
スタック領域とヒープ領域 vol.34

今回は前回出てきた、ヒープ領域とスタック領域について説明していこうと思う。
1.スタック領域とは
後に入れたものが先に出る構造になっている情報を格納できる領域のこと。
そういってもわかりにくいので…
砕いて言うと
Javaにはもともと様々な情報が元から格納されている。
私たちが、int型やboolean型などの変数を使用するとき、変数宣言をしたときに元からあるデータたちの後にデータが格納される。
後から格納されたにもかかわらず、変数名を書くだけでデータを呼び出せてしまう。
一時的に後入れし、すぐ取り出せるところにあるのがスタック領域としての砕けたイメージだと私は捉えている。
サイズ的には小さい
2.ヒープ領域とは
インスタンスの生成時に割り当てられるデータ領域のこと。
ヒープ領域内にはインスタンスのほかにクラスも割り当てられている。
大きなサイズのデータを格納できる。
3.スタック領域とヒープ領域の関係性
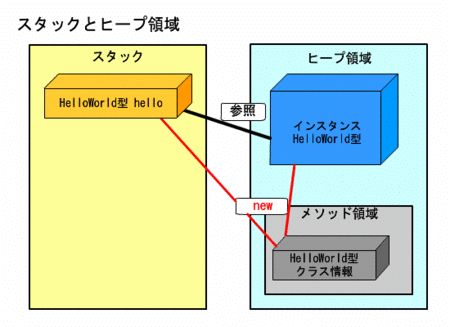
前回インスタンスの生成について説明したが、その時に使ったnewすることによって、インスタンスの生成ができ、クラス型変数ができるようになっている。
newするとインスタンスとクラス型変数ができるということだ。
クラス型はスタック領域に格納されいつでも呼び出せるところにある。
インスタンスはヒープ領域に格納され、クラス型を通して参照することができる。
クラス型変数はインスタンスを参照できる。
配列の時と同じようにインスタンスの住所のようなものをクラス型変数は記憶しており、参照できる仕組みになっている。
では参照型と呼ばれるものはほかにもあったと思う。今回のクラス型や配列が参照型であり、これをみて、String型は参照型ではないと思う方がいると思うが、String型はStringクラスというものがある。よってString型はクラス型であるのだ。
しかし納得いかないと思う。String型は少し特別なのだ。
String型について次回説明していこうと思う。
では。また次回
元体育会系文系エンジニア石黒
この記事が気に入ったらサポートをしてみませんか?