Lean AI 開発論: コードを書く前に機械学習プロジェクトを評価する方法

10年前に提唱された「リーンスタートアップ」と呼ばれる事業立ち上げの手法がある。リーン(=無駄がない)であること、仮説検証の速度を最大化する(=学びの量に最適化する)ことを重要視する考え方だ。フィードバックサイクルを早め、コストをなるべくかけず、必要最低限の要素にフォーカスし、素早くスタートアップを立ち上げることで、成功確率が上がるのだと言われている。
裏を返せばこれは、仮説検証に必要ない一切は削ぎ落とすべきだ、と言っている。リーンスタートアップ的やり方の有名な例として、プロダクトを作る前に、そのプロダクトのランディングページだけを作って、メーリングリスト登録やアクセス数などの反応を見ることで、需要があるか確認するやり方がある。実はコードを書くのは初期の仮説検証に全く必要ないのだ。
このように進めれば、たくさんのお金と時間を使ってプロダクトを作って、ローンチしたあとに実は需要がなかった、と判明する悲劇は起きない。時間やお金を圧倒的に節約できる。逆に、需要があることがわかっていれば、より自信を持ってプロダクト作りに邁進できる。
リーンスタートアップの考え方はいろんな議論を呼んでいるが、この10年一つの指針となってきたことは間違いなく、多くのスタートアップがこのやり方を多かれ少なかれ取り入れている。
筆者はAI(機械学習)プロダクト/プロジェクトの領域でもこの考え方はもっと活かされるべきだと考えている。学習器のベースラインモデルの実験を回す前にやるべきこと、できることは実はたくさんあるにもかかわらず、それを怠っているAIプロジェクト、プロダクトが多いのではないか。機械学習系の業界に近いところにいたので、個人的に失敗例や成功例を色々目にしたことがあるが、下記にあげるような検証をしていれば防げた失敗も数多くあるように思う。この記事では私が思うAIプロジェクト/プロダクトにおいてコードを書く前にやっておくべきことについて紹介したい。
コードを書く前にできること:精度付加価値曲線の想像
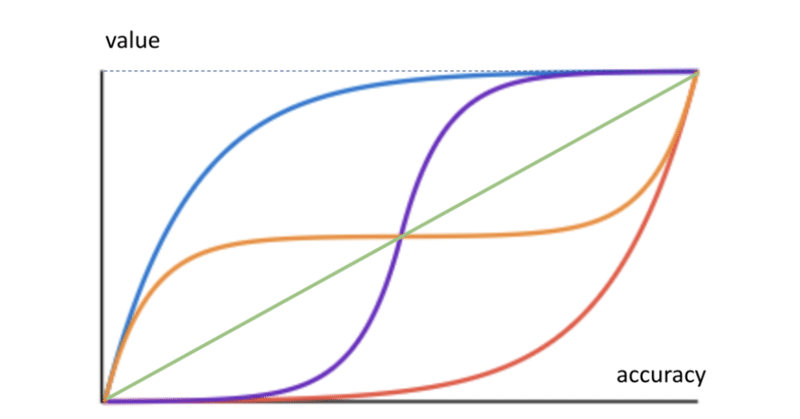
強くおすすめしたいのが、横軸に精度を、縦軸に「仮にその精度が達成されたとしてどれほどのビジネスバリューがあるか?」をマッピングした精度付加価値曲線を想像してみることである。AVC(Accuracy Value Curve)である。
基本的にAVCは右肩上がりの線になるはずである。精度が上がれば価値は上がるからだ。しかし、valueがどれだけ上に行くのか、そこに到達するためにどのような曲がりくねり方をするのかは問題設定によって変わってくるはずである。AVCを想像するときに、どこから取り組めばよいか難しいかもしれないが、特に下記の4つの点について考えるのが良いのではないかと思う。
考えるべき点①:Max Value
まずAVCを考える上で一番考えやすいポイントは、「精度がmaxだったときにどれくらい嬉しいか」(=max valueの大きさ)である。図でいうと右端のポイントにあたる。これは端的に言えば「仮に全知全能の100%正解が出力される学習器を手にした場合、どれだけビジネス的に嬉しいのか」ということを考える問題だ。この問題は「自動化によって誰のどの作業がどのくらい減るのか」からシンプルに計算できることが多い。
この工程は絶対にやるべきだ。筆者は昔、こんな苦い経験をしたことがある。nヶ月のプロジェクトの末、頑張って精度を出して自動化した作業が、あとからよくよくヒアリングして計算してみると年間でのべxx時間ぐらいしかかかっていないことが後から判明したのである。それ最初に計算しとけばよかったじゃん!と涙に暮れることとなった。意外にも、この種の間違いを犯しているケースは私だけではなく、いろいろなところで目にする。
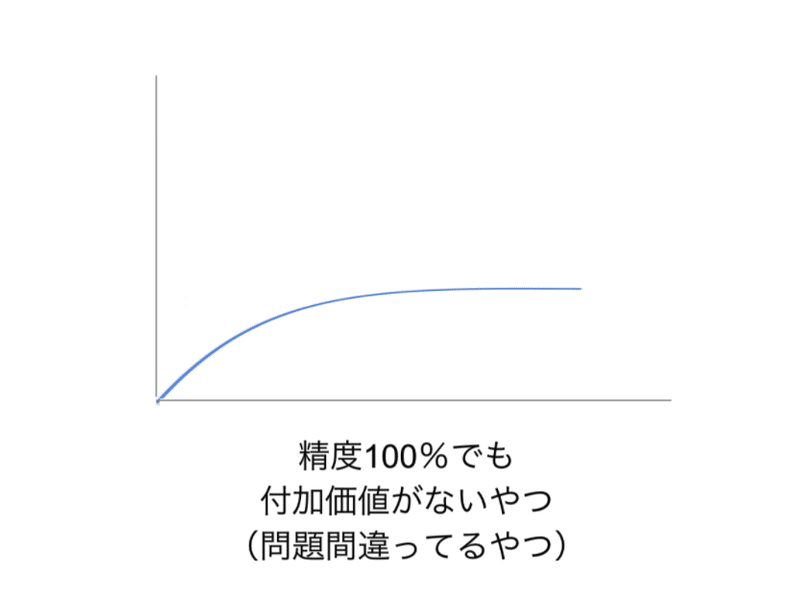
とにかく、こういう形のAVCには注意である。
考えるべき点②:MVA(Minimum Viable Accuracy)
次に考えるべきなのは、ミニマムでどのくらいの精度が出ると嬉しいのか、である。リーンスタートアップでいうところのMVP(Minimum Viable Product)ならぬMVA(Minimum Viable Accuracy)の見極めである。これも問題設定によってはコードを一行も書かずとも検証することができることがある。論理的に推定できる場合もあるし、特定精度を達成した時の結果のモックデータ、精度モックを作って気持ちを持つこともできる。
例えば架空の例として、コメント一覧から自動で攻撃的なコメントをフィルタして平和度をあげる掲示板的な機能を考えてみるとする。何%の精度を出せば最低限使えるものになるか、を知りたいが、理論的に推定できるようなものではない。しかしここで、xx%ぐらいの精度が達成された時の結果の画面を人為的に手で作ってみることは可能だ。そのデータを人間が評価して気持ちを持つことで、仮にPrecisionがxx%でRecallがxx%のモデルがあったとしたら嬉しいのか、がわかるのだ。MVAを知るためにコードを書く必要はない。精度モックを作ればいい。
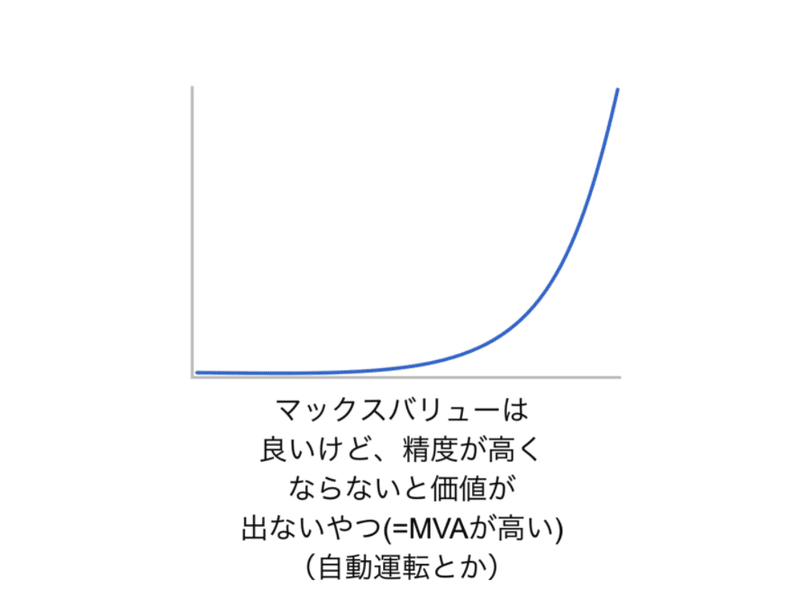
MVAについて考えることで、上図のような罠をふむことがなくなるのが良い点だ。マックスバリューは十分なのだが、最低限のバリューを発揮するために必要な精度がむちゃくちゃ高いようなケースだ。
考えるべき点③:人間の達成精度
同じ問題を人間が解いたときの達成精度である。これもコードを書く前から取れる数値である。シンプルに、まず自分でやってみて精度を測ればいいのだ。人間の達成精度は重要なベンチマークになりうる。AVCの形を大きく変えうる値だからだ。例えばある処理を自動化するときに、「人間がやっている精度と同程度」であれば機械に置き換えてしまってもいいよね、という理屈が成り立つことがある。置き換えてしまったらそのあとはあんまりビジネス的なバリューが変わらなかったりすることも多い。この時のAVCはシグモイド曲線のような形になりうる。
また、「人間の達成精度 < MVA」の時は要注意である。その問題設定で価値を出すためには人間超えをしなければいけないことが最初から見えているからだ。 人間にできないことを機械がやすやすとできる問題設定ももちろん中にはあるものの、あなたたちがいま機械学習で解こうとしている問題はそうではない可能性が高いのではないだろうか。
さらに、人間の達成精度の絶対値がすごく低い時も慎重になるべきだ。なぜならそれはルーレットの目の予測や株式市場の予測などと同様に、そもそも解けない問題である可能性があるからだ。
考えるべき点④:ベースラインモデルの精度
ここまできてからやっとコードを書き始めれば良い。今手元にあるデータセット、雑な手法で学習と評価のパイプラインを一周させるベースラインモデルの精度を測定してみる。これがMVAより高ければ万々歳だし、超えていなくても値が近ければ良いシグナルだ。データを増やし手法を磨けばそのモデルは価値を出しはじめる可能性が高いからだ。
AVCの中で気にするべき4つの点について紹介してきたが、これらを俯瞰的にみることで推察できることも多い。例えば私が関わっているMNTSQ社ではリーガル領域の問題解決を目指しているが、あるタスクにおいて上記4点の値はこんな感じの分布になっていた。
MVA < ベースラインモデルの精度 <<<< 人間の精度 < 100%(max value)
こんなケースはすごく筋が良さそうに見える。MVAは低く、ベースラインはすでにそれを上回っている。価値を出せることは明らかだ。人間の精度はすごく高く、論理的に達成不可能な問題ではないことがわかっている。max valueが高いから、精度をあげる努力のビジネス的な価値が高い。ぜひ他にもこんな問題領域を見つけた読者の方がいらっしゃったら、こっそり教えてくれると嬉しい。
(ご参考)
この記事が気に入ったらサポートをしてみませんか?