
AIで新聞の個性を可視化する「タイトル編(上)」(新聞書評の研究2019-2021)
はじめに
筆者は2017年11月にツイッターアカウント「新聞書評速報 汗牛充棟」を開設しました。全国紙5紙(読売、朝日、日経、毎日、産経=部数順)の書評に取り上げられた本を1冊ずつ、ひたすら呟いています。本稿では、2019年から2021年までに新聞掲載された総計約9300タイトルのデータを分析しています
なんでそんなことを始めたのかは総論をご覧ください。
過去の連載はこちらをご覧ください。
各新聞に、好きなタイトルがあるのか
さて、前回まで計9回にわたって、書評に取り上げられた回数と、書評に掲載された率が多かった出版社を紹介してきました。前回は掲載回数、掲載「率」とも多かった出版界の「イチロー」を探しました。
今回からは、新聞社ごとの特徴を見てみます。新聞社には特定のタイトル、特定の著者、特定の出版社に好き嫌いがあるのでしょうか。ワードクラウドを使って読み解いていきたいと思います。
まずはタイトルを比べます。各紙が書籍で取り上げた書籍のタイトルは、どの程度各紙の特徴を反映しているのでしょうか。
1000の名詞をワードクラウド化してみる
まずは、2019年から2021年の3年間に書評で取り上げられた約9300タイトル、重複紹介も含めると約12500の書評に出現した名詞のうち、頻度上位の1000ワードについて、新聞ごとにワードクラウド化します。
一つ一つの名詞について、5紙それぞれでの出現頻度とともに、5紙の出現頻度の差も勘案して重みづけを行っています。今回は全体像を示し、次回は各紙の差異に絞った分析を行います。(ので次回の方が面白いはずです)
技術的な補足①:
janomeで形態素解析を行い、名詞だけを取り出して、tf-idfで重み付けをした結果を、pythonライブラリのwordcloudで可視化しています
ワードクラウドとは、
文章中で出現頻度が高い単語を複数選び出し、その頻度に応じた大きさで図示する手法。ウェブページやブログなどに頻出する単語を自動的に並べることなどを指す。文字の大きさだけでなく、色、字体、向きに変化をつけることで、文章の内容をひと目で印象づけることができる。
出典 小学館デジタル大辞泉
です。では早速見てみましょう。
5紙の書籍タイトルワードクラウド

かなり似ている各紙のイメージ
同じような言葉が並んでいますね。ぱっとみてどの新聞がどのワードクラウドが判別つかないと思います。
平均値の読売新聞
読売新聞(左上)は、他のワードクラウドと比べて特別に目立つ単語はありません。まさに平均値だといえます。
それには恐らく理由があり、読売新聞の読書委員会は、
①同一の作家、著者の本は、原則1年に1冊しか紹介しない
②同じ紙面に同じ出版社の本は原則として重複掲載しない
③読書委員の著書は紹介しない
というルールで運用しているといいます。以下に詳しく書いてあります。
著者や出版社に偏りが出ない仕組みが担保されていることが、書評対象の書籍タイトルにもある程度反映されているのではないかと思います。
「世界」が先にくる朝日新聞
朝日新聞(右上)は「世界」の大きさが「日本」よりも大きい唯一の新聞です。実数では、「世界」の127回に対して「日本」は106回です。
ただし、使用したjanomeの内部辞書では、「世界」と、「別世界」「世界中」はそれぞれ別の単語として登録されています。また「日本」を含む単語では、「東日本」「日本語」「日本国」「日本人」が別の単語として扱われています。そこで、これらの単語も含めた「日本」グループと「世界」グループの単語数を新聞社ごとに比較してみます。

グループで見れば、朝日新聞も「日本」の方が多いのです。ただ、「世界」グループの1.1倍しかなく、他紙に比べると「世界」グループにデータ範囲を拡大しても、その比率が大きいことがわかります。
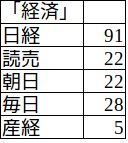
「経済」は当然、日経新聞
日経新聞(左中)は、左上にかなり大きく「経済」が出てきます。経済新聞ですから、なんの不思議もないですね。頻度は以下の通りで、他紙を圧倒しています。「週刊エコノミスト」を発行する毎日も「経済」は多く、ワードクラウドにも反映されています。なお「経済」には別扱いの単語はありません。
「戦争」が目立つ毎日新聞
毎日新聞(右中)は、左上に「戦争」の文字が目立ちます。「太平洋戦争」「南北戦争」は別の単語として認識されていますので、前例に倣って、「戦争グループ」で表を作ります。

毎日新聞の実数は、産経以外の他紙より少ないです。ではなぜ、大きな活字となったのかは、「戦争グループ」を総書評数で割り戻した最右欄を見るとわかります。
そもそも毎日新聞は総書評数が少ないので、絶対数が少なくても比率としては大きいのでした。
技術的な補足②:
今回単語の重み付けに活用したtf-idfという手法は、
「特定の文章に占める当該単語の出現比率」と「それぞれの文書に占める当該単語の出現比率の差」の両方を考慮して重み付けをします。
複数の文書を比較する場合、ある文書の特徴は、
①その文書に頻出する単語
②その文書に頻出して、他の文書には頻出しない単語
の2つで示されるという考え方です。
毎日新聞の「戦争」の説明は①に対応し、朝日新聞の「世界」グループの説明は②に対応しています。(グループ内の「世界」以外の単語はクラウドに反映されていませんが、考え方の説明にはなっています)
こちらも平均値・産経新聞
産経新聞(左下)も読売新聞と似ていて、突出した単語が見当たらないです。
ただ、別の手法を用いて分析すると、産経にはかなり特徴的なタイトルの書籍が多いことがわかります。数が少ないので、全体像を示すワードクラウドには上がってこないのですが、それは次回に。
ワードクラウドが似ている理由
一瞥してわかる通り、新聞各紙が書評で扱った書籍のタイトルはかなりの程度、共通の傾向を示しています。これは、書籍を選択するに当たっての書評子の関心のあり方、傾向がかなりの部分で共通していることを示しています。だからこそ、複数の新聞に取り上げられる書籍がでてくるわけです。
そこで、それがどの程度かを、試みに数値化してみます。主成分分析という手法を使いました。
対象としたのは、5紙に共通して出てくる名詞の頻度上位200ワードです。5系列×200ワードの延べ計1000のデータを組み替えて、できる限り情報量の大きい別の系列を作る作業になります。
例えば、自動車の写真を撮影するときは、通常は前方斜め上から撮ります。その方が情報量が多くなり、特徴が一番わかり易いからです。ただ、正確な寸法を知るためには、正面や真上、真後ろ、左右の側面からの情報が必要です。
主成分分析とは、この寸法の情報から、最も情報が多くなる撮影軸(前方斜め上)を逆算する手法です(専門家ではありませんが、そう理解しています)。
今回のケースでは、情報量が最大となる軸(第一主成分)の情報の集約率(寄与率)は0.8952でした。情報の約90%は一つの軸で説明できるということになります。自動車でいえば、寸法情報の9割を写真に収められる軸があるということです。
残った情報をさらに集約していくと、第2主成分は約5%、第3、第4主成分はともに約2%程度、第5主成分は1%でした。(当然、全部で100%になります)
もともとの情報量は、5紙それぞれ20%ずつですが、これをぎゅっと集約したら、その9割が一つの別系列にまとめられたということです。
書籍の9割がたは共通の物差しで選択されており、新聞社ごとの特徴は残りの10%の部分に現れていることを、試算は示唆しています(専門家ではありませんが、そう理解しています)。
この記事が気に入ったらサポートをしてみませんか?