
ScatterPlot with ggplot2 -ggplot2による散布図の書き方-

ggplot2による散布図の書き方
自己紹介
分析屋の堀井です。 今回はTidyverseというRを語るうえで欠かせないパッケージ群の中からggplot2を用いた散布図の書き方を紹介しようと思います。
普段はライフサイエンス部で機械学習・深層学習を用いて人による判断の自動化を行っています。
弊社の技術ブログでは勝手にRを解説するシリーズを投稿して、社内にRの良さを布教することを画策しています。
使用するパッケージ一覧
library("tidyverse")使用するデータ
カリフォルニアの住宅価格のデータセットを使用します。
様々なオープンデータを紹介しているサイトの「housez.zip」をcsv形式にしたものを使用します。また、 中身は以下の通りです。
data <- read_csv("data/California_Housing.csv")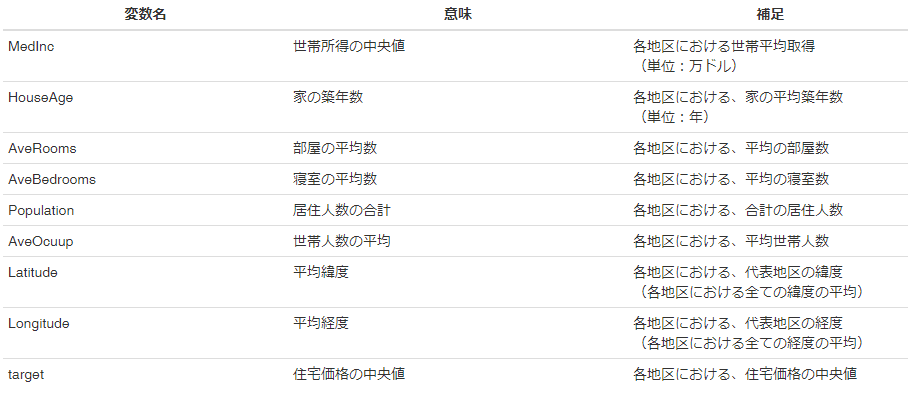
散布図とは
横軸と縦軸にそれぞれ2つの変数を取り、各データポイントを点として表現します。これにより、2つの変数間の相関やパターンを視覚的に捉えることができます。データポイントが散らばっているか、一直線上に集まっているかなど、データ間の関係性や傾向を容易に把握するため図です。
とりあえず、書いてみる
とりあえず、散布図を書いてみます。
ggplot2の書き方のパターンは以下のようになっています
「データセット」「変数」を選択
「グラフの種類」を選択し、オプションを設定する
各コードは”+“で繋ぐ
data %>%
ggplot(aes(x = MedInc, y = target)) +
geom_point()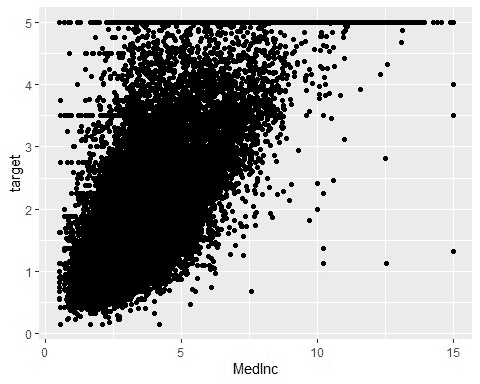
回帰直線を引いてみよう(信頼区間あり)
どのような相関関係があるかぱっと見でわかるように回帰直線を引いてみましょう。
住宅価格の中央値と世帯所得の中央値には正の相関関係があるようです。
data %>%
ggplot(aes(x = MedInc, y = target)) +
geom_point() +
geom_smooth(method = lm) 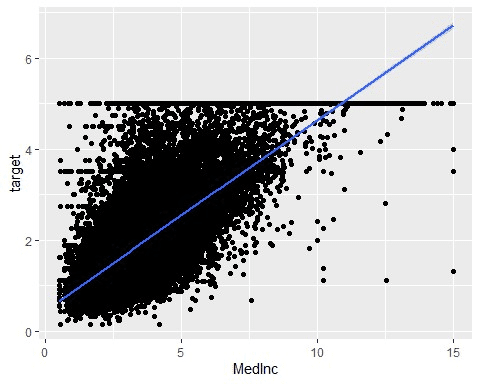
回帰直線を引きたい(信頼区間なし)
信頼区間を出力したくない場合は、geom_smooth()のなかでse = Fを指定します。
data %>%
ggplot(aes(x = MedInc, y = target)) +
geom_point() +
geom_smooth(method = lm, se = F) 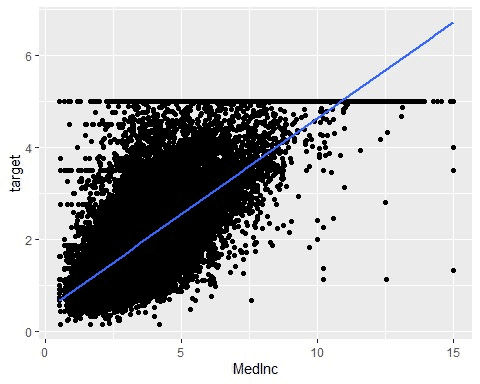
回帰直線を曲線にする
geom_smooth()の中でformulaを設定することで回帰直線をさらにフィッティングさせることができる。
data %>%
ggplot(aes(x = MedInc, y = target)) +
geom_point() +
geom_smooth(method = lm, formula = y ~ poly(x, 3)) 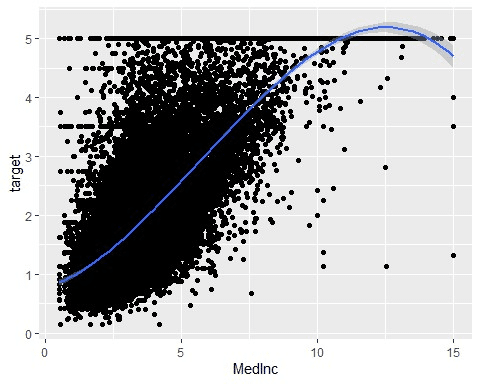
dplyrでデータを処理してから可視化することもできる
filter(MedInc <= 10)で世帯平均所得の中央値を10万ドル以下に絞ってから可視化を行っています。 パイプ演算子を使ってデータの受け渡しをしているので、可視化をする前に前処理を入れることを実現しています。
「data1」や「data2」みたいな変数名を作ることを避けられて便利です。
data %>%
filter(MedInc <= 10) %>%
ggplot(aes(x = MedInc, y = target)) +
geom_point()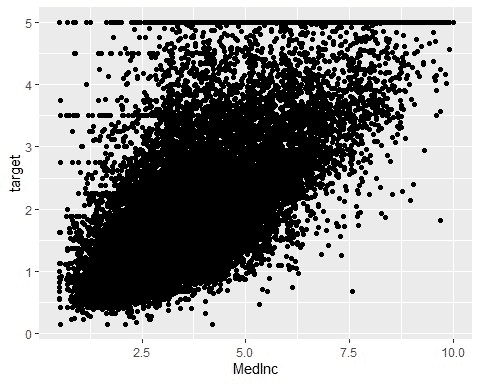
緯度経度をXとYに設定し、住宅価格の中央値で色分けしてみる
緯度経度を可視化することでカリフォルニアの形が何となく見えている。
さらに散布図の点を住宅価格で色分けすると、沿岸部は住宅価格の中央値が高いとわかります。
色分けを駆使すればXとYだけではなく3つ目の要素も可視化することができます。
data %>%
ggplot(aes(x = Longitude, y = Latitude, colour = target)) +
geom_point()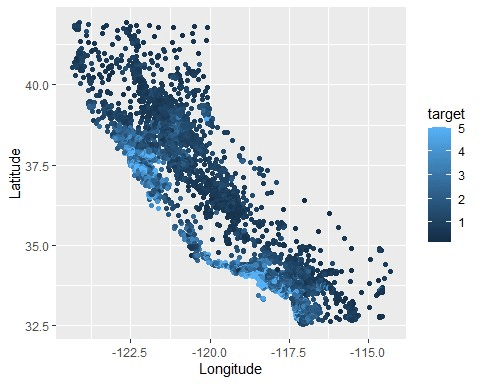
おまけに…テーマ変更のやり方
ggplot2は図形のカラーテーマが色々と用意されています。
例えば背景を白に、グリッド線は薄い黒にする場合はtheme_bw()
data %>%
ggplot(aes(x = MedInc, y = target)) +
geom_point() +
theme_bw()
背景を白色、グリッド線を黒にする場合はtheme_linedraw()
data %>%
ggplot(aes(x = MedInc, y = target)) +
geom_point() +
theme_linedraw()
背景を白色、枠線もグリッド線も薄い黒にする場合はtheme_light()
data %>%
ggplot(aes(x = MedInc, y = target)) +
geom_point() +
theme_light()
最低限の装飾にする場合はtheme_minimal()
data %>%
ggplot(aes(x = MedInc, y = target)) +
geom_point() +
theme_minimal()
論文に掲載するような図形はtheme_classic()のようなデザインが多い
data %>%
ggplot(aes(x = MedInc, y = target)) +
geom_point() +
theme_classic()
ggplot2には様々なテーマが用意されていますので、皆さんの好きなデザインを探してみてください。
まとめ
今回はggplot2を用いた散布図の書き方を説明しました。
ggplot2はユーザーのノンプログラマーにもわかりやすく積み上げ式でコードを記述するため、
記述量は長くなりますが、非常に理解は簡単な構造になっているかと思います。
また、ggplot2とデータの抽出をパイプ演算子を用いて組み合わせることで、
グラフ作成時にしか使用しないような変数をデータフレーム内に作らず計算することができます。
ここまでお読みいただき、ありがとうございました!
この記事が少しでも参考になりましたら「スキ」を押していただけると幸いです!
これまでの記事はこちらから!
株式会社分析屋について
弊社が作成を行いました分析レポートを、鎌倉市観光協会様HPに掲載いただきました。
ホームページはこちら。
noteでの会社紹介記事はこちら。
【データ分析で日本を豊かに】
分析屋はシステム分野・ライフサイエンス分野・マーケティング分野の知見を生かし、多種多様な分野の企業様のデータ分析のご支援をさせていただいております。 「あなたの問題解決をする」をモットーに、お客様の抱える課題にあわせた解析・分析手法を用いて、問題解決へのお手伝いをいたします!
【マーケティング】
マーケティング戦略上の目的に向けて、各種のデータ統合及び加工ならびにPDCAサイクル運用全般を支援や高度なデータ分析技術により複雑な課題解決に向けての分析サービスを提供いたします。
【システム】
アプリケーション開発やデータベース構築、WEBサイト構築、運用保守業務などお客様の問題やご要望に沿ってご支援いたします。
【ライフサイエンス】
機械学習や各種アルゴリズムなどの解析アルゴリズム開発サービスを提供いたします。過去には医療系のバイタルデータを扱った解析が主でしたが、今後はそれらで培った経験・技術を工業など他の分野の企業様の問題解決にも役立てていく方針です。
【SES】
SESサービスも行っております。