
【AIの作り方、回し方】 いまさら聞けない、でも知りたい。 AIってなんだ?(後編)

「日本はいつの間にかAI後進国になってしまった」—ソフトバンクの孫正義社長が、7月17日の「SoftBank World 2019」でこう発言したことが話題になりました。
AI(人工知能)について“自分とは無縁だ”と感じている人もいるかもしれません。しかし、AIは私たちにとってごく身近な存在です。AIエンジニアたちは「AIの研究は、人間の研究である」といいます。
*
4月25日に開かれたメディアセミナー「いまさら聞けないAI」を2回にわたりお届けしています。後編のテーマは「AIの作り方、回し方」です。ひきつづき、ABEJAのAIエンジニア大田黒紘之(おおたぐろ・ひろゆき)が解説します。
前編「AIの歴史と進化」
AIの作り方・回し方の基本
エンジニアはどうやってAIを作っているのでしょうか。「教師あり学習」という現在の主流の学習手法を使って、犬・猫の画像を判別するというケースを例に説明します。
「教師あり学習」は大きく3段階のプロセスがあります。

①教師データの作成・収集
機械学習の手法のひとつに、ニューラルネットワークという技術があります。ニューラルネットワークは人間の脳を模倣したモデルなので、人間と同じように学習させなければなりません。
そのためにまずは、「問いと答え」をセットにした教師データを数万、数十万個用意する必要があります。このとき重要なのは、教師データはどんなものでもいいというわけではなく、認識させたい物や解決したい問題に対して、適切かつ幅広い量と種類、パターンの答えを用意しなければならないということです。
この教師データをきれいに整える作業を、業界用語で「データクレンジング」といいます。データクレンジングは精度に大きく影響するのでたいへん重要な作業です。
②AIモデル設計・学習
次に、大量に作った教師データをコンピュータに与えて覚えさせます。重要なポイントは「与え方」です。
世界中のAIエンジニア・研究者によって、より効果的に覚えさせるための新しい手法が日々ネット上にオープンソースとして公開されています。それらの中から、自分たちが解決したい課題にあった手法を選別・応用して、AIモデルを設計するのです。
学ばせるための学習手法はいくつかあり、それぞれやり方は異なりますが、
用意した膨大な量の教師データから、AIモデルは、これは「犬」これは「猫」と判別するための特徴を捉えていきます。
③推論・評価
そうすることで、物体検出やデータの分析・処理などの現実世界の問題が解けるようになるのです。
AIを作って回すまでの作業量は膨大
いま説明したような流れをさらに分解すると、まだまだたくさんの作業があります。それを表したのが下の図です。

ニーズが高まっているAIエンジニアは、AIモデルの設計開発を担当する重要な仕事ですが、数あるプロセスの中の「モデル設計」しか担当していない場合が多いです。ほかの作業はすべてプログラマーやSEなどの一般的なITエンジニアが担当しています。
たとえば教師データを作るプロセスには、「データ蓄積」という作業がありますが、ひと口に「データ蓄積」といっても、やるべき作業は山のようにあります。
たとえば、
・データを蓄積するためのサーバーを用意する
・サーバーを管理するためのシステムを構築する
・セキュリティを保持するためのファイヤーウォールを用意する。
・ラベリングを管理するシステムを構築する。
などです。
また「推論・評価」でも、設計したAIモデルを実際に使おうとした時に、AIモデルを動かすためのサーバーやシステムを用意して顧客(企業)のシステムにつなげなければなりません。このような細々した作業が大量に発生するのでみなさんが想像する以上に大変なのです。
各工程のボリューム感
下の図は、各工程の作業量を簡単に比較したものです。

※図の引用元:https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf
AIを作る際の根幹になるAIモデルの設計・学習は、全体ではかなり少ない作業量です。それよりも教師データの収集、維持、管理のシステムや、AIモデルを顧客のシステム上で動かすための開発、監視、運用といった作業の方が比重が大きいことが見てとれます。
こういった現状を受け、データ収集やラベリングなどのさまざまなデータの管理や推論をするシステムをサポートするサービス、つまりAIの開発・運用を省力化、効率化を支援するサービスが世界中でたくさん生まれています。
AIの活かし方
ここでAIの導入事例を紹介しましょう。AIは汎用的な技術なので、小売、製造、広告、インフラ、医療、物流、金融、農業などあらゆる業界の課題に適用できます。
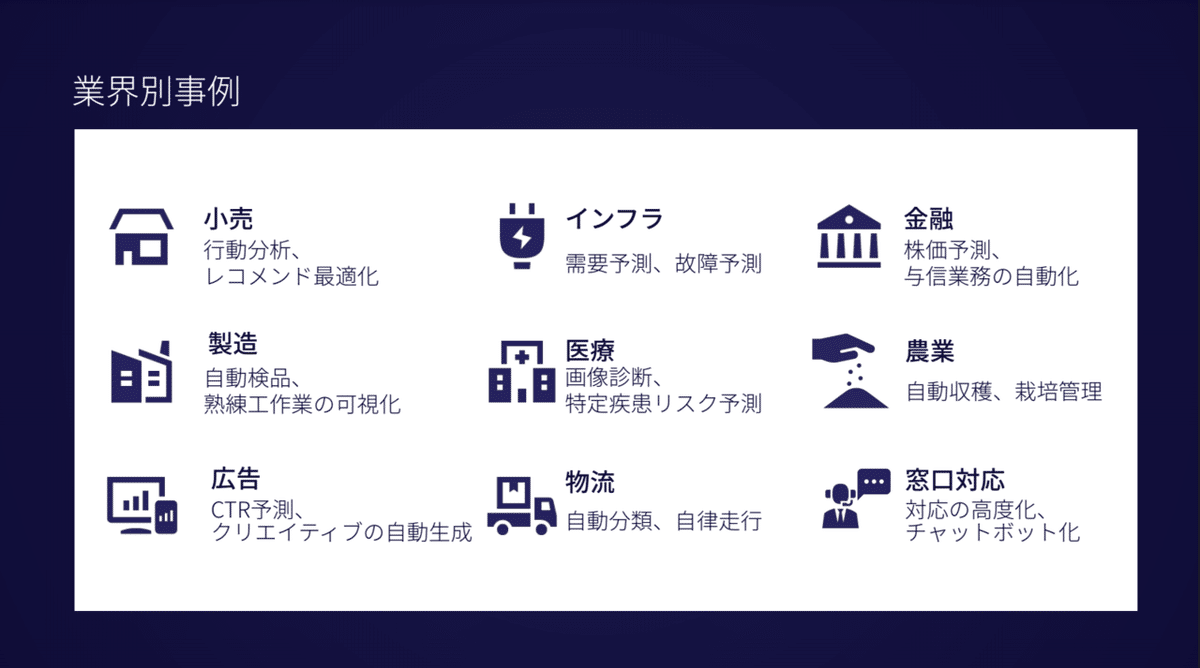
ABEJAの最近の導入事例では、人間の動作分析をするAIの開発があります。製造業の現場では生産性を上げるために、動作分析をして仕事中の動作への改善を図ってきました。
ただ、これまでは人間が工場のラインに張り付いて、作業員がどんな作業をしているのかをチェックしなければなりませんでした。これを支援、省力化する機能として、AIによって作業員がなにをしているのかを推定する動作分析のシステムを作り、工場への試験的導入を進めています(下図参照)。

またこれまでは、完全に自動化した工場でも最後の検品作業だけは人間に頼らざるをえませんでした。しかし、我々が作ったAIモデルに傷や凹み、欠損などの不良箇所の画像を覚え込ませ、ロボットアームとつないで部品の異常検知の自動化、省力化に成功しています(下図参照)。

さらに、小売流通業界でも店舗にカメラを設置して来店した顧客の顔を撮影することで、年齢、性別、来店回数などの情報を自動的に取得、分析するAIシステムも実際に開発しています(下図参照)。

AI市場で活躍しているプレーヤーとは
現在AI市場では、多くの企業が参入しています。
商品やサービスを生産・販売している事業会社の場合、自らAIを開発することが難しいのが現状です。そのため、あらゆる業界でAIを使った課題解決のために、SIer(システムインテグレーター)とよばれるIT企業が事業会社と協働して開発しているケースが多くあります。
例えばABEJAでは「PaaS (Platform as a Service)」という、さまざまな業界で使えるAIプラットフォームを提供しています。
AIは、いくつかの要素が積み重なってできています。AIプラットフォームを動かしているハードウェアやシステムがあります。AWSやGoogle、NVIDIAといった企業は、AIを効率的に動かすための計算チップやサーバー、インフラストラクチャを提供しています。このような各階層に存在する企業によって、最終的にAIを活用したサービスが生み出されています。
*
終了後の質疑応答(Q&A)の一部を紹介します。
Q. AIというと予測するものというイメージもあります。たとえば自動車運転での危険予測など。そうした予測の精度はこの数年でどのくらい進歩したでしょうか。
A.業界によってさまざまなパターンがありますが、より正しく、早く、安く予測するという意味では進歩しています。
自動運転の分野で人が突然道路に飛び出してくることを予測して自動車を止めるという技術がありますが、予測モデルの精度向上に加えて、高速推論をするためのハードウエア技術も進歩しており、ハードとアルゴリズムの両面からさまざまな取り組みが行われてます。
Q.AIモデルはブラックボックスといわれていますが、与えられたデータを正しく認識しているかどうかは調べてもわからないのですか?
A.自動で特徴量を捉えるディープラーニングのアルゴリズムは数値の塊でしかないので、人間が見たときにどこで判断しているのか、その根拠となるものは現状はわかりません。
しかし最近、その部分を可視化する研究は流行のテーマになっています。根拠がわからないままだと、分析を失敗すると甚大な損害を引き起こす分野では使えなくなるからです。このため、先ほどの自動運転の分野もそうですが、根拠がわかりつつあるアルゴリズムが増えてきているという現状です。
Q.AIによってジェンダーや人種の差別が再生産されるという指摘がありますが、どんなしくみで起きるのですか?そうならないための補正方法はありますか?
A.AIは技術の箱のようなものなので、入れるデータによって、箱から出てくるアウトプットの質が決まります。よって、ジェンダーや人種のバイアスが起こらないにするためには、まず、適切なデータと教師データの組み合わせを用意することが必要不可欠です。
ですが、集めたデータの中にはノイズが含まれていることが多々あります。そこからバイアスが生じる危険性があります。いかにノイズを減らしたデータを用意して、コンピュータに学習させるかが課題です。このため、データサイエンティストがデータを適切に評価、分析してバランスが取れているかを確認することで、適切なAIモデルの設計・開発を行なっています。
リアルな課題を解決するAIモデルの開発は非常に難易度が高く、さまざまな会社が苦労しているところです。しかし逆に言えば、そこがAIモデル開発者の腕の見せどころでもあります。
Q.AIモデルを設計するためにコンピュータに与えるデータの種類は画像が多いのですか?お話によるとその画像に適切な答えをセットでつけなければならないとのことですが、その作業は具体的にどうやっていますか?
A.問いと答えがセットになった教師データの作成・収集は人の手で行っています。その作業を「アノテーション」といいますが、画像を10万枚、100万枚と作らなければならず、自前でやるにはとても大変です。このため、アノテーションを行うためのツールや人材を提供して教師データづくりが手軽にできるサービスを利用する企業も多いです。
Q.画像の教師データ作成に関してはアノテーションツールなどのしくみができて省力化されていますが、音声場合も教師データは人が作るのですか?
A.人が作っている会社が多いと思います。ただ、データは画像のほかに、音声や動画、文章が写った画像などいろいろあります。それらをすべて人がやるのは本当に大変なのです。
Q.AIのアルゴリズムは人がコードを書いているのでしょうか?
A.今はアルゴリズムを作るためにエンジニアがいちからコードをガリガリ書いているわけではありません。以前はそのような時代もあったのですが最近はGoogleやMicrosoftなどがさまざまなライブラリやフレームワークを作ってくれています。エンジニアは、ある程度モデルの形や学習の仕方を選択するだけでアルゴリズムが作れるしくみが整ってきているのです。
Q.AI開発を手がける会社はたくさんあると思うのですが、技術力の差はどのあたりでつくのでしょうか?
A.顧客の業界の知識が乏しいと実用に耐えられるAIモデルを作ることは難しいでしょう。その業界に関する知識や経験の有無が重要なポイントです。
最近はネット上にAI作成に関する論文やそれを動かすために必要なプログラムやライブラリ、フレームワークなどがひと通り公開されています。AI技術がコモディティ化しているので、誰でもAIに触れられて、ある程度の知識があるエンジニアなら1週間もあれば画像認識や人物検出ができるAIモデルを作れる時代になっています。
ネット上のサンプルをそのままAIモデルに使う会社と、独自にカスタムして細かいところまできちんと適用できる会社とでは技術力に大きな差が出るでしょう。
顧客の課題をAIモデルが一発解決するというよりは、ツールとして使いながら顧客のビジネスを支援するような機能を一緒に作れる会社が強いと、個人的には思います。

解説者:大田黒紘之
ABEJAの開発チーム・リーダー。産業技術高専卒業後、首都大学東京に編入学。高専在学中は、超小型人工衛星の開発、医療機器に関する研究に携わる。現在は、小売流通業向けの店舗解析サービスABEJA Insight for Retailの事業部に所属し、IoTデバイスからPlatformの開発及び運用まで、幅広く担当している。
取材・文・写真:山下久猛 編集:川崎絵美

Torus(トーラス)は、AIのスタートアップ、株式会社ABEJAのメディアです。テクノロジーに深くかかわりながら「人らしさとは何か」という問いを立て、さまざまな「物語」を紡いでいきます。
Twitter Facebook
【Torusの人気記事】
未来食堂・小林せかいさんが向き合う 「正しさ」への葛藤
「貧困の壁を越えたイノベーション」。湯浅誠がこども食堂にかかわる理由
「当事者のエゴが時代を変える」。吉藤オリィが参院選で見たある風景
人気ブックデザイナーが考える 「いい装丁」とは?
イタリア人医師が考える、日本に引きこもりが多い理由
「僕は楽しいからそうする」。大学の外で研究する「在野研究者」たち
「性欲は、なぜある?」が揺るがす常識の壁
この記事が気に入ったらサポートをしてみませんか?