
ビジネスでの画像生成AI活用: 画像生成AIの大まかな流れを辿ろう

可能性に満ちる画像生成AI
発達を続けるテクノロジーの中でも、画像生成AIは特に注目される分野の一つだ。
最近、画像生成AIを使ったビジネスのニュースを見つけて、趣味の範疇からビジネスでも活かせるということがいよいよ現実になってきたことに衝撃を受けた。
結論から言うと、画像生成AIはビジネスにおいてとてつもない可能性を秘めている技術といえる。
生産性の向上はもとより、コストの削減やビジネスチャンスの創出など、現時点で分かっているだけで言っても複数の大きなメリットがある。
そこで今回は、画像生成AIの成り立ちや、ビジネスシーンでの画像生成AIのメリット、具体的な活用例についてなどについて詳しく解説していこう。
私もほんの数日前にChatGPTのサブスクリプションに登録したばかり。これが自分の執筆活動にどう活かしていくべきなのかを絶賛検証中なので、生成AIについて少しでも勉強するにはいい機会だと思ったので、皆さんも良ければ私の勉強にお付き合いいただけたら嬉しい。
では早速いこう。
画像生成AIが持つ大きな可能性
冒頭でも言った通り、画像生成AIはビジネスにおいてとてつもない可能性を秘めている。
なぜそんなことが言えるのか?まずは画像生成AIが普及するまでの大まかな流れについて説明していこう。
最初は難しかった画像生成
画像生成AIは、2021年〜2022年あたりから注目を浴び始めた生成AIモデルの一つ。
主に深層学習と呼ばれる技術を使って、インターネット上の画像をデータセットにしながら独自の言語モデルと組み合わせることで、人間が求める画像を文字で入力して送信すればその指示にかなり近い特徴を持った画像が出力されると言う仕組みだ。
画像生成AIという技術自体は、学術研究などの場でもっと前から使用されていたのだが、2021年にOpenAIという企業が「DALL-E」と呼ばれる言語モデルを開発し一般公開したあたりから動きが出始める。
どんな動きか?一言で言うと、画像生成の民主化だ。
それまでの画像生成というのは、AIを専門で研究する学者や学術機関、あるいはプログラミングの知識が豊富なエンジニアやプログラマーといった一部の技術者でないと扱うことが難しかった。なぜなら、画像生成を扱うためには、深層学習やアルゴリズム、プログラミング言語の理解といった知識が必要だったからだ。
私も昔プログラミングスクールでPythonを使った画像生成を学んでみたことがあるが、その当時は今のChatGPTのようにブラウザやアプリからプロンプトを入力するようなやり方ではなくて、AWSのCloud9やJupyter Notebookといった開発環境を使い、Pythonというプログラミング言語の*Pillow」とか「Imageio」といった画像解析・加工用のライブラリというものを使用して画像生成を行っていた。
何をいってるかよく分からないと思うが、要するにプログラミング言語の中で画像生成する必要があったのだ。
だから、画像生成に必要なライブラリがどれか?とか、プログラミング言語のルールに則って画像を生成するにはどういう構文にしたらいいか?など、画像生成する前の下準備に関する知識が必要だった。その背景もあり今までの画像生成というのは、プログラミング言語のライブラリや開発環境を熟知している専門的な技術者や学者しか扱えなかったのだ。
誰もが画像生成できる時代に
ところがその流れが変わったのが2021年。
OpenAIというアメリカのベンチャー企業が「DALL-E」と呼ばれる言語モデルを開発した。これがいわゆる画像生成のためのAIで、これが一般に公開されたことでそのモデルを使って画像生成のサービスを開発しようとする企業が次々に現れた。
その中でも代表的だったのが、「Midjourney(ミッドジャーニー)」というサービス。2022年の7月にDiscordというチャットサービス上でベータ版を公開し、Discordのチャットに希望する画像について指示した文章を送ることで、指示に沿うような画像が4パターン表示されるというものだった。
これが爆発的な話題となり、画像生成AIが瞬く間に普及することになる。
Midjourneyの画期的だったところは、やはり画像生成を誰でも簡単に行えるようにしたこと。
それまでの画像生成というのは先ほども言った通り、開発環境ツールからプログラミング言語を指定してライブラリをインストールし、画像生成のための構文を記述して初めて行えるものだったので、プログラミングを知らない人からするとハードルが高かった。
かつ、画像生成できたとしても、せいぜいオリジナルの画像に少し変化が加わった程度。だから画像生成をする目的といったら、画像の中の色やピクセルを分析するような解析作業に役立てるくらいで、今のようにエンタメとして利用できるものではなかった。
ところがそれが、DALL-Eという高精度な言語モデルの登場とそれを組み込んだMidjourneyというサービス、2つのダブルパンチによって、プログラミングの知識がない人でもチャットひとつで簡単にクオリティの高い画像を生成できるようになったのだ。
一気に火がついた画像生成AI
そこから画像生成の進化は止まらない。
Midjourneyの登場とほぼ同時期の2022年8月にはDALL-Eに続く言語モデルとして「Stable Diffusion」が登場。こちらはドイツのミュンヘン大学の研究チームが公開した画像生成用のAIで、Midjourneyをはじめ多くのwebアプリやローカル環境で使用されいき、同じように反響を呼んだ。一時期は「DELL-E」「Stable Diffusion」「Midjourney」の3つがXのタイムラインに溢れていたほどだ。
現在はMidjourneyもサブスクリプションによって有料で利用することできるようになったり、私が現在試行錯誤しながら利用しているChatGPTも、直接画像を生成することはできないが、画像を読み込んでそれがどんな様子を表しているかを解釈するという機能は持っている。
例えば以下の画像は、20世紀の画家・カンディンスキーという人が書いた「Composition VII」という作品。これを何の事前情報も与えずChatGPTに解釈させるとどうなるのか?
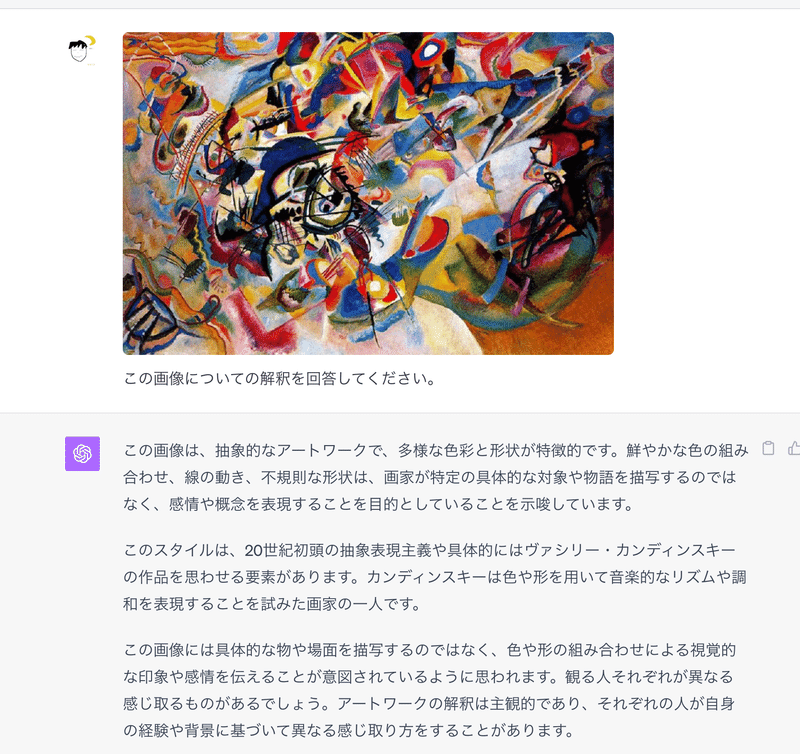
「カンディンスキー」や「抽象画」という情報は一切与えていないにもかかわらず、これがカンディンスキーの作品のようだと解釈できるというのは、かなり精度が高い言語モデルだと言えるだろう。
さて、ここまで読んでくれた皆さんなら「あれ?画像生成AIって相当すごいんじゃね?」と少し思ってくれた人もいるだろう。そして実際、画像生成を活かしたビジネスの事例が国内だけでもすでに出てきているのだ。
これについては次回の記事で詳しく解説しよう。
この記事が気に入ったらサポートをしてみませんか?