
AI人材のための教養としてのベクトルデータベース

はじめに
本記事では、ベクトルデータベースとは何かを初心者向けにまとめています。
生成AIやRAG、ベクトルデータベースは難しいイメージを持つ人が多いですが、実はとてもシンプルで実装も簡単です。15分程度で実装できるようになり、かつ語れるようになると思います。
実装方法が気になる方はQiitaの方に詳細とコードを載せているので参考になると思います。
ベクトルデータベースとは?
ざっくり分かりやすく説明します。イメージを掴むことを優先します。
はじめに結論
大まかに言うと、文章を保管するためのデータベースです。
文章をそのまま保管せず「ベクトル」に変換して保存するため、「ベクトルデータベース」と言います。
まず普通のデータベースについて
普通のデータベースには数字のデータが入っておりSQLで必要な情報を抜き出すことができます。例えば、ある顧客の1年間での売り上げ金額を取得したりできます。
ベクトルデータベースとは?
一方で、PDFファイルなどの文字情報を検索したい場合はどうすれば良いでしょうか?
例えば、100ページに渡る論文の中から特定の情報を知りたい時などです。一枚一枚目視をしていては日が暮れてしまいます。
そのような場合に使うのがベクトルデータベースです。大量の文字情報をチャンクという文節の単位で切り分けデータベースの値として保存します。

何がベクトルなのか?
チャンクにわけた文節をそのまま文字でデータベースに保管するわけではなく、文字をベクトルにしてから保存するためベクトルデータベースと言われています。文字情報のままでも使えますが、重いです。そこでベクトル化をすることで文字データを圧縮しつつ、数字として扱うことで検索の自由度を高めることができます。

犬と猫がどれだけ似た単語かを判別するにも、AIが認識できる形「ベクトル」に変換する必要がある。
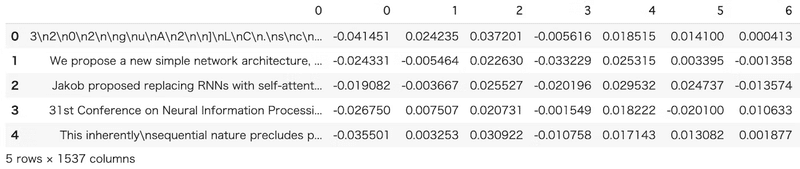
ベクトルデータベースの中身
こんな感じです↓
行名にチャンクにした文章が入っており、以降の列はベクトルになっています。見ての通り普通のDBと同じです。文章の検索よりもベクトルの類似度の検索の方がはるかに簡単なためこのような構造になっています。
まとめ
ベクトルデータベースを大まかに言うと、文章を保管するためのデータベースです。文章をそのまま保管せず「ベクトル」に変換して保存するため、「ベクトルデータベース」と言います。
実際の中身は、普通のデータベースと殆ど変わらないため、身が得る必要はありません。
具体的な実装についてはQiitaにまとめています。
終わりに
2024年4月からアウトプットのためにQiitaとnoteを始めました。「フォロー」や「いいね」頂けると励みになります!
この記事が気に入ったらサポートをしてみませんか?