
2020-03-31 Google Cloud Data Platform Day #2 #gc_dpday

2020/03/31 に開催された Google Cloud Data Platform Day #2 のイベントレポートです。
●イベント概要
ビジネスの成長を加速させるクラウド型データ分析プラット フォームとは
企業におけるデータ活用が進む中、データマネジメント、データ分析を支える分析基盤は重要になっています。Google Cloud はフルマネージドで実績のあるデータ分析プロダクト(BigQuery、Cloud Dataproc、Cloud Dataflow など)や、サーバーレスのアプローチでデータ分析基盤の複雑な運用をなくし、ビジネス上の重要な意思決定を迅速かつ効率的に行うことができるプラットフォームを提供しています。
本セミナーでは、データプラットホームとしてオンプレやクラウドをご利用中のお客様に、これからの Data Warehouse、Data Lake、Stream Analytics のあるべき姿をご紹介します。また実際に データ分析基盤として Google Cloud をご利用になっているユーザー様にご登壇いただき、選定、導入のポイント、いまどのようにお使いになっているかについてお話しいただきます。
■Google Cloud スマート アナリティクス ソリューションの最新情報
吉田 啓二 さん [ グーグル・クラウド・ジャパン ]

●スマートアナリティクスソリューション
・データウェアハウスモダナイゼーション
・データレイクモダナイゼーション
・ストリームアナリティクス

●データウェアハウスモダナイゼーション
・BigQueryを中心にデータウェアハウスを構築
マネージドでスケーラブルに

●BigQuery Reservations
・スロットを購入、ワークロードに予約、割り当て
・コミットメントの種類
flex
60秒後から解約できる
一時的にクエリが集中する場合
月間
30日から解約できる
年間
365日から解約できる
定常的に稼働しているワークロード
・メリット
コストが予約できる
画面上ですぐにスロットの購入、割り当て
未使用のスロットを組織内で有効活用
●整数範囲パーティショニング
・整数型のカラムの値の範囲でパーティショニング
クエリのスキャン対象をパーティションで分けられる

・クラスタリングとの併用
クエリのスキャン対象をパーティションとブロックで絞り込める

●DMLの実行回数の無制限化
・DMLをキューイング、制限をチェックして実行
・同時実行失敗のリトライは自動化
・CDCも実現できるようになった
●INFORMATION_SCHEMA
・組織全体のメタデータを見えるようになった
・監査、モニタリングに
誰がどんなクエリを発行しているのかなど

●カラム単位でのデータアクセス制御
・タグとIAMを紐付け
・カラムとタグを紐付け
●データレイク

●Cloud Dataproc 自動スケーリング
・YARNメモリベースでスケール
・プライマリ、セカンダリどちらも
●Cloud Dataproc GKEでSparkジョブの実行
・dataproc-spark-operator
・spark clusterでのライブラリの依存管理をコンテナに委譲
●Cloud Dataproc 各種リソース
・DeltaLakeも対応

●BigQuery GCSのHiveパーティションデータのロード
・これまでは、パーティションキーバリューが欠落していた
BigQuery
パーティションキーバリューをテーブルに含める
Hive
パーティションキーバリューをテーブルに含めない
●BigQuery GCSのHiveパーティションデータの検索
●BigQuery Storage API
・直接データを読み込む
・複数ストリームで並走できる
●ストリームアナリティクス

・リアルタイムダッシュボード

●Dataflow SQL
・java, pythonで開発
→ SQLでストリーミング、バッチ
・対応サービス: Cloud Pub/Sub, BigQuery, Cloud Storage
・ウィンドウ集計: fixed, slidinng, session
●FlexRS
・一部のワーカーでプリエンプティブVMを利用できる
・max 6時間待ち
・Dataflow shuffle serviceにオフロードしてワーカーはデータを保持しない
■顧客理解を深化させるために:バンダイナムコエンターテインメントが活用するデータ統合・分析プラットフォーム
田村 雄也 さん [ バンダイナムコエンターテインメント ]
田中 大樹 さん [ バンダイナムコエンターテインメント ]

●バンダイナムコグループ
・世界で最も期待されるエンターテインメント企業グループ
・5つのユニット
トイホビー
ネットワークエンターテインメント
バンダイナムコエンターテインメント
リアルエンターテインメント
映像音楽プロデュース
IPクリエイション
●バンダイナムコエンターテインメント
・ビジネスモデルの一例

・重点戦略
2000億円がネットワークコンテンツ
1000億円が家庭用ゲーム
●データ戦略
・IPの価値を立体的に表現して最大化

・データを活用して市場規模を拡大
IPに関心を持っているお客様に対して
届けられているお客様の数はまだまだ
・取り得るデータを活用して
お客様の嗜好にあった価値を届ける
●データのサイロ化
・サービスごと、デバイスごとにデータがサイロ化

●取得データの未活用
・データをとっても担当者の、正しさの証明だけだったり
・データを取っていなかったり
もっと顧客起点に→BigQueryの活用へ
●全体アーキテクチャ
・ほとんどがGCPで完結
出口は、lookerや独自の可視化ツール

●導入の背景 ビジネス視点
・Amazon Redshiftを使っていた
・課題
ストレージコスト
パフォーマンス
●導入の背景 分析者視点
・SQLの書き方が一般的でなかった頃は、見送っていた
・標準SQLに対応
集計・分析作業がしやすい
●あらゆるデータを蓄積、BQで処理・分析
・アプリ、web、EC
→顧客DB
・アンケート、お問い合わせ、SNS
→顧客DB

●メリット
・早い
・安い
・使いやすい
●早い
・数秒で数十億レコードをフルスキャン
・パフォーマンスを気にせず、データに集中できる
・データから検証していくことが可能に
・2016年の速度検証
並列で処理が流れても、速度にほとんど影響しない

●コストが低い
・BigQueryとStorageを合わせたものを100として
・ストレージよりクエリにかかる料金の方が安い!
looker組み込み、アナリストの分析で頻繁に使っているのに
・利用分だけ課金
クエリの工夫で削減できる
・LongTermStorageで割引も聞く
・クエリ 5$/TB
同じクエリはキャッシュが効く
予めスキャン量を確認できる
・Tips
Common Table Expressions
with句で読みやすさを保持
中間データは課金対象にならない
●使いやすい
・パフォーマンスチューニングを気にしなくて良い
インデックス、ソートキー、保存場所がBQ側でやってくれる
とりあえず貯めてから分析ができる
・膨大なデータを扱える
2PBのデータを申請無しで登録できた
・プロジェクトごとに権限、費用管理できる
・プロジェクトをまたいでJoinできる
・多少非効率なクエリでも問題ない速度が出る
・一般的なBIツールをサポートしている
民主化しやすい
・Datasetの上位概念がほしい
Project / Dataset / Table の階層
・データカタログとしての一覧性があまりない
データが多いので把握しづらい
Data Catalogを整備はしているが、UIに課題
●今後の展望
・BigQuery ML
データは揃っているので使っていきたい
詳しくない人が触れるように
・BigQuery GIS
位置情報もビジネスに絡めていきたい
■CDP / マーケティング DWH のトレンドと Google Cloud での実現方法
原田 憲悟 さん [ エクスチュア ]
鈴木 邦明 さん [ グーグル・クラウド・ジャパン ]

●CDPが求められる背景とその機能
・カスタマージャーニー
商品を知ってから購入に至るまではどんどん複雑に
気になったらスマートデバイスで調べて
口コミやECを調べたり
実店舗で使用感を試したり
タッチポイントが増え、行動が複雑化
いろいろなデータが取得できるようになっている
・自分の要望に基づく対応に期待 61%
・購入履歴からパーソナライズされたエクスペリエンスに期待 63%
・期待はどんどん引き上げられている
消費者が何を求めているのかを把握して対応していく必要がある
・社内のあちこちに分散した顧客データ
分析に活用できている企業は 13%
・マーケティングに関連するデータ
コンテンツマーケ、CRM、広告
ロイヤリティ、webやアプリの分析、SNS
これらをつなぐ必要がある
●CDPの機能
・データ収集・管理
・ID統合
・複雑な分析
・施策実施
→複数の製品が存在

●Googleでは単一のパッケージは提供していない
・Google Cloud + Google Marketing Platform
サービス群を組み合わせる
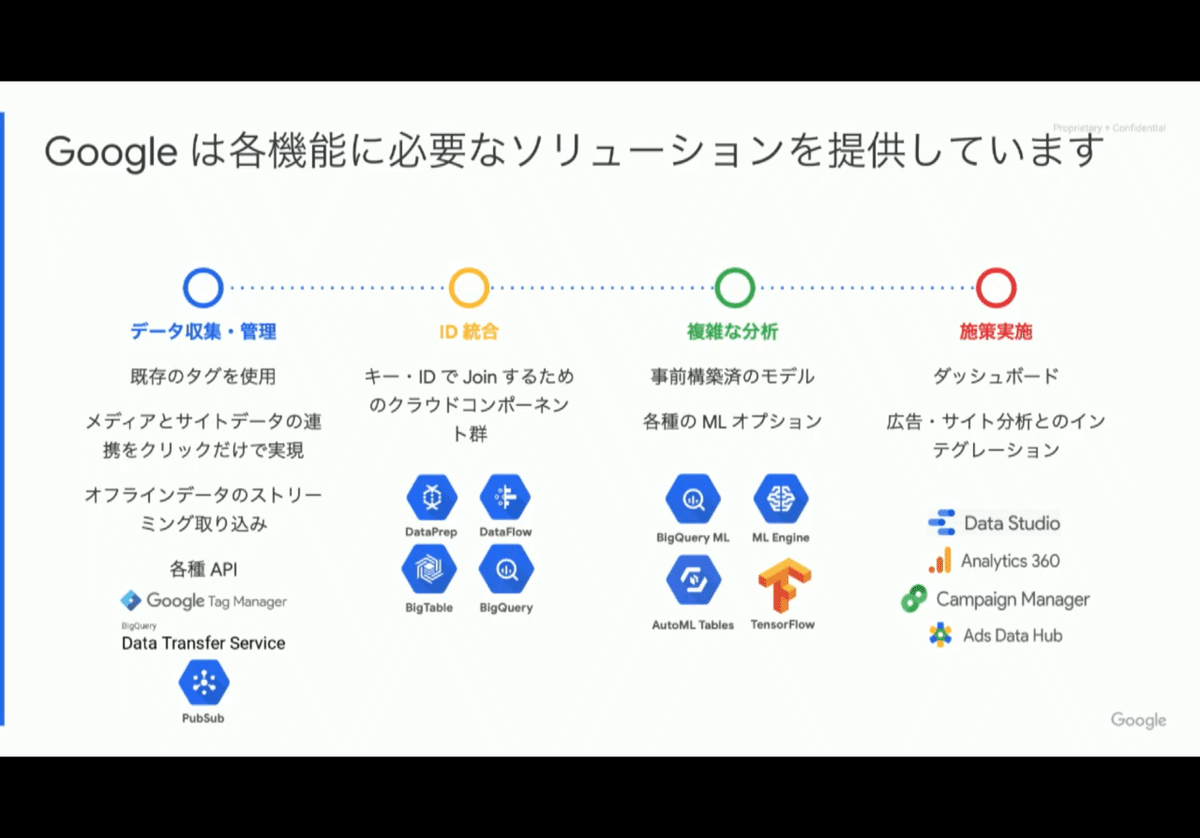
・基幹データ、マーケティングデータ
→BigQuery
→マーケティング施策

●既存CDPとの比較
・既存CDP製品
ワンパッケージ
長いリードタイム
webサイトにタグを埋めて、半年運用して分析開始
データの拡張性に制限あり
契約形態がレコード数に依存する
パフォーマンスが対応しきれず、絞ったり
・Googleの提供機能で実現
必要なコンポーネントを取捨選択
短いリードタイム
GoogleAnalyticsやTagManagerなど既存資産を活用
●世界全体のデータ量は増加し続ける
・大量のマーケティングデータを処理できるBigQuery
・BigQueryパフォーマンスの進化
1PBのテーブルスキャン
2016年 245.7 sec
2018年 113.0 sec
2019年 4.2 sec
●移行事例:MonotaRO
・データドリブンな施策で有名
・他社製の製品を試した結果BigQueryに乗り換え
事前に調査してから対応が必要だった
なんでもデータを投げ込むデータレイク的な使い方ができなかった
→あらゆるデータを集約
・迅速な分析・改善ができるようにあった
月次集計→日次
バッチ→リアルタイム
・セルフサービス分析が浸透
ビジネスで分析の成果が社内に広まった
DataPortalなどでの利用の広がり
ビジネスプラットフォームとして活用
●エクスチュア
・Googleのサービスパートナー
・データに関するよろずや
・手を動かすコンサル会社
●改めてCDPとは
・Customer Data Platform
顧客データを統合管理して、利活用できるようにするプラットフォーム
活用することが重要
つくるところに工数がかかるので、目が向きがち
その後の活用を忘れないように
・世の中にあるCDPの例
Tealium
Treasure Data
Segment
mParticle
Adobe Experience Platform
など
・CDP製品は何をやってくれるの?
複数データソースからデータをインポート
集めたデータを名寄せ
指定した条件に合わせてユーザ分類をつくる
指定した外部システムにセグメントを共有
集めたデータを可視化、分析
●既製品 vs GCPでCDP のPros/Cons
・データインポート
既製品のほうが楽
コネクタが用意されている
コネクタがないソースはフルスクラッチは同じ
必要なコネクタがマッチするか?
・データ処理
BQが早い
スピードに問題があることも
BQで分析して書き戻したことも
・データ分析
BQでSQLからBIにつなぐ
既製品はおまけな機能
・コスト
開発コストは掛かるが、運用フェーズに入った後はGCPの方が安い
●導入の壁
・名寄せの設計
CDPに入ってくるwebのデータは、1:1でIDが紐付かない
Aさん
PC、スマホで別のメアド
デバイスが変わればGAのcidが変わる
twitterの裏アカウント
オフラインのキャンペーン応募
・ITP/SameSite対応
CDPが提供しているタグ
ITP/SameSiteに対応していなかったらデータがまともに取れない
リピートなど
既製品でもITP対応が遅かったことも
自作でタグをつくってしまうことが手っ取り早い
・セキュリティ、プライバシーポリシー
データを触れる人の権限設定
他社のCDPを利用する場合、他社側でどう使われているか
オプトアウトやデータ削除に対応できるか
既製品を使っていたとしても、免罪符にはならない
●現場からもろもろ
・何のためにCDPを入れるのか?
製品を買う?GCPでつくる?そもそも不要?
・開発できるならGCPでつくった方が楽
・データソースがぐちゃぐちゃだったら意味がない
・開発保守は、結構負荷がかかる
・有効活用するためには消費者目線で、気持ち悪いことはしない
データを用いて良い顧客体験をつくっていきましょう
■GCP で構築する、これからの変化に対応出来るデータ分析基盤の作り方
山田 雄 さん [ リクルートテクノロジーズ ]
佐伯 嘉康 さん [ リクルートテクノロジーズ ]
白鳥 昇治 さん [ リクルートテクノロジーズ ]

●データ分析基盤のデザインパターン
・80%
基盤エンジニアが運用に割いている割合
開発に工数は割けない
これをいかに削減できるか
・なぜそれほど時間がかかる?
Scalability
90%を意識した基盤設計
データ量は指数関数的に増えている
Microservices
データソース→取得→加工→保存→分析→BI、施策
個別にエンハンスできるように過程を分けてつくっておく

分析ユーザ主体
データ取得以降の過程を、分析ユーザができるような基盤
エンジニアを介さずに
データソース追加や新規クエリの定期実行登録など
・番外編
基盤は一度できると使えることが当たり前
水道ができたときは感動があったはず
出て当たり前
止まったときにはストレス
基盤エンジニアのモチベーションコントロールはとても重要
●リクルートのETL課題
・SPOFが残っている
・オンプレなのでスケール限界
・シェルが残っている など
→リプレースへ
●Garuda
・ETL基盤
本番プロダクトのデータを分析環境へつなぐ
Pub/Subに通知して、分析者へ
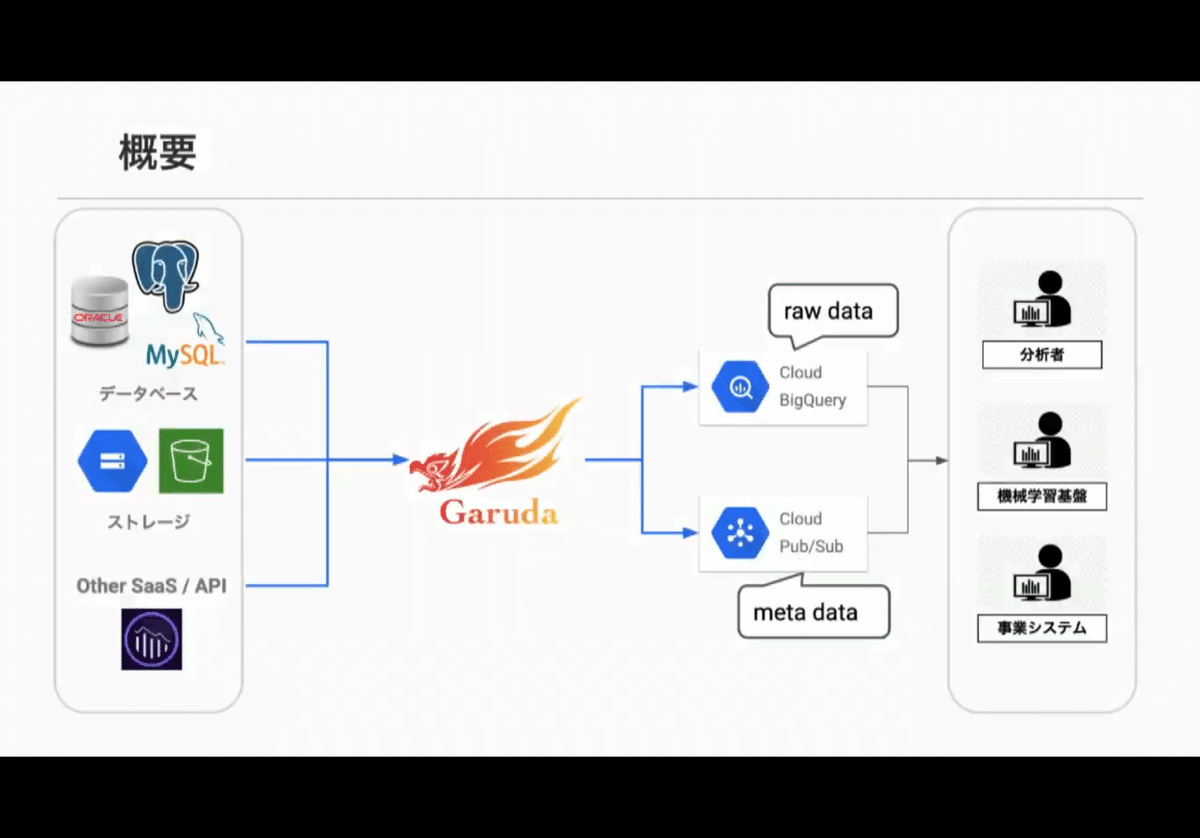
・ETL要件
Oracle / MyuSQL / Postgres
S3 / GCS
Salesforce / Kintone
・ETLジョブ
DBへの同時接続数を制御したい
本番環境に影響をださない
データ鮮度を保ちたいジョブがある
多数のジョブ
いつ終わるかわからないでは問題
優先度を管理
ETL時間を短くしたい
・アーキテクチャ

●ETL on GKE
・ETL処理をコンテナでパーツ化
・ワークフロー管理ジョブでコンテナ実行を制御
・オーケストレーションとリトライをk8sに任せる
・GCSをfileでハブにすることで処理しやすく

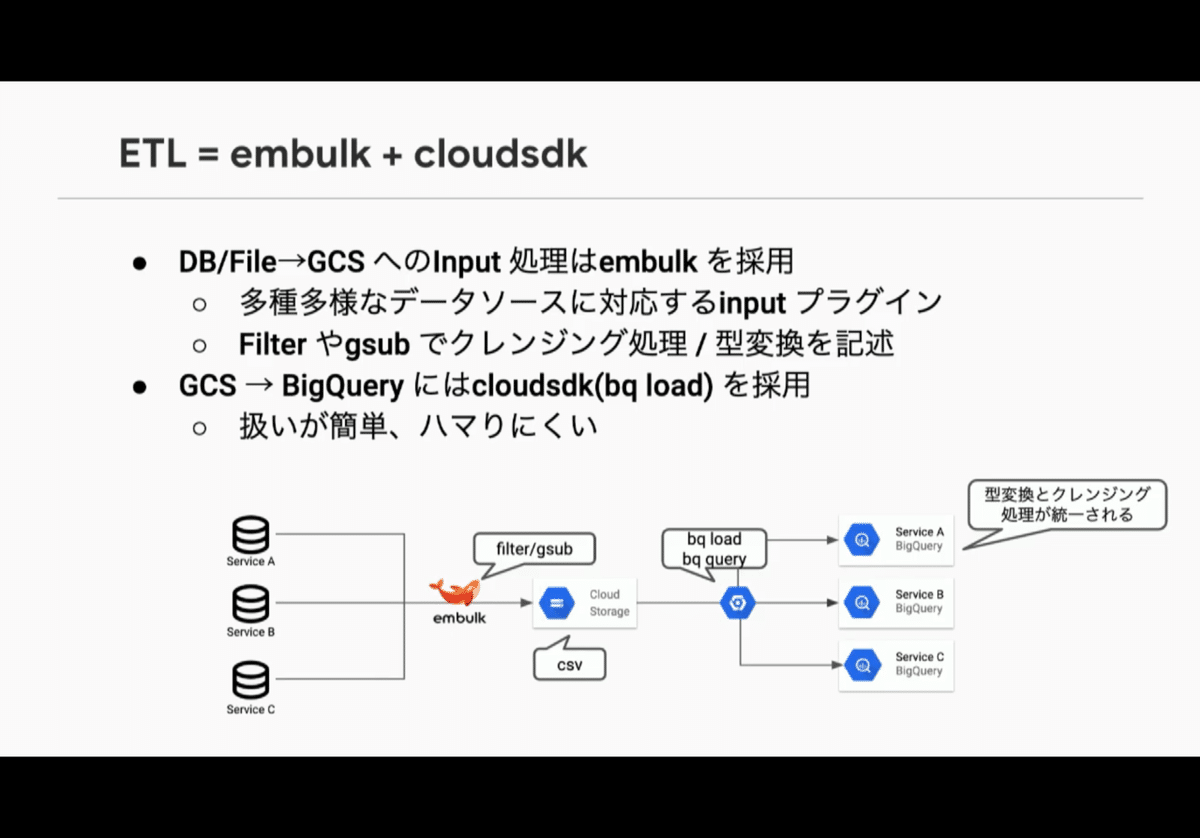
・ETL = embulk + cloudsdk
input pluginが多数
filterでクレンジング、型変換を共通化
bq loadでシンプルに
●データ更新方式
・全レコードを洗替
・全レコードを連携日付のパーティションとして積み上げ
更新のあるテーブルの日付断面で履歴を検索したい
・更新日付キー + 主キー で差分更新
予約、在庫などのトランザクションテーブル
データ連携を早くする必要がある

・日付パーティションによる差分更新
レコード更新のないログテーブル

●ETLジョブの実行管理
・要件
並列度を制御したい
優先度が高いものから実行したい
・k8s cronjobに変換
・優先度別にpubsubキュー
・ディスパッチャーpodが優先度順にキューとステータスを見て、並列数を見てk8s job起動
・ジョブステータスはDB管理、ディスパッチャーやk8s jobから書き込み

●ネットワーク
・専用線とCloudVPNでつなぐ
k8s でぽこぽこ立てるとprivate IPが枯渇
・接続とジョブでVPCを分離 + 内部NAT
●API / WebApp
・ETLの設定を抽象化してセルフサービス化
ジョブの設定、実行、停止
embulkの設定
APIを変えなければ、裏は変更できる
・板挟みの役割をシステムに
●コストの話
・ほぼGCE、GCS
GCEはジョブ数で変動
GCSは生データ
・監視が影響を与えた
すべてStackdriverに流そうとしていた
ジョブの観点をkube-state-metricsで
→ stackdriver custom metricsが多数に

Pricing Calculatorでチェックしよう
最終的にcustom metricsは廃止
prometheus、linkerdでGKEのストレージ側に変更
・ストレージコストも無視できない
emblkの出力はCSV
GKEのストレージ節約で、Embulk→GCS
stdin/out を経由して gsutil cp で
●ログの話
・実装コンポーネントが多数
→ログ書式がバラバラ
致命的ではないので後回し
●BigQueryロード仕様
・bq load の --allow_quoted_newlines があると4GBが上限になることも
・Embulkではstdoutに出すだけ
・パイプのプログラムで制御
CSV完結
4GBに近づいている
gsutils を閉じて、開き直す
●まとめ
・マネージドなサービス、OSSで開発工数削減
・「必要なリソースを必要な分だけ」の追求で圧倒的なコストダウン
・API / WebUI でセルフサービス運用
■感想
1PBのスキャンが4.2秒、頻繁な分析を掛けてもクエリコストがストレージコストより安い、標準SQL、BI連携、2PBでも緩和申請不要。よく聞いてはいましたが、BigQueryの速い、安い、使いやすいに改めて驚きました!
リードタイム、コストのバランスを考えて、CDPは製品を買うのが妥当なのかなと考えていましたが、BigQueryの圧倒的な速さ、安さ、使いやすさに支えられて自作や、製品との組み合わせが現実的になっているんですね!
データパイプラインをweb UIとAPIでセルフサービス化、パイプライン内の処理をkubernetes CronJobでつけ外しできるようにするアーキテクチャ、すてきな発想ですね!
たくさんの学びをいただけました。登壇者の皆さん、運営の皆さん、ありがとうございました!
この記事が参加している募集
いつも応援していただいている皆さん支えられています。