
データとAIの活用でEdTechの活動を加速させ、日本の教育をさらに良くする挑戦を始めます

こんにちは!株式会社COMPASS 取締役の常盤です。COMPASSは「新しい学びの環境を創り出す」をミッションに掲げ、小中学生に対してAI型教材Qubena (キュビナ)を提供している会社です。
気がつけば1年以上振りのnoteの更新になってしまいました。以前はピープル&カルチャーの人間として情報発信をしていたのですが、実はGPT-4が登場した2023年3月のタイミングでR&D室に管掌を変えて、それ以降はLLMに関連する仕事をしていました。そこでの様々な試行錯誤を経て、一定の筋道が見えてきたこともあり、この度新たにデータ・AIユニットという組織を立ち上げて、本格的に会社としてLLMを中心としたAI技術の活用をしていきます。このnoteではその具体的な内容について書いていきます。
なぜデータ・AIユニットなのか
LLMを中心と言いながらも、組織名の先頭に"データ"を持ってきたのは理由があります。それはLLMがデータとの組み合わせによって真価を発揮すると考えているからです。簡単になぜこの考えに至ったのか思考のプロセスを説明します。
LLMの汎用性の高さが秘める可能性
ご存知の通り、LLMは、プロンプトの内容に合わせて、文章要約、翻訳、プログラミング、データ分析…と多種多様なタスクを実行することができます。ChatGPTに慣れ親しんだ今となっては当たり前に感じることですが、これは本当に凄いことです。
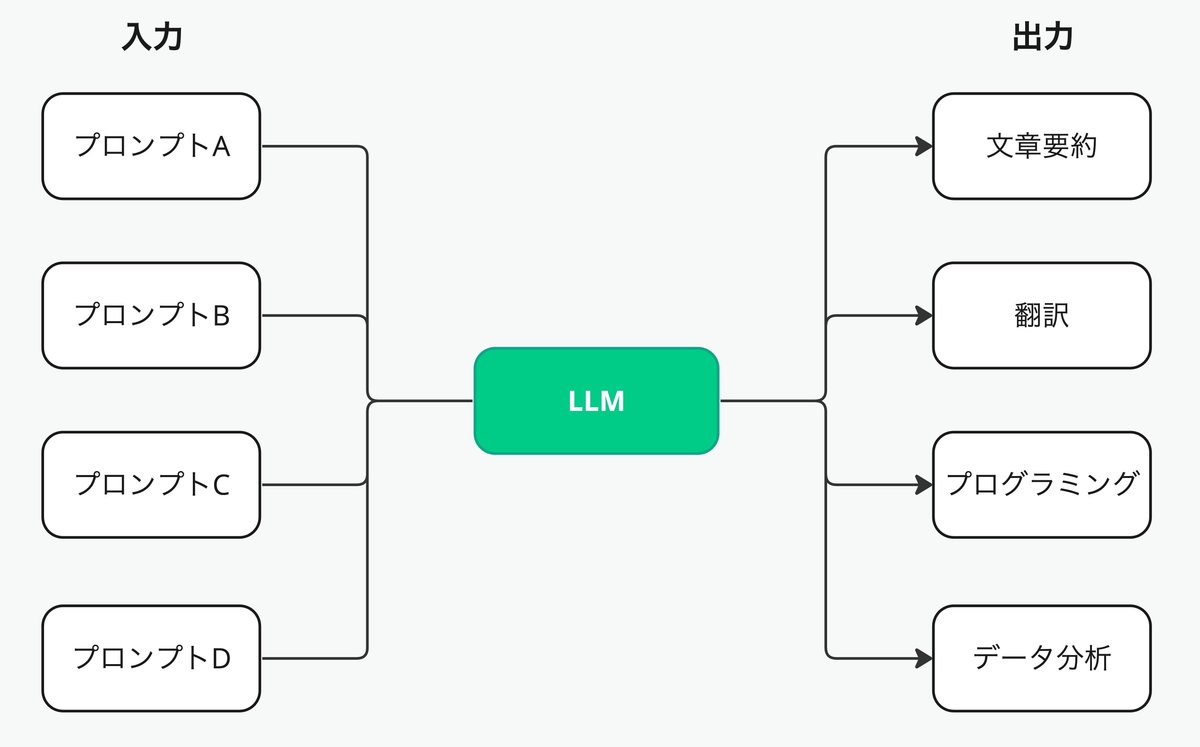
例えば、とある営業会社で見込み客との商談記録から成約率を予想してランク付けをしていく業務があったとします。少なく見積もっても1件あたりの商談記録を読んで成約率のランクをつけるのに15分はかかるでしょう。もし見込み客の数が5000件あれば、75,000分、つまり156人日の作業になります。営業社員でこの作業を実施するのは厳しい、エンジニアに自動化してもらうにも工数がないと言われる、こうなったら営業事務でパートの方を採用して何とか対応するか…。LLM登場前にはこのような話しがよくありました。
しかし、LLM登場後では、商談記録から成約率を予想するプロンプトを作成すれば、LLMがほんの数秒もあれば成約率のランクを出力してくれます。もちろんLLMは疲れ知らず、24時間働いてくれます。自動化をするにあたって、商談記録を読み取る、LLMのAPIに渡す、レスポンスをランクとして書き込む、という最低限の開発をすれば実現できてしまいます。
これはただの一例に過ぎず、LLMの汎用性の高さは、私達がデスクワークをする上で遭遇するおおよそ全てのタスクを吸収してくれる可能性を秘めています。
LLMへのインプットの対象は拡がっていく
ChatGPTが登場した2022年11月、インプットとして受け付けられるデータ形式はテキストのみでした。しかし、2024年1月時点では、画像と音声もインプットの対象に拡がっています。
以下はGoogleが2023年12月に公開したGeminiというLLMのデモ動画の一つです。実はGoogleのデモ動画には編集が入っていて動画通りに動くものではないという指摘が入って話題になったのですが(例: 世界を驚かせたGoogleのAI動画、実はあんなにサクサク動きません)、LLMの将来的な可能性を示すという観点で、私はとても興味深く見ていました。この動画には、手書きの答案用紙を画像でアップロードすると、LLMが計算式までを分析してくれて、なぜ間違えているのかを解説してくれる様子が写っています。
そう遠くない未来で、画像や音声だけでなく、動画ファイルがLLMのインプットとして使える日もやってくるでしょう。
プロンプトのコモディティ化とデータでの差別化
LLMの推論能力はどんどん進化しています。OpenAIのGPTでは、GPT-3.5ではアメリカ司法試験を受けさせると下位10%程度の成績だったのに対して、次のGPT-4では上位10%に入るほどの成績を残すようになったとのことです。GPT-4.5も近い内にリリースされるという声もあり、LLMの進化にはますます目が離せない状況です。
さて、この推論の変化によって何が起きているのでしょうか。私が強く感じるのはプロンプトのコモディティ化です。GPT-3.5の頃はLLMがなかなか期待通りの出力をしてくれず、指示を作り込むことで何とか制御を試みたものです。プロンプトエンジニアという職業が生まれて新たな稼げる職業になる!というニュースを目にすることも多かったです。
GPT-4が登場すると、依然としてシンプルでわかりやすいプロンプトであることの重要性は変わりませんが、ある程度の雑な指示でも意図を汲んでくれるようになりました。さらに推論能力の高いモデルではもっと雑なプロンプトでも期待通りの出力をしてくれるようになるはずです。

そうした未来では、どのようにお願いするか(=プロンプト)の優位性はなくなり、誰でもLLMのメリットを享受できるようになります。そうなれば、優位性になる大きな要因は、何をお願いするかです。例えば、心拍数、心電図、血中酸素濃度、血糖値、食事内容、睡眠時間、歩数などのヘルスデータがあれば、医学的に具体的な指示を出せなかったとしても、「このデータを見て健康的な問題があれば教えてください」という雑な指示を与えるだけで、潜在する健康リスクを指摘してくれるようになるでしょう。
これがLLMはデータとの組み合わせによって真価を発揮するということだと考えています。私たちがデータ・AIユニットという組織を立ち上げる意思決定に繋がった理由です。
データ・AIユニットで何をするのか
COMPASSは公教育の市場で事業を行う会社です。公教育でのデータやAIの利活用は、一般的なBtoCの事業に比べて、遵守する法令やガイドライン等の厳しさが異なります。残念ながら早速プロダクトにLLMを取り入れて…というわけにはいきません。LLMがICT教材で当たり前に利用されるのはまだしばらく先になるでしょう。なので、まずは私たちが開発をしているプロダクトやコンテンツを創り出す精度や速度を高めるためにデータとAIを利用していくことを考えています。
データ分析基盤を刷新する
まずはデータ分析基盤の刷新に注力します。COMPASSにはすでにデータ分析基盤があり、それなりに運用も上手くいっていると思うのですが、まだまだ改善の余地が残っています。
例えば、現在のデータ分析基盤はプロダクトに関する各種 のデータは充実しているのですが、CRM (Customer Relationship Management) や VoC (Voice of the Customer)等のビジネスに関するデータとの接続が上手くできているとは言えません。もしこれらがシームレスに接続できていると、プロダクトで機能Aをリリースした後にビジネスにどういう影響があったのか、あるいは逆に、ビジネスで施策Aをとった後にプロダクトにどういう影響があったのか、等の分析が可能になってきてます。

また、LLMの登場によって、非構造的データをデータ分析基盤に取り込める可能性があると考えています。前述でも例に挙げましたが、セールスやカスタマーサクセスの担当者の所感は重要な情報源になりえます。しかし、人が残すメモを構造的データに変換して扱うのは非常に骨の折れる作業でした。これをLLMが人のメモを読んで解釈を行いフォーマットを整備してくれることで、データ分析基盤で扱える対象が拡がっていくと考えています。このようなデータ分析基盤の刷新ならびに継続改善に投資をしていくつもりです。
ワークフローをAIで半自動化!LLMが分析し、改善する
データ分析基盤の整備が進めば、本格的にワークフローへLLMを導入していきます。LLMと言えばChatGPTのイメージが強く「チャットをしてアウトプットを出力させるのではないの?」と考える人もいるかもしれません。しかし、私は現時点ではワークフロー内に存在する人間にしか出来ないと思われている定常業務をLLMに置き換えていくアプローチが有効であると考えています。
例えば、ICT教材の開発業務で定常的によく発生するものに、コンテンツの運用保守があります。ユーザーの皆様から「この問題の正解にxxを追加して欲しい」「あの問題の質問文の□□を変更して欲しい」等の問い合わせや要望を頂いた際に、該当の問題のどこに課題があるのかを分析し、修正を行います。こうした作業はこれまで人間が行ってきましたが、作業内容が「正解追加の場合はその答えが正答として成立しているか検算する」のようにある程度は限定できるため、一定の業務の標準化がなされていれば、LLMがその業務を代わりに実施することも可能であると考えています。
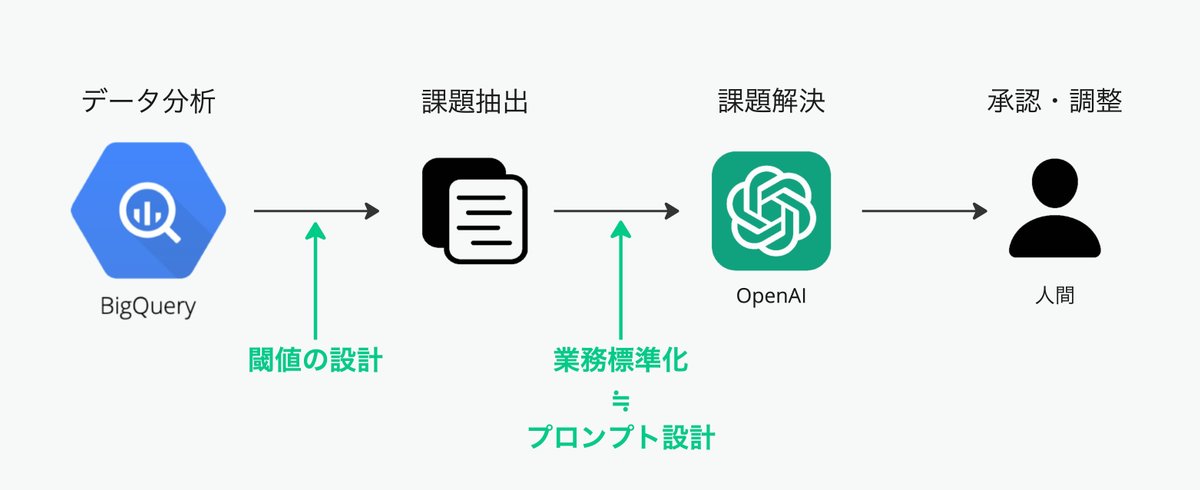
データ分析基盤を利用して、課題を抽出するためのデータ分析を行い、そこで抽出したものに対して、LLMが課題解決を行い、その結果を人間が承認します。もしそのまま承認ができない場合は、人間が手直しをするのに合わせて、業務手順書とプロンプトにも手を加えることでワークフローに磨きをかけていきます。そうすることで人間の手が介在しない割合が高まっていき、最終的には現在の何倍ものスピードでアウトプットが出せるようになる想定です。人間はより意思決定と業務設計に集中していきます。
こうしたワークフローのAIによる半自動化を、各部署と一緒になってデータ・AIユニットで推進していければと考えています。前述の例はICT教材の開発業務でしたが、ビジネス × データ・AI、プロダクトマネジメント × データ・AI等、様々な領域で実践可能なものなので、優先順位をつけながらも全社的にデータ・AIドリブン化を進めていくのが私たちが行う仕事です。
終わりに
以上、「データとAIの活用でEdTechの活動を加速させ、日本の教育をさらに良くする挑戦を始めます」でした。ここ数年で企業での働き方が大きく変わることは間違いないと思います。その変革期のなかで、データ・AIの仕事ができることにとてもワクワクしています。これが実現できれば、日本の教育をさらに良くしていくスピード感が増していくと感じます。
これから本格的に採用活動を始めていくのですが、私たちの取り組みに少しでも興味を持ってもらえたら、ぜひ以下よりカジュアル面談のお声がけをください。ざっくばらんにお話ししましょう!
早速応募したいよ!という方はこちらへ
まずはCOMPASSのことをもっと知りたいという人は公式noteをぜひご覧ください!
この記事が気に入ったらサポートをしてみませんか?