
LLM登場までの深層学習の歴史を振り返ってみた[後編]

みなさんこんにちは!
ワンキャリアでデータサイエンティストをしている長谷川です!
今回の記事では、LLM(Large Language Model:大規模言語モデル)登場に至るまでの深層学習の歴史の後編となります。
前編をまだ読んでいない方は、こちらをまずご覧ください。
後編では、LLMについてメインでお話いたします。
事前学習モデルが登場する
今回は下図、2018年のGPT(Generative Pre-trained Transformer)のところからスタートします。GPT の話をする前にその背景にあった技術について紹介いたします。
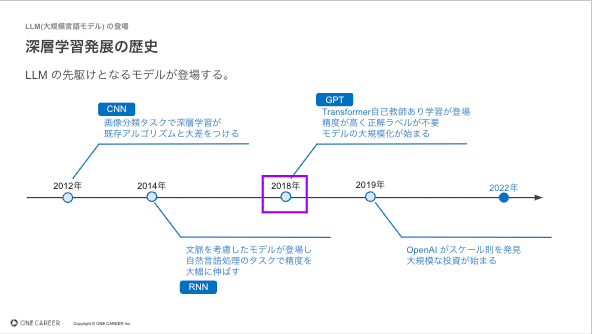
GPT の登場には2つの技術・手法が大きく関連します。
まずは Transformer の登場です。
前編では、RNN(Recurrent Neural Network:回帰型ニューラルネットワーク)が自然言語処理の領域において真価を発揮したとお伝えしました。しかし、RNN には精度・コストの点で課題がありました。
精度に関して、RNN は入力で入ってきた単語を再帰的に取り込んで文脈を捉えます。しかし、この仕組みは入力文章が長くなればなるほど最初に入力した単語の影響が消失してしまうという問題がありました。この問題を解決しようとLTSM(Long Short Term Memory)が登場したのですが、それでも限界がありました。
またコストに関して、RNN は仕組み上、前から全ての単語を順番に入力していく必要があります。つまり、並列で計算できない・直列で計算する必要があり、長い文章では計算量が膨大になってしまうという問題がありました。

この2つの問題を解決したのが Transformer です。
Transformer では Attention という新しい構造が導入されています。Attention は入力された文章と解くべきタスクに対して、文のどの単語が重要か、どの単語に注目すべきかを決める仕組みです。「重要な情報だけに焦点を当てる」ということです。
これにより、文章が長くなってもどこに注目すれば良いかがわかり、精度が落ちないようになりました。
また、Attention は RNN ではできなかった並列処理を可能にしました。Attentionでは、入力の異なる要素に対して重みを計算するため、各要素の重要度を独立して計算することができます。一方、RNNは時系列の依存関係を考慮しながら逐次的に計算されるため、パラレル処理が難しく、計算時間がかかります。
この Attention の構造を中心に構築されたのがTransformerになります。

次に、Transformer と同時期に脚光を浴びたのが「自己教師あり学習」です。
自己教師あり学習は教師あり学習の一種ですが、その教師あり学習のボトルネックであった正解ラベルの作成を解消したものになります。
従来の教師あり学習では、正解ラベルが付与されたデータを使用してモデルを訓練する必要があります。つまり、人が正解ラベルをあらかじめ準備する必要があります。少量のデータで学習が完了するモデルやタスクであれば良いですが、大量のデータを必要とする学習では正解ラベルの準備が大きなコストとなります。
一方、自己教師あり学習では入力データを利用して、自動的に正解ラベルを作成します。
下記の例をみてみましょう。
教師あり学習では「分類問題」を解いています。画像を入力として犬か猫かを予測するタスクですが、この学習には画像に犬か猫の正解ラベルをつける必要があります。自己教師あり学習はどうでしょう。こちらは画像の「穴埋め問題」を解いています。

Transformer、自己教師あり学習の恩恵を受けて登場したのがGPTやBERTと言った事前学習モデルです。
従来の機械学習では特定のタスク用のデータセットがあり、そのタスクを解くためのモデルを学習します。タスクを変えるごとにゼロからの学習が必要となり、そのためのコストがかかっておりました。
そこで登場したのが事前学習モデルです。事前学習モデルでは特定のタスクを解くための学習はせずに、汎用的な知識を学習します。例えば、GPTやBERTでは後に続く単語の予測問題と穴埋め問題で学習しており、文脈理解や単語の関係性といった知識を獲得します。
この学習で必要なのは文章だけであり、Web上からスクレイピングした文章データ(コーパス)が学習可能な対象になります。この汎用的な知識を得たモデルを事前学習モデルと呼びます。
事前学習モデルは後に続く特定のタスクに対してfine-tuning されることを目的としております。fine-tuning の際に少量のデータセットで学習が完了することがわかっており、データセットの準備のコストが軽減されています。また、学習したモデルの精度も従来のモデルよりも高く、事前学習モデルは非常に使い勝手が良いです。ここで登場したGPTが後のLLMの時代を切り開きます。

スケール則の発見とモデルの大規模化
いよいよクライマックスです。最後はスケール則について。
スライドにもある通り、ChatGPT を開発した OpenAI が発見した法則がスケール則です。

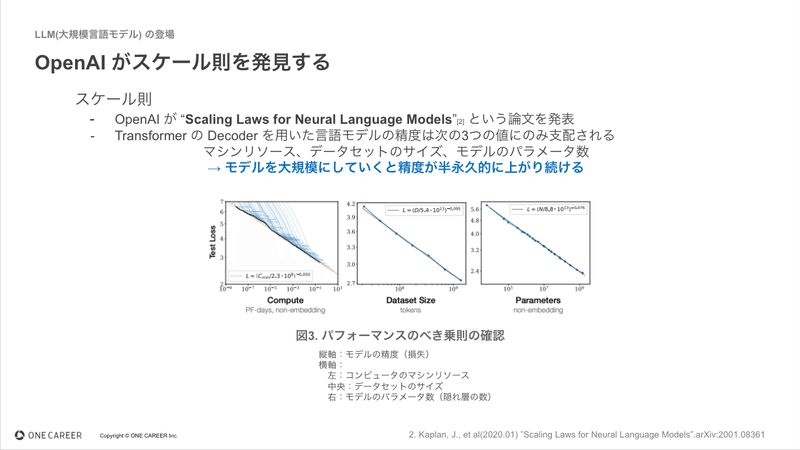
2019年、OpenAIが “Scaling Laws for Neural Language Models” という論文を発表しました。 “Scaling Laws” を直訳するとスケール則になります。この論文で語られたことは、Transformer の Decoder を用いた言語モデルの精度は、マシンリソース・データセットのサイズ・モデルのパラメータ数の3つの値にのみ支配されるということです。
これら3つをバランスよく上げていくと、モデルの精度が半永久的に上がり続けることを示したのでした。このスケール則の発見が、LLMの進化を加速させることになりました。
スケール則の発見が意味していたのは、「高額投資をすれば、誰でも精度の高い言語モデルを作り出せる」ということです。
自己教師あり学習によって、Web上にある大量のテキストデータを学習対象にできるようになったこと。Transformer によって、学習時間が短縮されたこと。全てが揃ったことで、モデルの精度を半永久的に上げ続けるという夢のようなことが実現可能になったのです。
精度が保証されている、すなわち投資対効果が分かったことで、各社はモデルの大規模化を進めました。そして、スケール則が発見された頃にマイクロソフトはOpenAIへ高額投資をしております。スケール則の発見はこれだけ多くのお金を動かし、LLMの進化を加速させたのでした。

ChatGPTをはじめとするLLMが社会で活用される
そして2023年現在、ChatGPTをはじめとする多くのLLMが登場し社会実装が進んでおります。下記はLLMとそのモデルのパラメータ数を表した図になります。ChatGPT の前身であるGPT-3は175B、つまり 1,750億個のパラメータを持っております。
元々深層学習はニューラルネットワークとも呼ばれ、人間の神経細胞の機構を模したものになります。人の神経細胞は脳全体で860億個と言われているので、人よりも賢いLLMが登場しても何も驚かない、そんな時代に入ったと考えられます。今後のLLM、ないしはAIの進化にも期待ですね。

おわりに
以上で後編は終了です。お付き合いいただきありがとうございました。
前編、後編を通して深層学習の歴史について説明してきました。なにかしらの参考になれば幸いです。
ちなみにワンキャリアでは、エンジニアを絶賛募集中です!
LLM、R&D、データサイエンティストなどにご興味のある方はぜひ一度、カジュアルにお話しましょう!
▼ワンキャリアのエンジニア組織のことを知りたい方はまずこちら
▼カジュアル面談を希望の方はこちら

▼エンジニア求人票
この記事が気に入ったらサポートをしてみませんか?