
教育データサイエンスを駆使してABテストでアダプティブ遷移のアルゴリズムを改善した話

こんにちは!株式会社COMPASS 取締役の常盤です。COMPASSは「新しい学びの環境を創り出す」をミッションに掲げ、小中学生に対してAI型教材Qubena (キュビナ)を提供している会社です。
前回のnoteでは、データ・AIユニットという組織を立ち上げて、データ分析基盤を整備し、AIをワークフローに組み込むことでアウトプットを2倍にも3倍にもしていく取り組みを紹介しました。今回のnoteではデータ・AIユニットのもう一つの中核機能、教育データサイエンスの業務について書いていこうと思います。
教育データサイエンスとは
まず最初に教育データサイエンスとは何ぞや?について書きます。一般的な定義をいくつか調べてみると、国立教育政策研究所では「統計学とコンピュータサイエンスだけでなく、教育理論と教育実践が結びついて成立するもの」とし、以下のように紹介をしていました。

具体的な業務の例では、データのプラットフォームの構築、CBT(Computer Based Testing)の研究、データ利活用の為の恊働などが挙げられています。この整理は非常にわかりやすく、COMPASSでの想定と近いものがあります。
COMPASSの組織体制
データ・AIユニットは次の構成です。データ・AIユニットの中に教育データサイエンス部とR&D部があります。R&D部はLLMの活用や文字認識エンジンの改善等を行う組織で、こちらは別の機会に紹介できればと思います。

COMPASSの教育データサイエンス部の業務は以下のようになっており、国立教育政策研究所の例に近いです。
データエンジニア…データ分析基盤の構築・運用。
データアナリスト…データの活用方法の立案やデータ分析の実施。分析結果より得られる客観的なデータに基づいた意思決定の支援。
ドメインエキスパート(教育)…教育理論や教育実践の研究調査の実施。研究調査から得られる専門的な知見に基づいた意思決定の支援。
基本的にはこの3領域の専門性を持つメンバーによって業務を推進しています。ただ、複数の領域を1人のメンバーが対応可能なこともありますし(例: 統計に強い教育のドメインエキスパート)、お互いの領域を越境しながら恊働することが一番の理想形で、そこを目指して努力をしています。
さて、次は具体的なその業務事例について紹介します。
アダプティブ遷移のアルゴリズムでABテストを実施
私たちが開発しているQubenaは、生徒1人ひとりの解答データや過去の学習履歴からAIが間違いの原因を特定し、つまずきの原因となった問題に立ち返って復習をすることができるのが大きな特徴の一つです。
この誤答時に復習問題へ遷移することを社内では「アダプティブ遷移」と呼び、高い学習効果を生み出す核の機能となっています。非常に重要な機能かつ、仕様の複雑さも高いため、そのアルゴリズムを変更する判断は難しく、客観的なデータに基づいたアプローチが必要不可欠です。こうしたところが教育データサイエンスが活躍する場面です。実際に直近のロジック改善ではABテストを用いて改善方針を決定することにしました。その事例を紹介します。
仮説の構築
まず最初にアルゴリズムの改善案の仮説を検討しました。具体的な内容は公開することができませんが、「教育理論と教育実践」「統計」「コンピュータサイエンス」の3つ領域のバックグラウンドを持つメンバーで検討し、例えば、過去のすべての学習履歴を反映した習熟度の数値をより重視して遷移先を決めるアプローチ、逆に直近の問題の間違え方をより重視して遷移先を決めるアプローチ等、様々な角度の仮説を構築していきました。こうした仮説がABテストの各グループ群になります。
ABテストの標本のサイズを決定
Qubenaの問題は非常に多いため、全数調査を行うのは現実的ではありません。そこで、特定の教科を選択して標本調査を行うことにしました。今回の調査で対象にした教科は算数・数学です。Qubenaの算数・数学の問題数は約2万問あるため、下記を参考に標本サイズを96問と決定しました。もちろん精度を高めるには標本サイズが大きければ大きいほど良いのですが、実施可能な工数を勘案しての結論です。
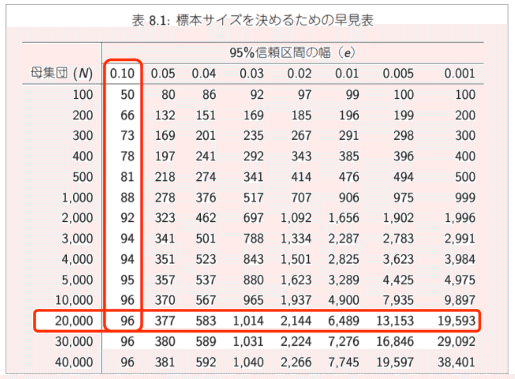
この次に、標本の問題に対して何通りでのテストをすれば良いのかを検討しました。Qubenaのアダプティブ遷移は、各学習要素の習熟度や問題の間違え方に応じて異なる遷移先を選択するため、そのバリエーションは膨大な数になります。最終的な結論としては、64通りにしました。詳細な算出方法の説明は割愛しますが、これはt検定を用いて2つのグループの平均値の差が統計的に有意なものかどうかを判断するときの最もリーズナブルな値です。標本96問との掛け算になるため、96問 × 64通り = 6,144ケースでの検証です。
この標本サイズでは、大きな差分を検出することになるため、まずはABテストを実施をしてみて、大きな差が検出されない場合は、さらに標本サイズを大きくして詳細な検証を続けるかどうか判断するとしました。
標本の抽出方法
標本のサイズが決まったところで、実際に標本の抽出作業を行います。標本はいわばQubena本体のミニチュア版です。Qubenaの性質を維持したまま96問の問題を選択しなければいけません。改めてQubenaに搭載されている問題に目を通して、特に遷移先の観点で類するグループになるように分類をつけていきます。最終的には各グループの比率をQubena本体と変えずにミニチュア版である標本を作成します。

一方で、人間が約2万問の問題すべてに目を通してグループに分けるのは現実的ではありません。大枠の分類に当たりをつけて、あらかじめコンテンツに付与されているメタデータを確認し、利用できるものがないか探します。今回の検証では偶然ピッタリのものが見つかりました。改めてQubenaのコンテンツには豊富なメタデータ付与されているのがプロダクト開発における強みになっていると感じます。
標本が完成すれば、各問題ごとに64通りのテストケースのデータをランダムに出力していきます。例えば、問題Aを解くために必要となる学習知識がそれぞれどういう習熟状態であるか、その上で問題Aでどういう間違え方をしたか等、実際の生徒の学習状況を忠実に再現したテスト用のデータを作成していきます。まさに「教育理論と教育実践」「統計」「コンピュータサイエンス」の恊働によってABテストの準備を進めていきました
ABテストの実施
さて、いよいよABテストの実施です。繰り返しになりますが、アダプティブ遷移の質はQubenaの核の機能であり、適切な復習問題であることを機械的に評価することの難しさもあり、Aグループ、Bグループに対して人の目で評価をつけていくことにしました。
一方、人間が介入することでより復習問題としての教育体験の良さを定性的に評価できるようになりますが、評価者のバイアスによって結果に歪みが生まれてしまう可能性もあります。そこで、評価者は合計4名によって構成し、評価の基準を繰り返しシミュレーションして揃えました。評価自体は、ピッタリの復習問題であれば「高」、的外れな復習問題であれば「低」のように非常にシンプルなのですが、以下のような資料を用いて、どういう状態がピッタリの復習問題なのか?という認識合わせを徹底しました。

この状態で、96問 × 64通り = 6,144ケース に対して一つずつ「高」や「低」の評価をつけていきます。人間が評価する以上はそれなりに時間もかかりますが、客観的なデータに基づいた意思決定が重要であるという共通理解を持っている人が社内に多く、スムーズに「これは必要な投資である」という合意形成を行うことができました。

ABテストの結果を受けての意思決定
ABテストが完了したら、その結果を受けて意思決定を行います。もともと今回の標本サイズでは、統計的には大きな差しか検出することができないため、有意な差が出ているとは言えないことも考えられました。その場合は、標本サイズを大きくして検証を続行するか、現時点の検証内容をもとに判断を下すか等を決める必要があります。
今回は特出して優れた結果となったグループがあったため、定量的にも定性的にも問題なく結論に至ることができたのですが、ビジネスの現場ではすべてが理想通りに検証を行えるとも限らないため、臨機応変かつ積極的に教育データサイエンス部から代替案等の提案を行い、よりよい意思決定ができるように活動しています。
終わりに
以上、「教育データサイエンスを駆使してABテストでアダプティブ遷移のアルゴリズムを改善した話」でした。かなり実際の業務に踏み込んでnoteを書きましたが、教育データサイエンスの現場の面白みを感じてもらえたら嬉しいです。自分たちの取り組みが公教育の現場をより良いものに変えていく実感が得られて非常にやりがいのある仕事です!
もし私たちの取り組みに少しでも興味を持ってもらえたら、ぜひ以下よりカジュアル面談のお声がけをください。ざっくばらんにお話ししましょう!
早速応募したいよ!という方はこちらへどうぞ。
まずはCOMPASSのことをもっと知りたいという人は公式noteをぜひご覧ください!
この記事が気に入ったらサポートをしてみませんか?