14章 CNN:笑顔が終わらない!(中編)

はじめに
シリーズ「Python機械学習プログラミング」の紹介
本シリーズは書籍「Python機械学習プログラミング PyTorch & scikit-learn編」(初版第1刷)に関する記事を取り扱います。
この書籍のよいところは、Pythonのコードを動かしたり、アルゴリズムの説明を読み、ときに数式を確認して、包括的に機械学習を学ぶことができることです。
Pythonで機械学習を学びたい方におすすめです!
この記事では、この書籍のことを「テキスト」と呼びます。
記事の内容
この記事は「第14章 画像の分類-ディープ畳み込みニューラルネットワーク」の「14.4.3 CNN 笑顔分類器を訓練する」のモデルの訓練処理が長時間かかっていることを書きます。
中編では、GPUを求めてGoogle Colabに進みます。
14章のダイジェスト
14章は、CNN:畳み込みニューラルネットワークで画像を分類するタスクにチャレンジします。
PyTorchで画像データを処理する章です。
まず、特徴マップ、畳み込み層とプーリング層の計算の概念を学び、続いて、PyTorchでCNNを実装します。テーマは2つ。1つ目は手書き数字の分類タスク(おなじみのMNISTデータセット)。2つ目は写真画像から笑顔を分類するタスクです。
前編のダイジェスト
「14.4.3 CNN 笑顔分類器を訓練する」の節では、20万人以上の有名人の顔データベースである「CelebAデータセット」を使って、顔画像が笑顔かどうかを判定する分類器をディープ畳み込みニューラルネットワークで作成します。
訓練する分類器の名前は「笑顔分類器」。
16000枚の顔画像で30回(エポック)の訓練処理を始めましたが、4回の訓練に2時間かかりました。残り26回の訓練におよそ13時間を要する見込みです。笑顔の終わりが見えません!
GPUを搭載していないパソコンでディープラーニングの訓練を行うことに無理があるのでしょうか。。。
前編はこちらのリンクから。
Google Colabを使ってみる
1. Google Colabへ
「Google Colabにチャレンジしよう」
Google Colabは、Googleが提供するサービス「Google Colaboratory」です。Webブラウザで Python をJupyter Notebook形式で記述して実行できます。
しかも「GPUを無料で使える」のです。
こちらのリンクでGoogle Colabへ。
2. 環境の確認
①PyTorch等のインストール状況の確認
Google Colab のノートブック(以下、ノートブックと言います)で、pipコマンドを実行して、インストール済みのパッケージを調べます。
!pip listPyTorch、torchvisionは、GPU(CUDA)対応版がインストール済みでした。
- torch 1.13.1+cu116
- torchvision 0.14.1+cu116
②GPU使用の確認
Google Colab でGPUを使う場合には、次の図のように、GPUを指定しておきます。
Google Colabのメニューの「ランタイム」>「ランタイムのタイプを変更」
ハードウェアアクセラレータで「GPU」を選択して「保存」
ノートブックでPyTorchのGPUが有効か確認します。
# PyTorchでGPUが有効か確認する
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('using device:', device)
出力結果
using device: cuda:0以上の確認により、Google Colab でGPUを使って笑顔分類器の訓練を実施できそうなことが分かりました。
3. 前準備
①CelebAデータセットをGoogle ドライブに保存
<ここからはGoogleドライブの話になります>
12章の処理で、すでにデータ一式をローカルに保存しています。
まず、このローカルのデータをGoogle ドライブにコピーします。
CelebAデータセットの取得に関するドタバタ劇に関しては、過去の記事をご覧ください。
問題は、20万超の画像ファイルを圧縮したファイル「img_align_celeba.zip」の取り扱いです。
選択肢は次の3つ。
解凍後の20万超の画像ファイルをGoogleドライブにアップロード
zipファイル(1ファイル)をアップロードした上で、解凍ツール「ZIP Extractor」を利用してGoogleドライブ上で解凍
zipファイル(1ファイル)をアップロードした上で、何らかの方法でGoogleドライブ上で解凍
結論は「3」です。
テキストのコードに記述された「Pythonのパッケージであるtorchvisionを用いて解凍」しました。
1の方法の「20万ファイルのアップロード」は、コピー元のパソコンのエクスプローラーとGoogleドライブのアップロード画面が固まってしまい、アップロード不能です。ファイルが多すぎたのでしょう。
2の方法の「ZIP ExtractorでGoogleドライブ上で解凍」は、ZIP Extractorが20万ファイルのリストを生成する処理が途中で止まってしまい、解凍できませんでした。圧縮されたファイル数が多すぎたのでしょう。
これらの事実を踏まえると、Google ColabのPython実行環境はPython処理に対して強力です。
②Googleドライブにファイルをコピー
次の図のように各ファイルを配置しました。
pmlpフォルダは作業フォルダです。
作業フォルダの配下にdataフォルダ、dataフォルダの配下にcelebaフォルダを作ります。
celebaフォルダに7ファイルを配置します。
③zipファイルを解凍
<ここからはGoogle Colab の話になります>
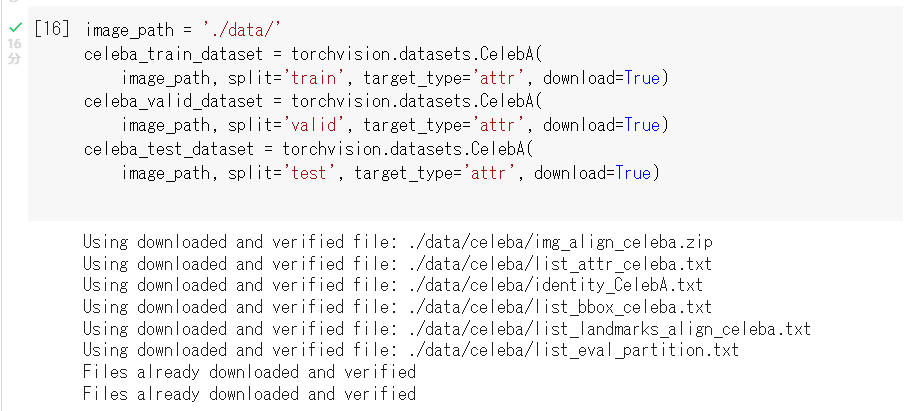
zipファイルを解凍するために、ノートブックでテキストのコードを実行します。
引数 download=True と設定します。
テキストのコードを引用いたします。
# CelebAデータセットをGoogleドライブに配置する(zip解凍をする)
import torchvision
image_path = './data/' # celebaフォルダの上位フォルダ
celeba_train_dataset = torchvision.datasets.CelebA(
image_path, split='train', target_type='attr', download=True)
celeba_valid_dataset = torchvision.datasets.CelebA(
image_path, split='valid', target_type='attr', download=True)
celeba_test_dataset = torchvision.datasets.CelebA(
image_path, split='test', target_type='attr', download=True)処理時間は16分ほど。無事に解凍できました。
4. 笑顔分類器の訓練処理の実行
訓練処理までに実施したGPU対策等のいろんなことの記載はひとまず省きます・・・・。
で、30回の訓練(エポック)を「22.5分」で完了しました!
GPUのパワーは凄いです!
CPU処理の40倍のはやさです!
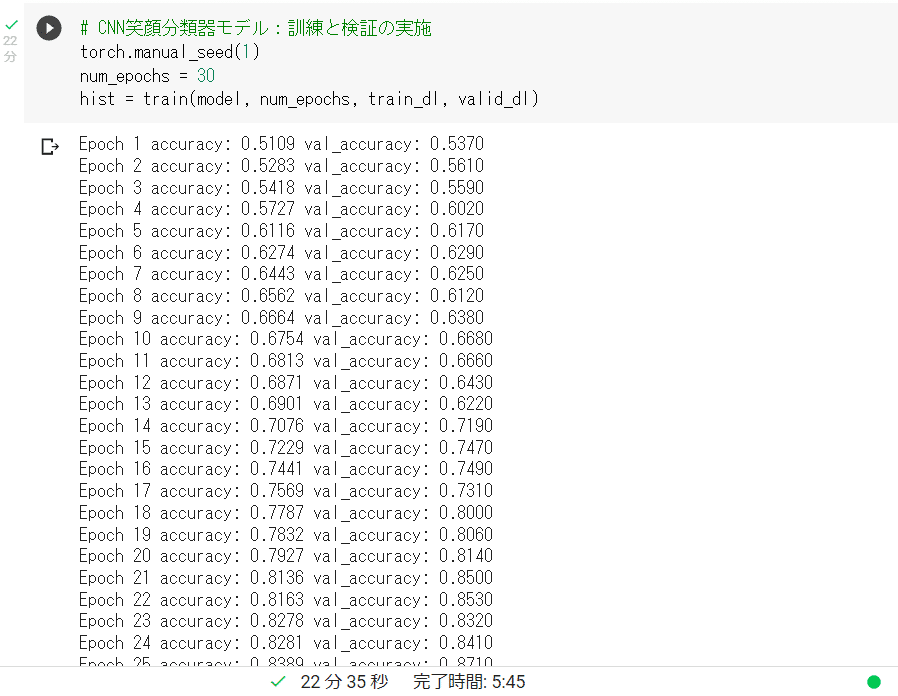
ただし、GPU使用のためのコードの修正に誤りが発覚したため、コード修正後、再実行することにしました。
5. 再実行してみたものの・・・
修正コードにてGoogle Colabで訓練を再開しましたが、なんと、1時間経っても最初の1訓練(1エポック)が完了しないのです!
どういうこと????
ネットの情報では、Google ColabのGPU処理が多発する時間帯では、処理がはやくならないことがある、というものがありました。
もしかすると、この事象にあたったのかもしれません。
そうこうしているうちに・・・
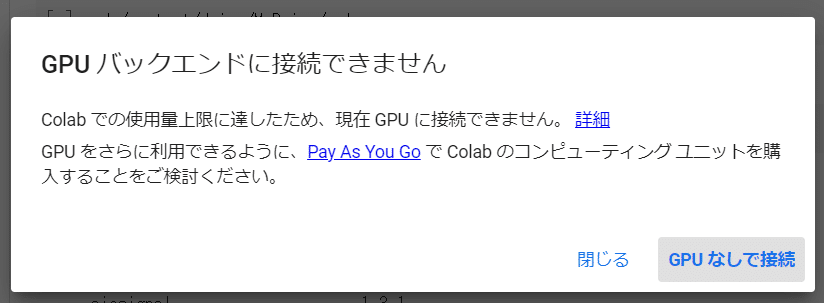
使用量上限に達したため、GPUが使えなくなりました。
がっくし。
To Be Continued!
番外編:CPU処理のその後
1. 終わらない訓練の終焉
<ここからはローカルパソコンの話になります>
ローカルパソコンでの笑顔分類器の訓練は・・・
一夜明けてもまだ終わりません。
パソコンさんのおやすみ(sleep)が入ったこともあり、900分経過時点で完了したのは20エポック。
断腸の思いで処理を強制的に終了しました。
2. 訓練を中断したモデルの性能
訓練処理を中断しましたが、モデル自体の情報は残っています。
20エポックの訓練で磨かれた笑顔分類器のモデルの状況を綴ります。

正解率は、訓練データで約91%、検証データで92%となかなかの成績です。
テキストの想定では訓練データ:88%、検証データ:90%です。
また、テストデータの正解率は91.92%でした(テキストは90.21%)。

テキストを上回っています。高い性能のようです。
過学習しているのかな。。。
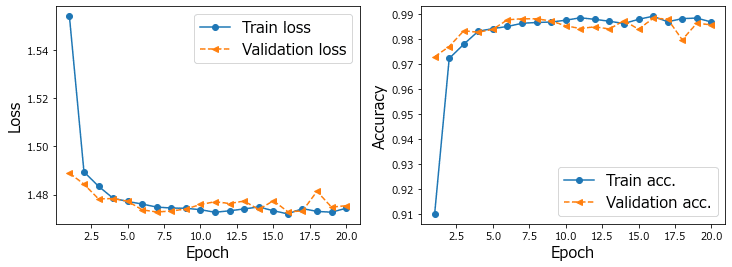
学習曲線は次のようになりました。
検証データの立ち上がりに不穏な雰囲気を感じるのはなぜでしょう・・・。
3. 笑顔分類器の実演
テキスト14章の最後のコードでは、訓練済みのモデルを使い、テストデータセットの最後のバッチから10個のテストデータを取り出して、画像とラベル(笑顔かどうか)を判定・表示します。
20エポックの訓練で(強引に)完成させたモデルで判定・表示処理をした結果が次の図です。

文字の1行目は笑顔かどうかの正解データ、2行目は訓練済みのモデルで予測した笑顔の確率です。
予測した確率で正しく分類できているようです。
CPUで20エポックの訓練をしたモデルで十分な性能がでているので、わざわざGPUにチャレンジしなくていいのかも・・・w
@inproceedings{liu2015faceattributes,
title = {Deep Learning Face Attributes in the Wild},
author = {Liu, Ziwei and Luo, Ping and Wang, Xiaogang and Tang, Xiaoou},
booktitle = {Proceedings of International Conference on Computer Vision (ICCV)},
month = {December},
year = {2015}
}
4. 訓練したモデルを保存
# CNN笑顔分類器:訓練したモデルの保存
path = 'models/celeba-cnn.ph'
torch.save(model, path)後編に続く!(かな?)
まとめ
今回は、Google ColabのGPUを利用して訓練を実施する準備をしました。
実験的な訓練ではローカルパソコンの40倍の高速処理を実現できました。
しかし、作業途中でGPUの使用上限に達したため、GPUによる笑顔分類器の訓練が完了しませんでした。
12時間後に制限がリセットされると言われています。
Google Colab のGPU環境で、高速な訓練処理を実行・完了できることを祈って、筆を置きます。
# 今日の一句
print('CPU inside'.replace('C', 'G'))楽しくPython機械学習プログラミングを学びましょう!
おまけ数式
noteでは数式記法を利用できます。
今回はドロップアウトの議論の中に出現するモデルの幾何平均の式を紹介します。
$${M}$$個のモデル$${i}$$によって返されるクラスの所属確率$${p^{[i]}}$$の幾何平均を次のように求めます。
$$
P_{Ensemble}= \left[ \prod^{M}_{i=1} p^{[i]} \right]^{\frac{1}{M}}
$$
おわりに
AI・機械学習の学習でおすすめの書籍を紹介いたします。
「最短コースでわかる ディープラーニングの数学」
機械学習やディープラーニングなどの手法を理解する際に、数学的な知識があると、いっそう深い理解につながると思います。
でも、難しい数式がびっしりと並んでいる書面を想像すると、なんだかゾッとします。
そんな数式にアレルギーのある方にとって、この「ディープラーニングの数学」は優しく寄り添ってくれて、「数学的」な見方を広げてくれるのではないでしょうか。
この書籍は、機械学習/深層学習の基礎的なテーマを、Pythonのコードを動かしながら、そして数学的な見解も実感しながら、楽しく学ぶことができると思います。
機械学習/深層学習の入門者にとって、次のようなトピックの理解を深くするチャンスとなるでしょう。
損失関数とその微分
活性化関数
交差エントロピー関数
誤差逆伝播
勾配降下法(最急降下法)
ちなみに、私が初めて手にした機械学習/深層学習の書籍が、このディープラーニングと数学でした。思い出深い一冊です。
サンプルコードが動かなかった時に、著者の赤石先生とTwitterでやりとりさせていただいたことは、とても嬉しい出来事でした。
今もときどき、自分の理解を整理する際に、ページを捲ります。
最後まで読んでくださり、ありがとうございました。