなるにつれてタイプⅠエラー確率の値も大きくなっています。

テキストは「t検定は等分散の仮定の逸脱に対して脆弱である」としています。
群2の母標準偏差が5のときの$${p}$$値の分布を可視化して、等分散からの逸脱の影響を確認します。
### 201ページ 母標準偏差が5倍のときのp値 202ページ図5.9
# 小さい値に偏っている
plot_hist_pvalue(pvalue[6, :])【実行結果】
0に近い小さな値に偏っています。


■ Welch 検定によるタイプⅠエラー確率シミュレーション
テキストは「Welch検定は、母分散が異なるときに生じるタイプⅠエラー確率のインフレを抑えてくれます」と紹介して、シミュレーションに突入します。
先程の群2の母標準偏差を7段階に変化させるケースについて Welch検定とタイプⅠエラー確率のシミュレーションに進みます。
scipy.stats の ttest_ind() の引数 equal_var=False とすることで、Welch検定を実行できます。
### 202ページ 母分散が異なる2標本のWelch検定 203ページ図5.10
# 2群の平均値の差の検定のときは「常に」Welch検定を使うのが望ましい
## 設定と準備
n = [40, 20] # サンプルサイズを変えた設定
sigma1 = 1 # 群1の母標準偏差
sigma2 = [0.2, 0.5, 0.75, 1, 1.5, 2, 5] # 群2の母標準偏差
p = len(sigma2)
iter = 10000 # シミュレーション回数
alpha = 0.05 # 有意水準
mu = [0, 0] # 母平均が等しい設定にする
# 結果を格納するオブジェクト
pvalue = np.zeros((p, iter)) # p値を格納する
## シミュレーション
rng = np.random.default_rng(seed=123)
for i in range(p):
for j in range(iter):
Y1 = rng.normal(size=n[0], loc=mu[0], scale=sigma1) # 群1のデータ生成
Y2 = rng.normal(size=n[1], loc=mu[1], scale=sigma2[i]) # 群2のデータ生成
# equal_var=FalseでWelch検定
pvalue[i, j] = stats.ttest_ind(Y1, Y2, equal_var=False).pvalue
## pvalue < alphaの割合の算出
type1_error_ttest = np.where(pvalue < alpha, 1, 0).mean(axis=1)
## 結果
fig, ax = plt.subplots(figsize=(6, 3))
ax.plot(range(len(sigma2)), type1_error_ttest, '-o')
ax.axhline(alpha, color='tab:red', ls='--', label='有意水準')
ax.set_xticks(ticks=range(len(sigma2)), labels=sigma2)
ax.set(xlabel='群2の母標準偏差', ylabel='タイプⅠエラー確率',
title='Welch検定のタイプⅠエラー確率の変化',
ylim=(-0.01, 0.21), yticks=np.arange(0, 0.21, 0.05));
ax.legend(loc='upper left');【実行結果】
見事にタイプⅠエラー確率が有意水準$${\alpha=0.05}$$に抑えられています!

今回の写経は以上です。
シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。
この記事が気に入ったらサポートをしてみませんか?