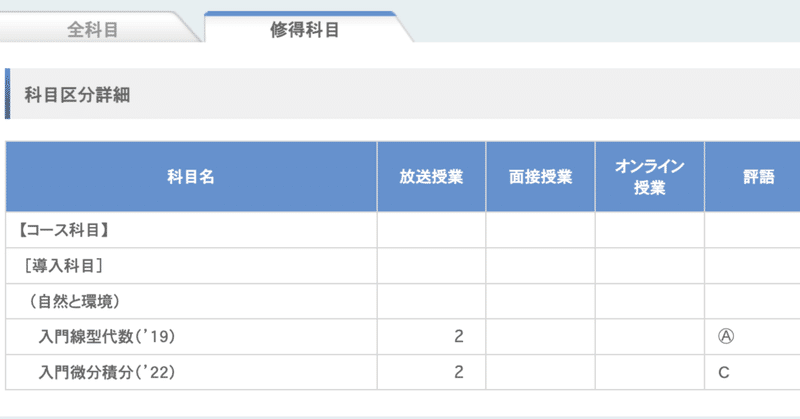
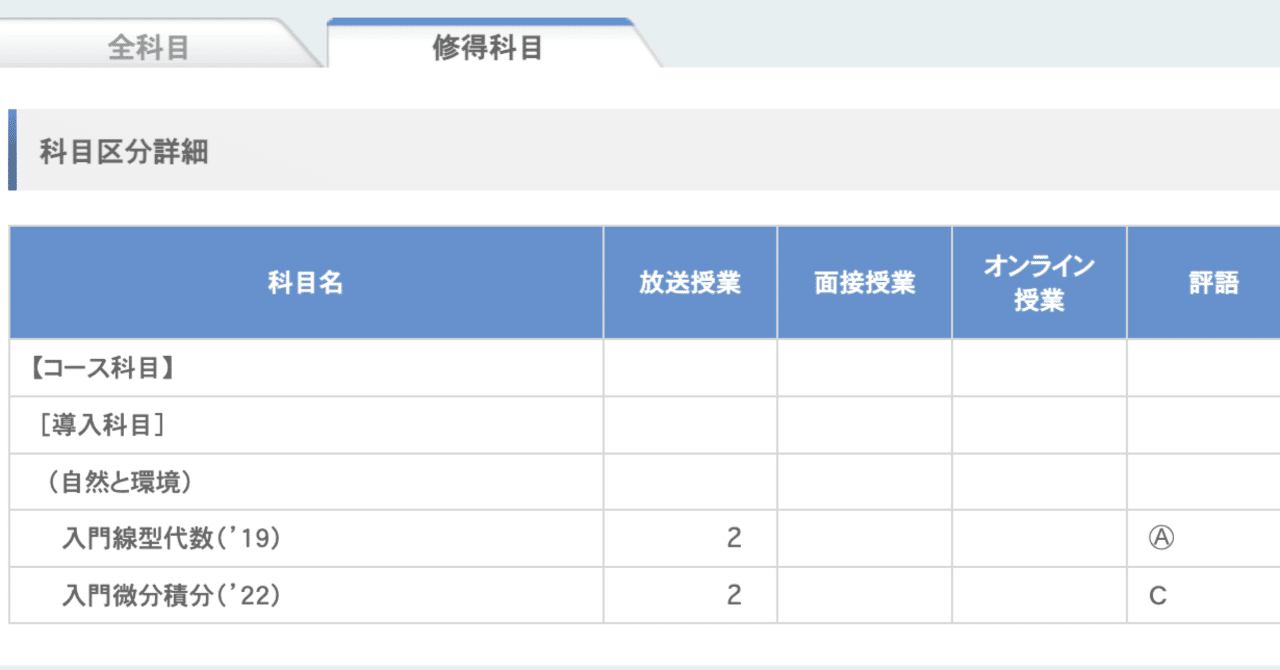
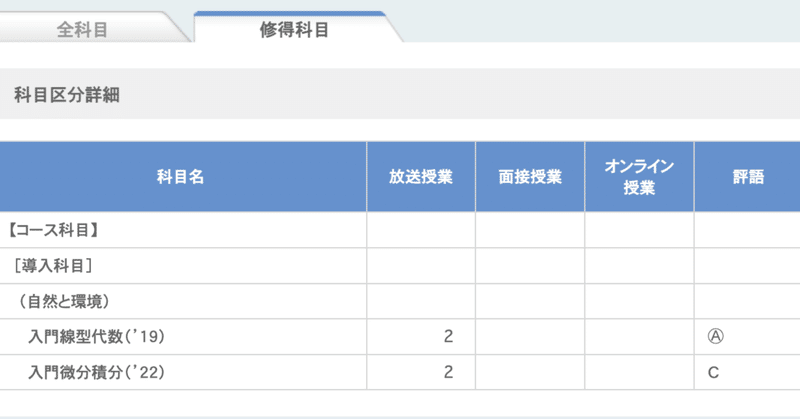
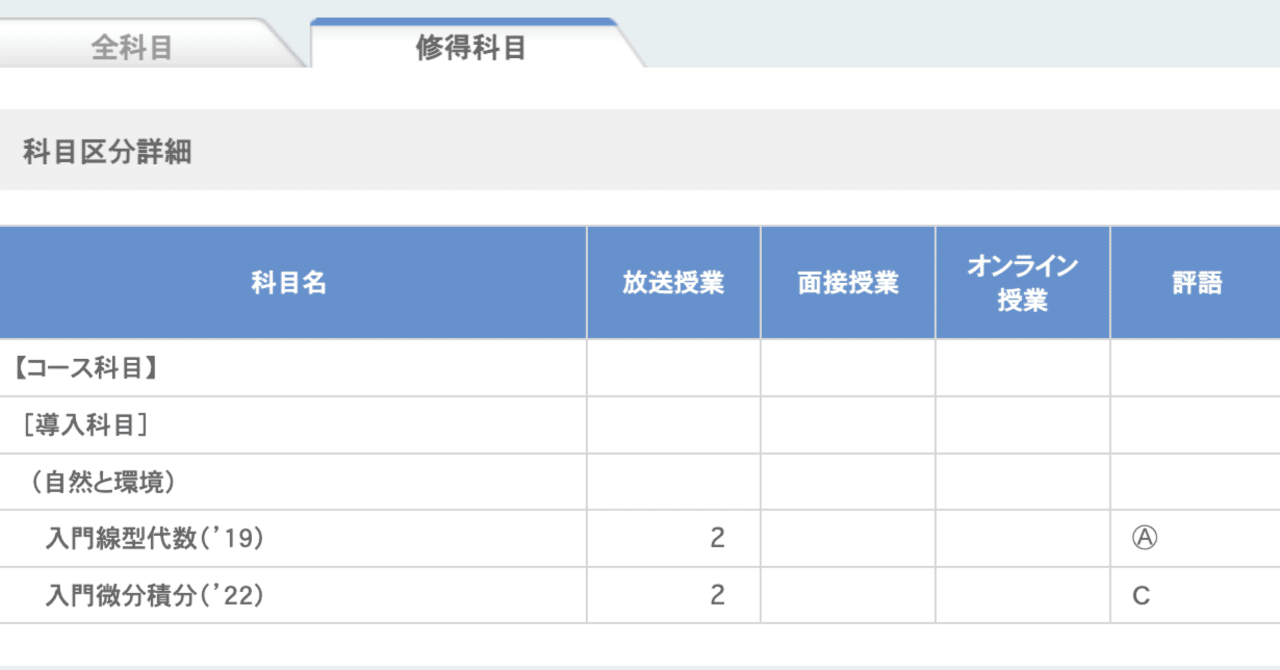
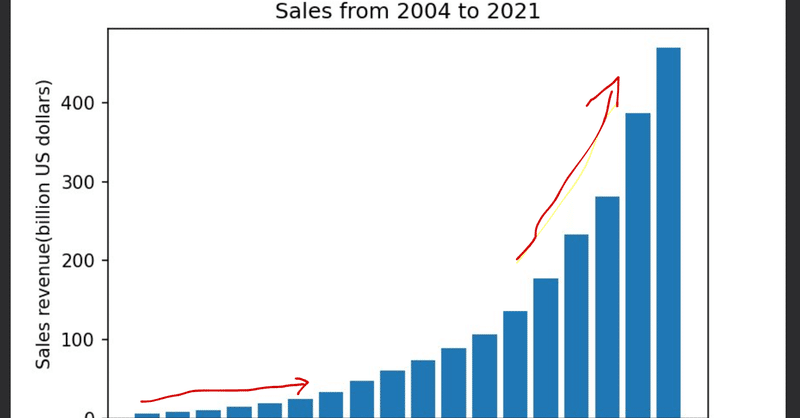
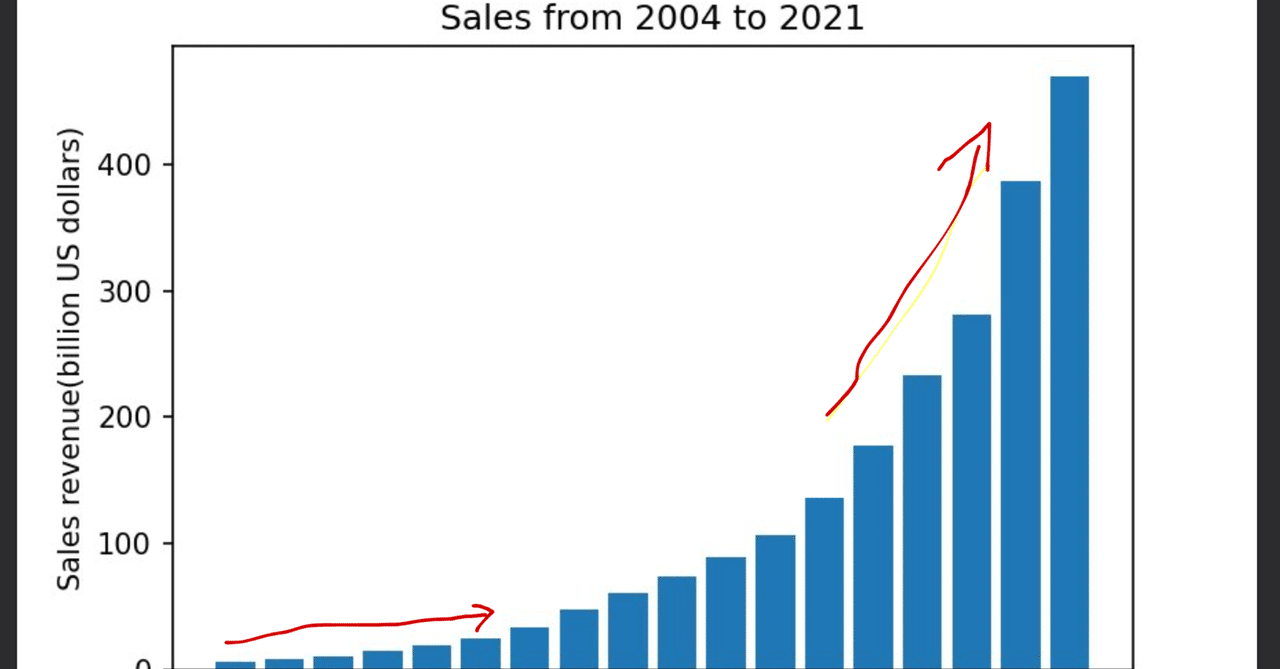
各要因の影響や、要因の組み合わせの影響を確かめる。(手段として交互作用項を導入し重回帰分析を使う)
Plan & Do【解答】
もちろんです。
まず、必要なライブラリをインポートします:
import pandas as pdimport statsmodels.api as smimport statsmodels.formula.api as smf
次に、DataFrameを作成します:
# データの準備data = { "joint_type": [1, 2, 3, 1, 2, 3, 1, 2, 3, 2, 1, 3, 2, 1, 3]*10, "