
分布の違い

どのような違いがあるか。

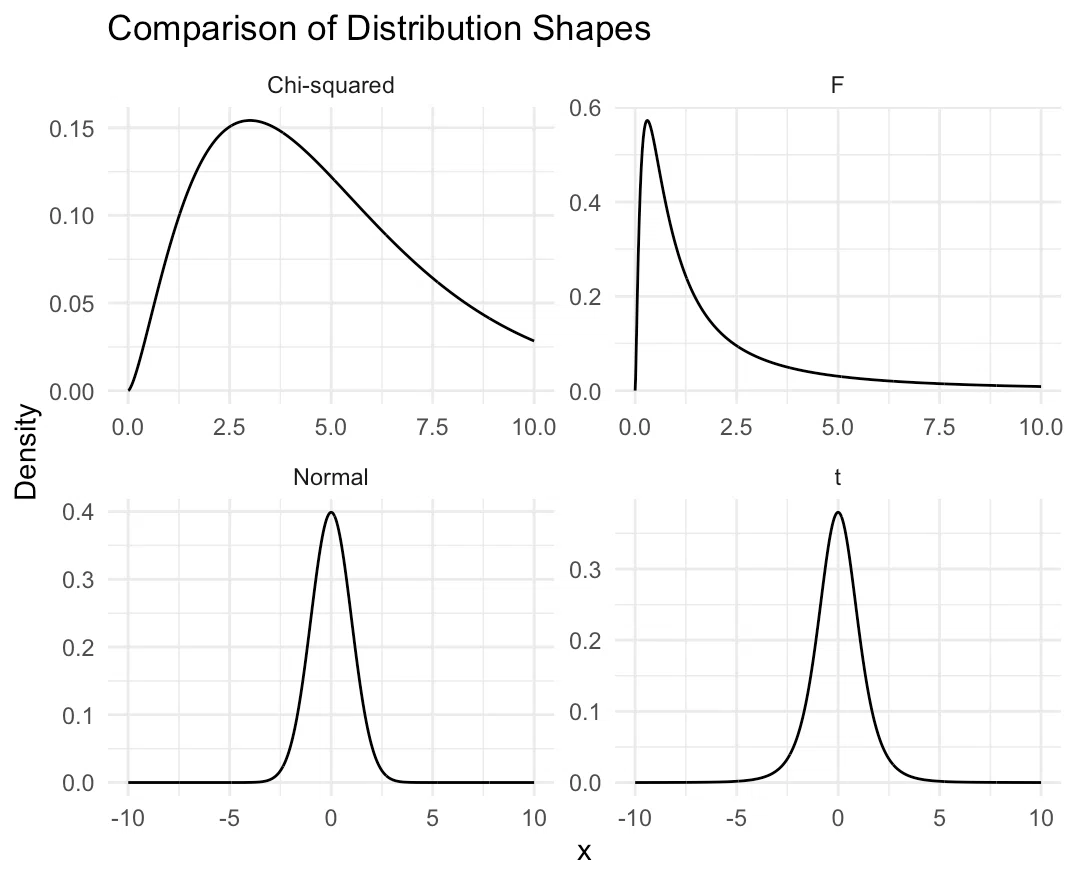
確かに、t分布と正規分布、F分布とカイ二乗分布はそれぞれ似ている特性を持っています。しかし、これらの各分布は独自の特性と適用範囲を持っており、そのためには重要な役割を果たしています。特に、統計的推定と仮説検定の文脈でそれらは頻繁に使われます。
正規分布とt分布: 正規分布は、中心極限定理により、大数の法則により平均値が正規分布に従うとされています。しかし、実際のデータ分析では、母分散が既知であるという仮定はしばしば成り立たないため、母分散が未知の場合の検定や区間推定にはt分布が用いられます。特に、サンプルサイズが小さい場合、t分布は正規分布よりも"厚い"裾を持つことで、より保守的な推定や検定を可能にします。
カイ二乗分布とF分布: カイ二乗分布は、正規分布に従う独立な変数の二乗和が従う分布で、分散分析や独立性の検定などに用いられます。F分布は、二つのカイ二乗分布の比から導かれ、分散の比較や分散分析に使われます。F分布は、母平均が等しいという仮説を検定する際に特に重要です。
つまり、これらの分布はそれぞれ異なる目的と状況に対して最適化されています。これらが似ているとはいえ、それぞれが統計的分析の特定の部分において重要な役割を果たしています。
具体例

確かに、これらの統計的分布は実社会のさまざまな現象やデータ分析に適用されます。以下に各分布の具体的な事例を挙げます。
正規分布
正規分布は、自然界や社会的現象に広く見られます。たとえば、人々の身長や体重、テストスコア、製造品の誤差などは、しばしば正規分布に近い形をしています。ビジネスの世界では、売上の予測や在庫の管理などに正規分布が使われることもあります。
t分布
t分布は、小さなサンプルサイズから母集団の平均を推定する場合に用いられます。たとえば、新製品の試験段階で少数の顧客からフィードバックを得て、全体の顧客満足度を推定するときに使われることがあります。
カイ二乗分布
カイ二乗分布は、観測値と理論値の間の適合度を評価するカイ二乗検定に使われます。たとえば、選挙の出口調査で、各候補者に投票した人々の割合が事前の予測とどれだけ一致しているかを評価するのに使われることがあります。
F分布
F分布は、2つ以上のグループ間の分散を比較する際に用いられます。たとえば、ある薬の効果を評価する際に、プラセボ(偽薬)を受け取ったグループと実際の薬を受け取ったグループの治療結果が統計的に有意に異なるかを評価するのに使われます。
これらの分布は、それぞれ異なる目的や状況で統計的な意思決定を行うために用いられます。それぞれが特定の問題解決に重要な役割を果たしています。
(参考) 正規分布、カイ二乗分布、t分布、F分布の比較グラフの出し方(R)
# 必要なライブラリの読み込み
library(ggplot2)
# x軸の値
x_norm_t <- seq(-10, 10, length.out = 1000)
x_chi_f <- seq(0, 10, length.out = 1000)
# 各分布の確率密度関数
norm <- dnorm(x_norm_t, mean = 0, sd = 1)
chi <- dchisq(x_chi_f, df = 5)
t <- dt(x_norm_t, df = 5)
f <- df(x_chi_f, df1 = 5, df2 = 2)
# データフレームの作成
df_norm_t <- data.frame(x = x_norm_t, Density = c(norm, t), Distribution = rep(c("Normal", "t"), each = 1000))
df_chi_f <- data.frame(x = x_chi_f, Density = c(chi, f), Distribution = rep(c("Chi-squared", "F"), each = 1000))
df <- rbind(df_norm_t, df_chi_f)
# プロット
ggplot(df, aes(x = x, y = Density)) +
geom_line() +
facet_wrap(~ Distribution, scales = "free") +
theme_minimal() +
labs(x = "x", y = "Density",
title = "Comparison of Distribution Shapes")
この記事が気に入ったらサポートをしてみませんか?